De acordo com pt.wedoany.com-O Google publicou recentemente um artigo técnico explicando como a ascensão da IA está remodelando sua arquitetura de rede. O artigo aponta que, à medida que serviços como Gemini, Veo, Pesquisa e Cloud AI dependem cada vez mais de sistemas de rede integrados e compactos, projetados para tráfego leste-oeste em larga escala, baixa latência e alta resiliência, a rede se tornou a camada fundamental do próprio sistema de IA. Amin Vahdat descreve essa transformação em detalhes no artigo.
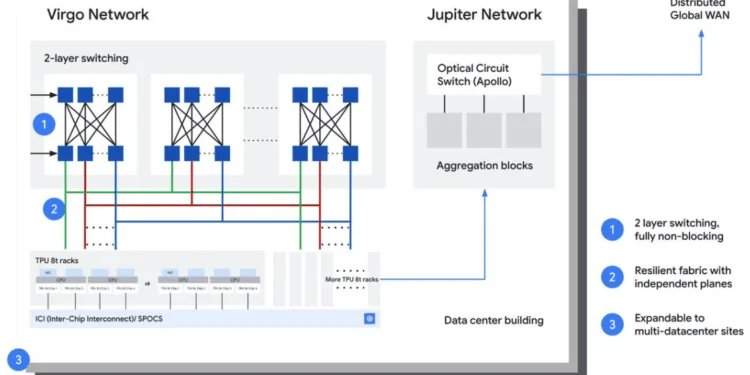
Atualmente, o Google considera a infraestrutura de IA como uma plataforma de computação distribuída sem precedentes. As cargas de trabalho de treinamento e inferência estão se estendendo por vários clusters, edifícios e até campi, exigindo a transmissão de grandes volumes de dados com latência previsível por meio de estruturas interconectadas. O Google descreve uma arquitetura que integra recursos em diferentes locais, formando o que chama de "supercomputador" de IA em larga escala. Isso requer uma coordenação estreita entre redes de cluster, transmissão óptica regional e redes de longa distância globais. A rede privada de backbone do Google já cobre mais de 7,75 milhões de quilômetros de sistemas de cabos terrestres e submarinos, alcançando mais de 200 países e regiões para suportar cargas de trabalho de IA distribuídas globalmente.
O artigo aponta que a IA está confundindo as fronteiras tradicionais entre redes de datacenter e redes de longa distância. Historicamente, as estruturas de datacenter eram otimizadas para tráfego leste-oeste de curta distância dentro de edifícios, enquanto as redes de longa distância lidavam com conexões de longa distância entre regiões. Hoje, o treinamento de grandes modelos gera tráfego síncrono entre milhares de aceleradores, muitas vezes ultrapassando um único POD ou campus, o que exige que a expansão de largura de banda, o gerenciamento de congestionamento, o planejamento de capacidade óptica e a engenharia de tráfego operem como um sistema unificado. O Google vê isso como uma convergência arquitetônica entre comutação, roteamento, transmissão óptica e controle definido por software.
O software desempenha um papel fundamental na orquestração dessas redes. O Google destaca que a alocação de cargas de trabalho de IA depende cada vez mais do gerenciamento inteligente de tráfego em várias camadas de infraestrutura. Redes definidas por software são usadas para equilibrar o tráfego, isolar falhas, otimizar a latência e alocar dinamicamente a capacidade entre cargas de trabalho concorrentes. Isso é particularmente importante para o treinamento distribuído em larga escala, pois o link mais lento em um cluster síncrono pode afetar o desempenho geral do modelo. O plano de controle de rede do Google está cada vez mais atuando como uma camada de orquestração entre computação e transmissão.
O artigo também enfatiza a importância da inovação em hardware nas redes de IA. O Google menciona investimentos em chips de rede personalizados, aceleração de hardware e tecnologias de acesso direto à memória para minimizar a latência e aumentar a taxa de transferência entre recursos computacionais. Isso está alinhado com a tendência dos provedores de nuvem em hiperescala em direção a redes baseadas em RDMA, estruturas de expansão óptica e arquiteturas de comutação de alta fan-out projetadas especificamente para clusters de IA. O conteúdo do artigo permanece no nível do sistema, sem entrar em detalhes específicos de produtos, mas reflete a mudança na indústria em direção ao co-design de redes com aceleradores, sistemas de memória e armazenamento.
A arquitetura do Google está alinhada com seu plano mais amplo de supercomputador de IA, incluindo a estrutura de expansão Virgo lançada no Cloud Next. Essa plataforma conecta recursos de TPU e GPU em larga escala e permite que cargas de trabalho sejam distribuídas entre datacenters. Abordagens semelhantes também são vistas na indústria, incluindo o NVLink da NVIDIA e as estruturas de IA baseadas em InfiniBand, as redes de clusters de IA em larga escala da Meta, o backbone de IA do Azure da Microsoft e o trabalho da AWS com EFA e redes ópticas personalizadas. A contribuição do Google demonstra como esses conceitos podem se estender de clusters para infraestrutura metropolitana e global.
As principais informações do artigo incluem: o Google posiciona a rede como um componente arquitetônico central dos sistemas de IA, e não como uma camada de transporte de suporte; as cargas de trabalho de IA estão cada vez mais operando em vários clusters e campi, exigindo interconexões de altíssima capacidade; à medida que o alcance geográfico do tráfego leste-oeste de IA se expande, a separação tradicional entre estruturas de datacenter e arquiteturas de rede de longa distância está diminuindo; o Google depende de engenharia de tráfego definida por software para otimizar o desempenho e a alocação de cargas de trabalho entre camadas de rede; a resiliência da rede continua sendo central, com diversidade de roteamento e isolamento de falhas incorporados na infraestrutura de datacenter, regional e de backbone; a empresa continua investindo em hardware de rede personalizado e transmissão de alto desempenho para suportar comunicação de IA de baixa latência; a arquitetura do Google suporta tanto cargas de trabalho internas de IA quanto clientes externos do Google Cloud que usam a infraestrutura de supercomputador de IA da empresa.
"As cargas de trabalho de IA estão mudando a escala e a forma dos requisitos de infraestrutura em todas as camadas da rede", escreveu a equipe de engenharia do Google, descrevendo um ambiente onde as redes de datacenter e a infraestrutura global de backbone operam cada vez mais como um único sistema distribuído.