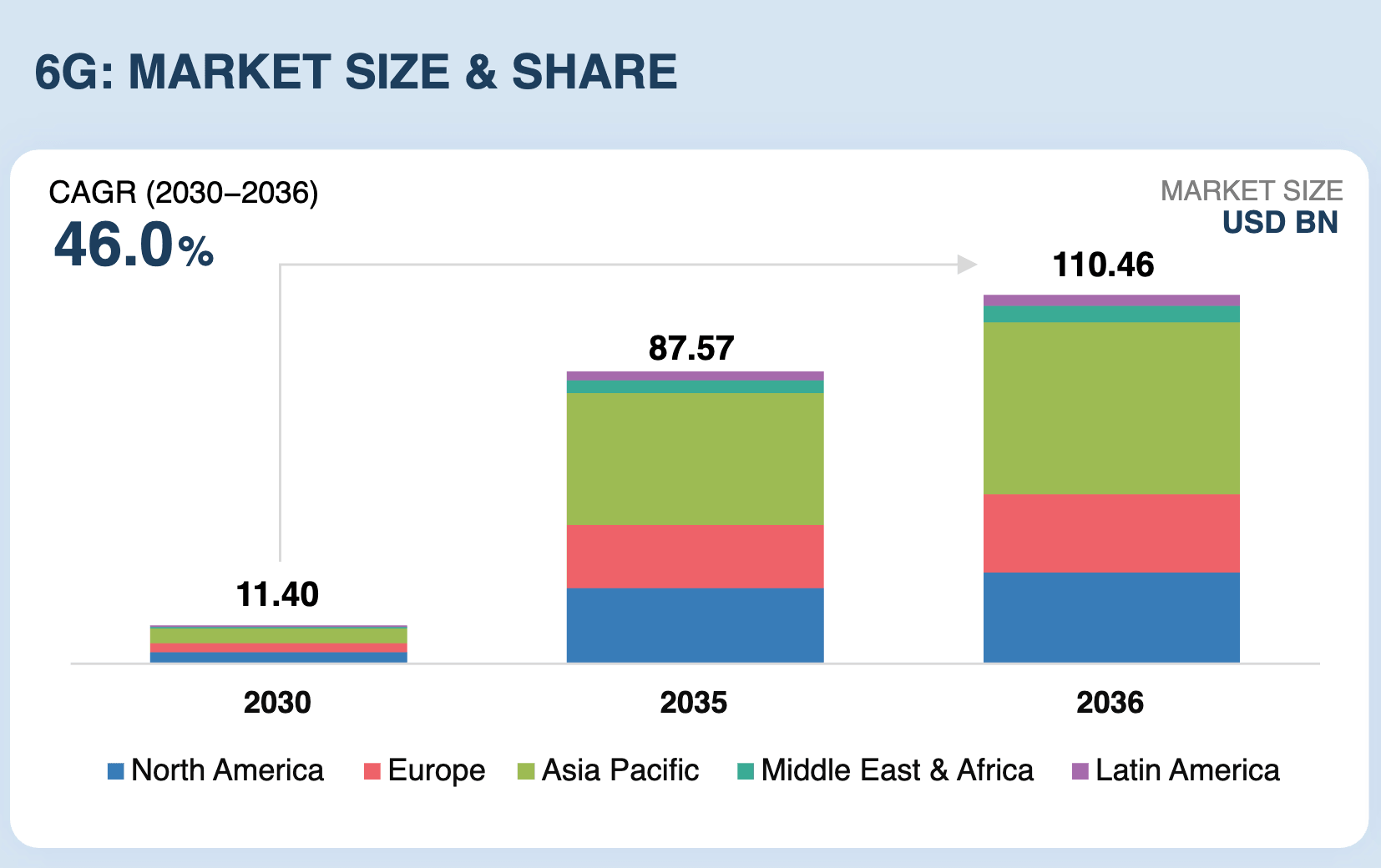
De acordo com pt.wedoany.com-Em 10 de junho de 2026, a Zilliz, sediada em Redwood City, Califórnia, anunciou que seu Zilliz Vector Lakebase entrou em fase de pré-visualização pública. Esta é uma importante atualização do Zilliz Cloud, que visa combinar um banco de dados vetorial de nível de produção com uma base de dados nativa de data lake compartilhada.
O Vector Lakebase tem como núcleo a pesquisa vetorial em tempo real do Zilliz Cloud, motor que já atende Zillow, OpenEvidence, Exa, Filevine, MiniMax e mais de 10.000 empresas e equipes de IA. Esta atualização expande três novas formas de operar os mesmos dados: descoberta interativa, análise em lote em larga escala e pesquisa direta em data lakes externos. O resultado é uma base de dados única, onde todas as cargas de trabalho operam sobre uma única cópia lógica dos dados, e as tarefas sob demanda e em lote são cobradas apenas quando a computação está ativa.
Charles Xie, fundador e CEO da Zilliz, afirmou que a pesquisa vetorial de nível de produção é o núcleo da empresa e a razão pela qual milhares de equipes escolhem Milvus e Zilliz Cloud. O Vector Lakebase é o próximo passo que a Zilliz considera: uma base de dados onde o mesmo vetor pode atender consultas de produção, sustentar sessões de descoberta e impulsionar pipelines de dados de treinamento em escala de PB, sem necessidade de réplicas, migrações ou pilhas paralelas.
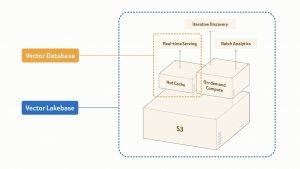
Em relação à importância de uma base de dados única, os sistemas de IA não são mais um problema de recuperação de consulta única. Eles operam em ciclos contínuos, incluindo servir, aprender com feedback, minerar e preparar dados melhores, e depois servir novamente. Cada etapa geralmente requer sistemas independentes para lidar com serviço, exploração e processamento em larga escala. Mover bilhões de vetores entre esses sistemas pode levar dias. O Vector Lakebase preenche essa lacuna construindo um plano de dados semântico de cópia zero sobre armazenamento nativo de data lake compartilhado, permitindo que serviço em tempo real, descoberta interativa e análise em lote operem sobre uma única cópia lógica dos dados, escalando de GB a PB.
Robert Guo, vice-presidente de produtos da Zilliz e um dos arquitetos do Milvus, disse que a equipe queria encontrar uma maneira de manter os dados em um só lugar e executar cargas de trabalho drasticamente diferentes sobre eles. O Vector Lakebase alcança isso por meio de uma camada de armazenamento unificada sobre Vortex, serviço em camadas para o caminho de produção e computação sob demanda para todas as outras necessidades.
O Vector Lakebase possui cinco capacidades principais em uma única base. Primeiro, serviço em tempo real em camadas oferece três níveis de produção otimizados para diferentes cargas de trabalho: otimizado para desempenho (1000+ QPS, latência de dígitos únicos em ms, memória), otimizado para capacidade (100–500 QPS, latência abaixo de 100ms, memória mais NVMe) e armazenamento em camadas (10–50 QPS, latência de aproximadamente 100ms, abrangendo memória, NVMe e armazenamento de objetos, com custo significativamente reduzido). Todos os níveis têm recall padrão de 95–98%, ajustável para mais de 99%, e são suportados pelo SLA de 99,99% de disponibilidade do Zilliz Cloud e alta disponibilidade entre regiões em clusters globais. Segundo, pesquisa sob demanda oferece computação paga por uso para cargas de trabalho onde a infraestrutura fica ociosa na maior parte do tempo, cobrando diretamente pelo armazenamento de objetos e computação. Um benchmark interno da Zilliz com 1 bilhão de vetores de 768 dimensões e 10 horas de computação ativa por mês mostrou que a pesquisa sob demanda custou um total de US$ 318, enquanto um caminho serverless semelhante custaria US$ 4.937, cerca de 1/15 do custo. Terceiro, pesquisa em data lake externo é um modo de coleção externa de cópia zero que adiciona indexação de ponta e pesquisa de espectro total diretamente a tabelas Lance, Iceberg, Parquet e Vortex existentes, com sincronização incremental durante a atualização, mantendo os dados de origem em seu local. Quarto, pesquisa de IA de espectro total suporta pesquisa em vetores (densos e esparsos), texto, JSON e dados geoespaciais, incluindo recuperação híbrida, BM25, expressões regulares, pesquisa multi-vetor e iterativa, e recuperação multi-caminho, com resultados reordenáveis usando Cohere, Voyage AI, RRF e estratégias ponderadas, aumentadas ou de atenuação. Quinto, armazenamento nativo de data lake unificado constrói armazenamento compartilhado para serviço e análise sobre Vortex, um formato de coluna aberto projetado para leituras aleatórias mais rápidas e baratas que Lance e Parquet, combinado com indexação consciente de armazenamento de objetos, reduzindo a amplificação de leitura em mais de 90%. Um preenchimento de esquema de 100 milhões de linhas geralmente é concluído em minutos de dígitos únicos, sem interromper o tráfego de consultas ativas.
Juntas, essas capacidades permitem que equipes de IA consolidem os clusters de serviço paralelos sempre ativos e sistemas de lote independentes anteriormente necessários em uma única plataforma, com indexação consistente, dados versionados e recursos de computação que podem ser reduzidos a zero entre tarefas.
O Zilliz Vector Lakebase agora está em pré-visualização pública no Zilliz Cloud, com opções de implantação serverless, dedicada e BYOC, cobrindo mais de 30 regiões na AWS, Google Cloud e Microsoft Azure. O registro com e-mail corporativo concede US$ 100 em crédito gratuito. Equipes que executam serviço, descoberta e análise em pilhas independentes podem entrar em contato com a equipe Zilliz para orientação personalizada.
A Zilliz é uma empresa de infraestrutura de dados de IA e criadora do banco de dados vetorial de código aberto Milvus, que possui mais de 44.000 estrelas no GitHub e mais de 100 milhões de pulls no Docker. A Zilliz ajuda empresas e startups de IA a tornar seus dados não estruturados pesquisáveis, analisáveis e governáveis. Sua tecnologia tem como núcleo Milvus e Zilliz Cloud. Milvus é um banco de dados vetorial de código aberto construído para pesquisa vetorial em escala de centenas de bilhões. O Zilliz Cloud expande essa base para uma plataforma Vector Lakebase totalmente gerenciada, combinando a alta taxa de transferência e baixa latência de serviço de um banco de dados vetorial com a abertura, escalabilidade e economia de um data lake multimodal. A Zilliz apoia mais de 10.000 empresas e startups nativas de IA em todo o mundo, incluindo MiniMax, OpenEvidence, Filevine, Exa, Salesforce e Read AI. A empresa está sediada em Redwood Shores, Califórnia, e é apoiada por investidores como Prosperity 7 Ventures da Aramco, Pavilion Capital da Temasek, Hillhouse Capital, 5Y Capital, Yunchuang Capital e Trustbridge Partners.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com