De acordo com pt.wedoany.com-Em 1º de junho, a empresa chinesa de Inteligência Artificial MiniMax lançou seu novo modelo de uso geral, o MiniMax M3. Baseado na arquitetura proprietária MiniMax Sparse Attention, a API suporta uma janela de contexto de até 1M tokens, garantindo pelo menos 512K tokens utilizáveis, com foco em agentes de longa duração, tarefas complexas de código e aplicações multimodais nativas.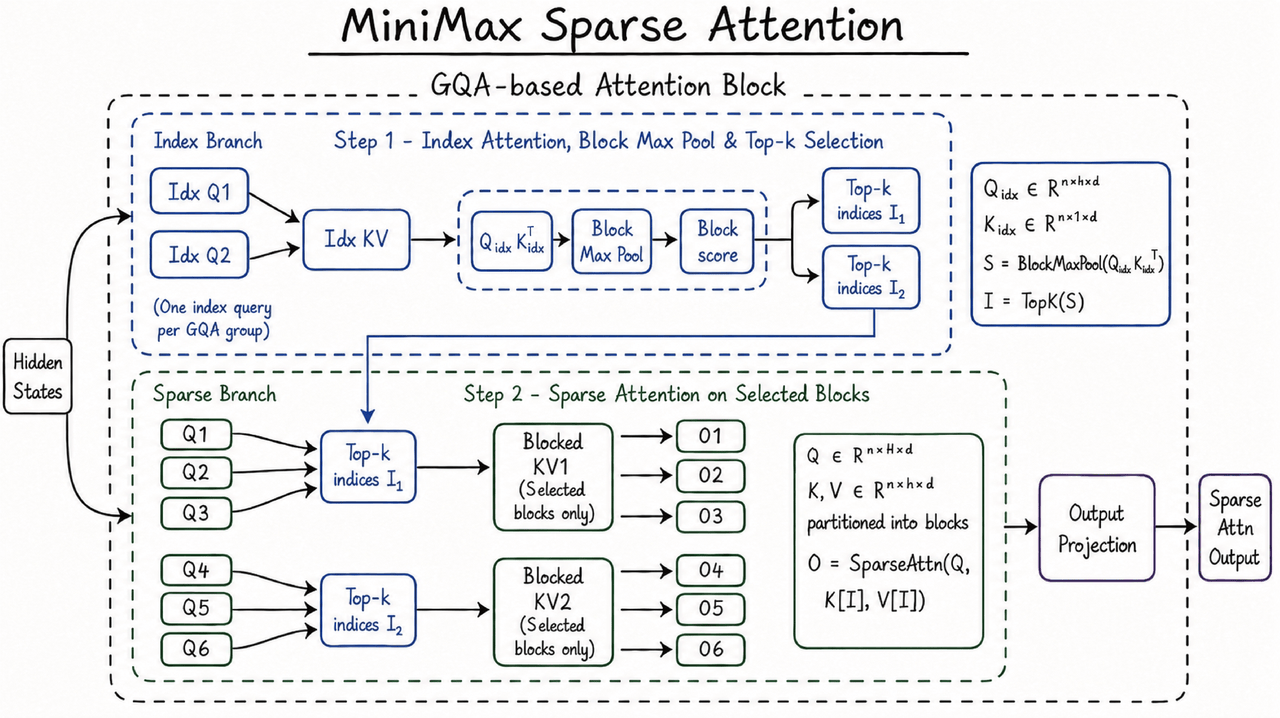
A principal mudança do MiniMax M3 está na evolução da capacidade de contexto longo, que passa de um "indicador de parâmetro" para um "suporte de tarefas de engenharia". Com a entrada dos grandes modelos de linguagem na fase de agentes, eles precisam lidar não mais apenas com perguntas e respostas únicas ou geração de texto curto, mas com tarefas de longa duração que entrelaçam repositórios de código, documentação de produtos, logs de tarefas, registros de chamadas de ferramentas, imagens e informações de vídeo. Uma janela de contexto de 1M tokens significa que o MiniMax M3 pode reter mais informações upstream e downstream em uma única cadeia de tarefas, reduzindo a perda de informações causada por truncamentos frequentes, sumarizações repetidas e recuperação externa. Para cenários como desenvolvimento de software, reprodução de pesquisas científicas, perguntas e respostas em bases de conhecimento empresarial, compreensão de vídeos longos e automação de escritório complexa, o contexto longo está se tornando uma capacidade fundamental para que os modelos possam entrar de forma estável nos fluxos de produção.
O suporte para essa capacidade vem da arquitetura MiniMax Sparse Attention, desenvolvida internamente pela MiniMax. Mecanismos de atenção total tradicionais enfrentam um rápido aumento no custo computacional à medida que o comprimento do contexto se expande. A MSA melhora a eficiência computacional em contextos longos por meio da atenção esparsa, permitindo que o MiniMax M3 mantenha um desempenho de inferência viável em janelas de contexto de milhões. De acordo com informações oficiais, com um comprimento de contexto de 1 milhão, o custo computacional por token do M3 é cerca de 1/20 do modelo anterior, a velocidade na fase de pré-preenchimento é mais de 9 vezes maior e a velocidade na fase de decodificação é mais de 15 vezes maior. Para desenvolvedores e usuários empresariais, essas mudanças de eficiência impactam diretamente o custo da API, a velocidade de resposta e a capacidade de execução contínua de tarefas longas, determinando também se o MiniMax M3 pode sair de cenários de demonstração para chamadas de negócios de maior frequência.
O MiniMax M3 também enfatiza as capacidades de codificação e de agente. Tarefas de engenharia de software já se tornaram um cenário chave na competição de capacidades de grandes modelos, pois o fluxo de desenvolvimento real geralmente inclui esclarecimento de requisitos, modificação de código, feedback de testes, chamadas de ferramentas, iteração de versões e colaboração em múltiplas rodadas. A MiniMax divulgou que o M3 obteve pontuações elevadas em avaliações como SWE-Bench Pro, Terminal-Bench 2.1, KernelBench Hard e MCP Atlas, e treinou o modelo para se adaptar a cenários de colaboração contínua por meio de uma estrutura de simulação de usuários. Essa direção mostra que o MiniMax M3 não se concentra apenas em melhorar a capacidade de "escrever um trecho de código", mas tenta cobrir toda a cadeia de desenvolvimento, desde a decomposição de tarefas, execução, verificação até a correção repetida.
A multimodalidade é também uma das principais capacidades do MiniMax M3. O modelo incorpora dados multimodais desde o início do treinamento, permitindo que texto, imagens e informações de vídeo sejam processados de forma coordenada em uma única tarefa. Em casos oficiais, o MiniMax M3 é usado em tarefas de longa duração, como reprodução de artigos de pesquisa, otimização de operadores CUDA e automação de fluxos de treinamento de modelos, demonstrando o valor combinado de contexto longo, capacidade de codificação, chamadas de ferramentas e compreensão multimodal. Para aplicações empresariais de IA, essa combinação de capacidades significa que o modelo pode simultaneamente ler documentos, entender gráficos, analisar logs, gerar código e chamar ferramentas, expandindo os limites das aplicações de agentes de "capacidades pontuais" para "execução entre etapas".
O lançamento do MiniMax M3 também reflete que a competição de grandes modelos na China está mudando de meros parâmetros de modelo, preços e experiência de diálogo geral, para capacidades mais próximas do ambiente de produção, como contexto longo, execução de agentes, engenharia de código e fusão multimodal. À medida que as empresas integram grandes modelos em processos de P&D, operações, atendimento ao cliente, escritório e gestão de conhecimento, os fornecedores de modelos precisam resolver simultaneamente questões de desempenho, custo, capacidade de contexto, estabilidade e ecossistema de ferramentas. O investimento do MiniMax M3 em contexto de milhões e na arquitetura MSA indica que agentes de tarefas longas estão se tornando um novo foco de competição para a comercialização de grandes modelos.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com