

Em 5 de junho, a Tencent Hunyuan anunciou a proposta do algoritmo de atenção esparsa Stem, cujos resultados foram aceitos na principal conferência de aprendizado de máquina ICML-26. Este algoritmo visa o gargalo de pré-preenchimento na inferência de contexto longo de modelos grandes. Através de duas técnicas, decaimento de posição do token e métrica de percepção de saída, ele se aproxima da precisão da atenção densa usando apenas 25% do orçamento computacional, reduzindo a latência do primeiro token em 3,6 vezes em cenários de contexto de 128K.
O valor científico do Stem concentra-se num problema que há muito atormenta a implantação de modelos grandes: quanto mais longa a entrada, maior o custo computacional da autoatenção e maior o tempo de espera antes do modelo gerar o primeiro token. Tarefas como perguntas e respostas em documentos longos, análise de bases de código, revisão de contratos, recuperação em bases de conhecimento, memória de diálogos multi-turno e orquestração de agentes empresariais empurram o comprimento do contexto para dezenas de milhares ou até centenas de milhares. Nesses cenários, a velocidade com que o modelo gera texto subsequente é importante, mas o que o usuário sente primeiro é a "latência do primeiro token", ou seja, o tempo que o sistema leva para ler toda a entrada longa, concluir o cálculo de pré-preenchimento e começar a gerar o primeiro token. A autoatenção tradicional do Transformer exige interações extensas entre os tokens, e o custo computacional aumenta rapidamente com o comprimento da sequência. Portanto, a atenção esparsa torna-se uma direção importante para reduzir o custo de contexto longo. A principal contribuição do Stem é que ele não reduz simplesmente o cálculo da atenção de forma uniforme, mas reentende o papel dos tokens dentro do modelo a partir do fluxo de informação causal. Na estrutura de atenção causal, os tokens em posições iniciais participam continuamente da agregação de informações dos tokens subsequentes, agindo como um "tronco" que suporta a transmissão de informações posteriores. Se um algoritmo esparso usar o mesmo orçamento para todas as posições, ele pode facilmente ignorar o papel de dependência recursiva dos tokens iniciais em sequências longas. A estratégia de decaimento de posição do token proposta pelo Stem realoca recursos computacionais para diferentes posições sem aumentar o orçamento total, alocando mais orçamento de atenção para posições mais críticas no fluxo de informação, reduzindo assim a perda de precisão causada por esparsidade excessiva. Outra métrica, a percepção de saída, resolve o problema de "quais tokens selecionar como mais valiosos". Métodos anteriores dependiam mais das pontuações de atenção para julgar a importância, mas uma pontuação alta de atenção não representa necessariamente uma grande contribuição para a saída final; a magnitude da informação transportada pelo vetor Value também afeta o resultado. O Stem combina a probabilidade de roteamento e a contribuição do sinal de saída para medir o valor do token, tornando a seleção esparsa mais próxima do processo real de saída do modelo. Este design faz com que a atenção esparsa passe de simplesmente reduzir o cálculo para selecionar com base no fluxo de informação e na contribuição da saída, fornecendo um caminho algorítmico mais granular para a inferência de contexto longo.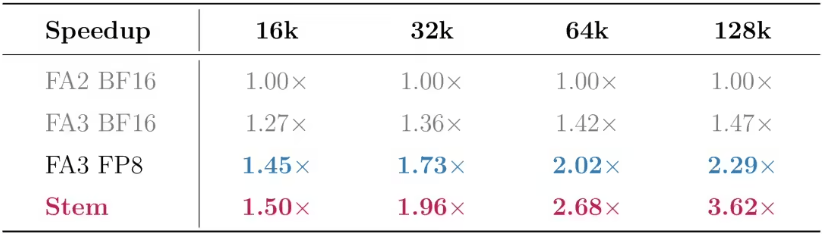
O que realmente impacta a implementação industrial é se os ganhos algorítmicos podem ser traduzidos em aceleração mensurável no hardware.
A solução full-stack fornecida simultaneamente pela Tencent Hunyuan desta vez combina o algoritmo Stem com bibliotecas de operadores HPC, resolvendo o gargalo crítico entre a teoria e a implantação da atenção esparsa. Muitos algoritmos esparsos podem reduzir a carga computacional em experimentos de artigos, mas ao entrar no sistema de inferência GPU, podem incorrer em custos adicionais devido à seleção de blocos, indexação, salto de blocos, movimentação de dados e acesso ao cache, resultando num ganho de velocidade ponta a ponta inferior ao esperado teoricamente. Os operadores HPC-Stem e HPC-BSA que acompanham o Stem otimizam a engenharia em torno deste problema: o primeiro acelera o processo de avaliação e seleção de blocos, e o segundo visa o processo de execução da atenção esparsa em nível de bloco, permitindo que os blocos de cálculo ignorados realmente reduzam a sobrecarga na GPU. Especialmente quando fatores de ambiente de produção como arquitetura Hopper, quantização FP8, Paged KV Cache e framework de inferência vLLM são sobrepostos, se os ganhos da esparsidade podem ser realizados de forma estável determina diretamente se o algoritmo tem valor prático de aplicação. A Tencent Hunyuan integrou o Stem no cenário de inferência quantizada W8A8-FP8 do Hy3 preview e alcançou uma redução de 3,6 vezes na latência do primeiro token em contexto de 128K, indicando que a solução já ultrapassou a fase de validação puramente acadêmica e começou a otimizar para cadeias de inferência de nível industrial. Para aplicações de modelos grandes de nível empresarial, o significado desta melhoria é muito direto: para a mesma entrada superlonga, o sistema completa o pré-preenchimento mais rapidamente, melhorando significativamente a experiência de espera do usuário; com o mesmo conjunto de recursos GPU, a eficiência do processamento de solicitações de contexto longo aumenta, reduzindo os custos de serviço e melhorando a capacidade da plataforma de suportar tarefas mais complexas. À medida que a janela de contexto do modelo continua a expandir-se, as empresas não procuram apenas "quanto o modelo pode ler", mas também "ler rápido, com baixo custo e precisão estável". O Stem conecta a seleção de informação ao nível do algoritmo com a execução do hardware ao nível do operador, estendendo a otimização da inferência de texto longo da pesquisa de estrutura do modelo para a coordenação do sistema computacional, o que é uma razão importante para ser considerado uma conquista científica e tecnológica.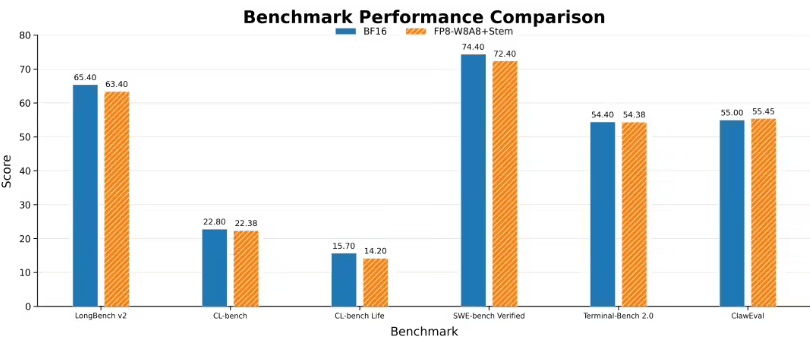
Este resultado também sugere que a competição de modelos grandes está a entrar numa camada de infraestrutura mais profunda. No passado, a melhoria da capacidade do modelo refletia-se mais na escala de parâmetros, dados de treino, ajuste fino de instruções e ecossistema de aplicações; depois que o contexto longo se tornou uma capacidade mainstream, o pré-preenchimento, o cache KV, a atenção esparsa, a inferência quantizada, a otimização de operadores e o sistema de escalonamento começaram a determinar se o modelo pode funcionar a baixo custo. O surgimento do Stem mostra que as equipas nacionais de modelos grandes estão a estender o foco de I&D para a otimização coordenada de algoritmos, operadores e frameworks de inferência, em vez de competir apenas nos parâmetros do modelo e nas pontuações dos rankings. Para aplicações industriais nos setores financeiro, governamental, industrial, médico, jurídico e científico que precisam processar documentos longos, a redução da latência do primeiro token afetará diretamente a usabilidade do sistema: a revisão de contratos não precisa de longas esperas, as perguntas e respostas em bases de conhecimento podem processar contextos mais longos, os agentes podem reter mais informações históricas em cadeias de tarefas maiores, e os assistentes de I&D podem ler mais código e documentação de uma só vez. Se, no futuro, o algoritmo Stem e os operadores de código aberto continuarem a expandir-se para mais modelos, mais arquiteturas de hardware e janelas de contexto mais longas, o seu valor não se limitará ao sistema Tencent Hunyuan, mas também poderá tornar-se uma referência de método geral no campo da inferência eficiente de texto longo.
Do ponto de vista da trajetória técnica, o avanço do Stem não é simplesmente uma busca por "calcular menos", mas sim comprimir o cálculo de atenção mais caro na inferência de contexto longo de modelos grandes para uma faixa mais implantável, com a menor perda possível de precisão. Com o desenvolvimento contínuo de contextos de milhões de tokens, agentes empresariais e tarefas multimodais complexas, a latência do primeiro token tornar-se-á um indicador importante para medir a capacidade de engenharia de modelos grandes. Este resultado da Tencent Hunyuan fornece uma nova ideia de otimização para a inferência de contexto longo e também leva a atenção esparsa de artigos de algoritmo para aceleração real de hardware e verificação em ambiente de produção.