

Modelos de Linguagem Grandes (LLMs) às vezes geram respostas que parecem plausíveis, mas são na verdade incorretas, o que pode ter consequências graves em áreas de alto risco, como saúde ou finanças. Para avaliar de forma mais confiável a precisão das previsões dos modelos, os pesquisadores têm explorado vários métodos de quantificação de incerteza.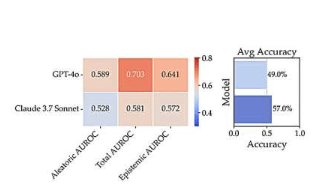
Uma equipe de pesquisa do Instituto de Tecnologia de Massachusetts (MIT), nos EUA, desenvolveu recentemente um novo método que visa identificar de forma mais eficaz respostas de LLMs que são confiantes, mas potencialmente incorretas. O método mede a incerteza comparando a saída do modelo alvo com as de um conjunto de modelos semelhantes. Em comparação com os métodos tradicionais que dependem da autoconsistência de um único modelo, esta abordagem pode capturar com mais precisão o problema do excesso de confiança do modelo.
A equipe de pesquisa combinou essa medida de divergência entre modelos com avaliações de autoconsistência existentes para construir uma métrica de incerteza total. Eles testaram em 10 tarefas práticas, incluindo perguntas e respostas e raciocínio matemático. Os resultados mostraram que essa métrica superou outros métodos existentes na identificação de previsões não confiáveis.
Kimia Hamidieh, estudante de pós-graduação do Departamento de Engenharia Elétrica e Ciência da Computação do MIT e autora principal do artigo, disse: "A autoconsistência é amplamente usada para quantificar a incerteza, mas se confiarmos apenas nos resultados de um único modelo, a estimativa pode não ser confiável. Reexaminamos as limitações dos métodos existentes e projetamos uma estratégia complementar para melhorar empiricamente os resultados."
O artigo de pesquisa foi aceito e será apresentado na 14ª Conferência Internacional sobre Representações de Aprendizado (ICLR), que acontecerá no Rio de Janeiro, Brasil, de 23 a 27 de abril de 2026. Os coautores incluem Veronika Thost do MIT-IBM Watson AI Lab, o professor assistente Walter Gerych do Worcester Polytechnic Institute, Mikhail Yurochkin e a autora sênior Marzyeh Ghassemi.
No nível técnico, o novo método foca na estimativa da incerteza epistêmica, ou seja, o desvio entre o modelo e um estado ideal. Hamidieh ilustrou: "Se você fizer a mesma pergunta ao ChatGPT várias vezes e obtiver a mesma resposta, isso não significa necessariamente que esteja correto; mas se você usar o Claude ou o Gemini e obter respostas diferentes, você percebe a incerteza no nível epistêmico."
Para alcançar esse objetivo, os pesquisadores empregaram um conjunto de modelos treinados por diferentes instituições, com tamanhos e arquiteturas semelhantes, para comparação. Eles descobriram que avaliar as diferenças nas respostas analisando a similaridade semântica pode fornecer uma estimativa melhor da incerteza epistêmica. Este método é computacionalmente eficiente, ajudando a reduzir o consumo de recursos.
A métrica de incerteza total, que combina incerteza epistêmica e incerteza aleatória, pode refletir de forma mais abrangente a confiabilidade do nível de confiança do modelo. Experimentos mostraram que a métrica é eficaz em tarefas factuais, mas ainda há espaço para melhorias em questões abertas. Trabalhos futuros explorarão como otimizar sua aplicação em um cenário mais amplo.
Detalhes da publicação: Autor: Adam Zewe, Instituto de Tecnologia de Massachusetts; Título: «A better method for identifying overconfident large language models»; Publicado em: «Fourteenth International Conference on Learning Representations» (2026).