
De acordo com pt.wedoany.com-A Baidu lançou em 22 de junho, como código aberto, o modelo Unlimited OCR, com o objetivo de resolver o problema de lentidão crescente dos modelos OCR ponta a ponta ao analisar documentos longos. O modelo possui um total de 3 bilhões de parâmetros, ativando apenas 500 milhões durante a inferência.
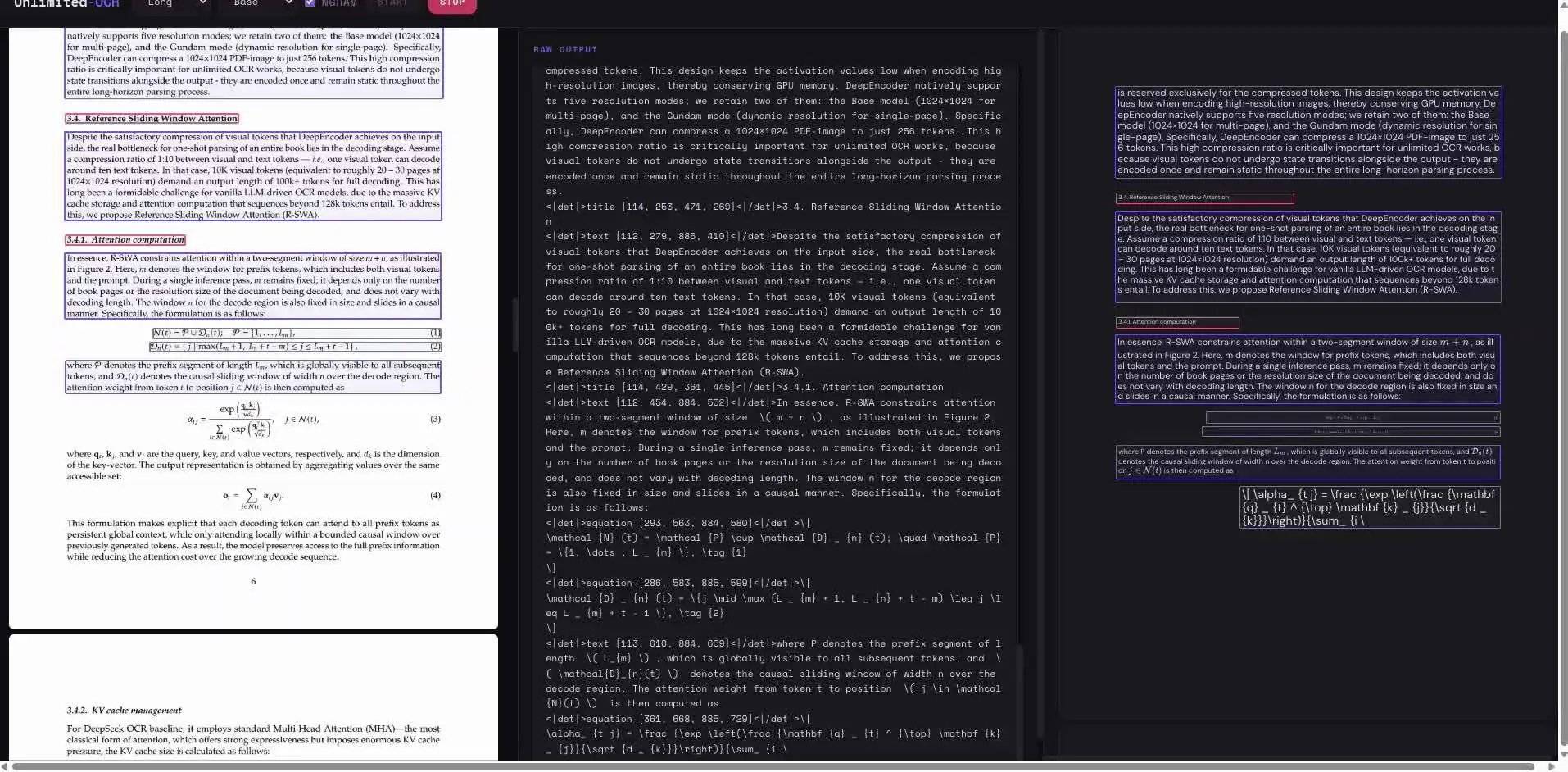
O modelo OCR ponta a ponta adota uma arquitetura de rede neural unificada, integrando a detecção de texto e o reconhecimento de caracteres em um único sistema, mapeando diretamente a imagem de entrada para a saída da sequência de texto, eliminando o fluxo tradicional de primeiro detectar as caixas de texto e depois realizar o reconhecimento separadamente. A cada token gerado, os principais modelos OCR ponta a ponta expandem o cache de chave-valor (KV cache), resultando em um aumento contínuo do uso de memória e da latência, fazendo com que o usuário perceba que a análise de documentos com várias páginas fica cada vez mais lenta.
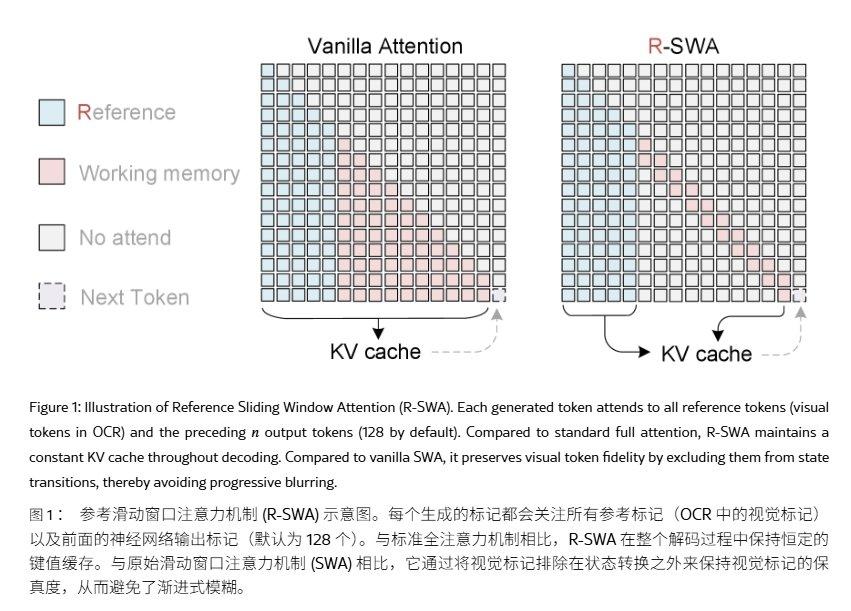
O Unlimited OCR mantém a arquitetura do DeepSeek OCR, preservando o DeepEncoder e o decodificador de Mistura de Especialistas (MoE). O lado da codificação utiliza codificação visual de dois níveis, realizando uma compressão de tokens de 16x na fase de conexão, comprimindo uma imagem PDF de 1024×1024 em 256 tokens visuais, aliviando a carga de pré-preenchimento na origem.
Em termos de treinamento, o Unlimited OCR continuou o treinamento por 4000 passos a partir do checkpoint do DeepSeek OCR, congelando o DeepEncoder e treinando apenas o decodificador. Os dados de treinamento consistem em cerca de 2 milhões de amostras de documentos, executados em GPUs 8×16 A800. A proporção de dados é de aproximadamente 9:1 entre páginas únicas e múltiplas, sendo que as amostras de múltiplas páginas são construídas por concatenação.
Testes de referência mostram que o Unlimited OCR obteve uma pontuação geral de 93,23 no OmniDocBench v1.5, superior aos 87,01 do DeepSeek OCR e 89,17 do DeepSeek OCR 2. Sua distância de edição de texto é de 0,038, CDM de fórmulas é 92,61, TEDS de tabelas é 90,93 e distância de edição de ordem de leitura é 0,045. No OmniDocBench v1.6, a pontuação geral do modelo atingiu 93,92.











