
De acordo com pt.wedoany.com-Engenheiros da Alibaba lançaram o Qwen-Robot Suite, composto por três modelos básicos de IA projetados para robôs e agentes inteligentes. Esses modelos não apenas compreendem texto e imagens, mas também podem executar operações no mundo físico.

O conjunto contém três modelos, cada um voltado para diferentes necessidades de tarefas robóticas.

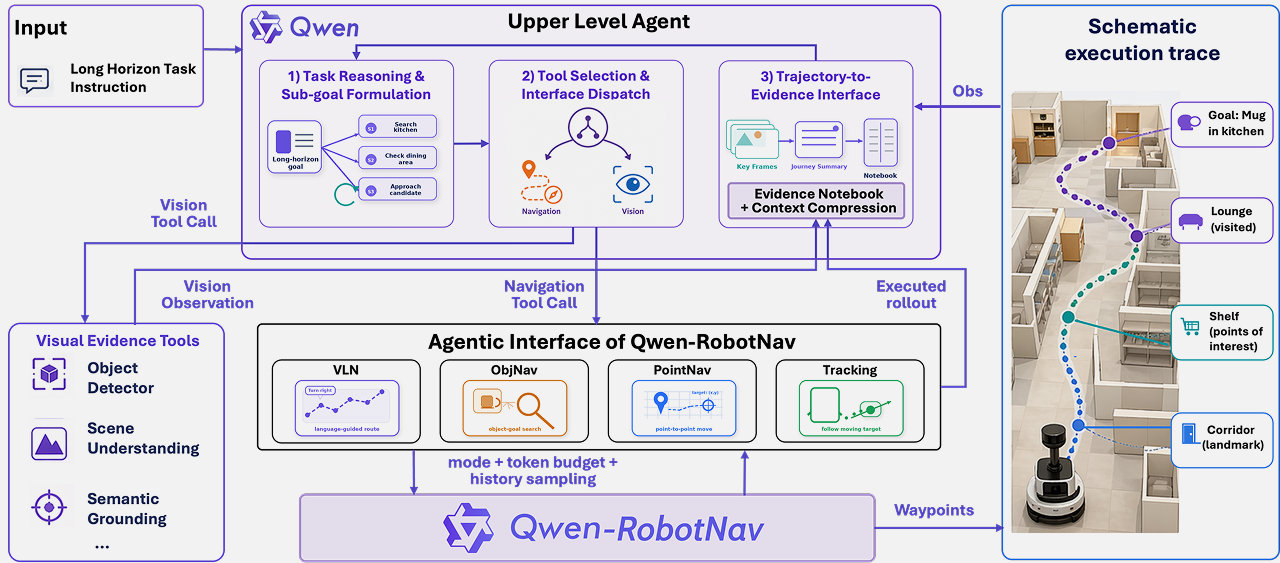
O Qwen-RobotNav é um modelo que integra múltiplos cenários de navegação, abrangendo funções como seguir instruções, ir a pontos designados, busca de objetos, rastreamento de alvos e direção autônoma. Este modelo é posicionado como um modelo fundamental de navegação para sistemas de agentes inteligentes. Planejadores externos podem combiná-lo com subtarefas derivadas de tarefas maiores e alternar dinamicamente os modos do modelo durante a execução.
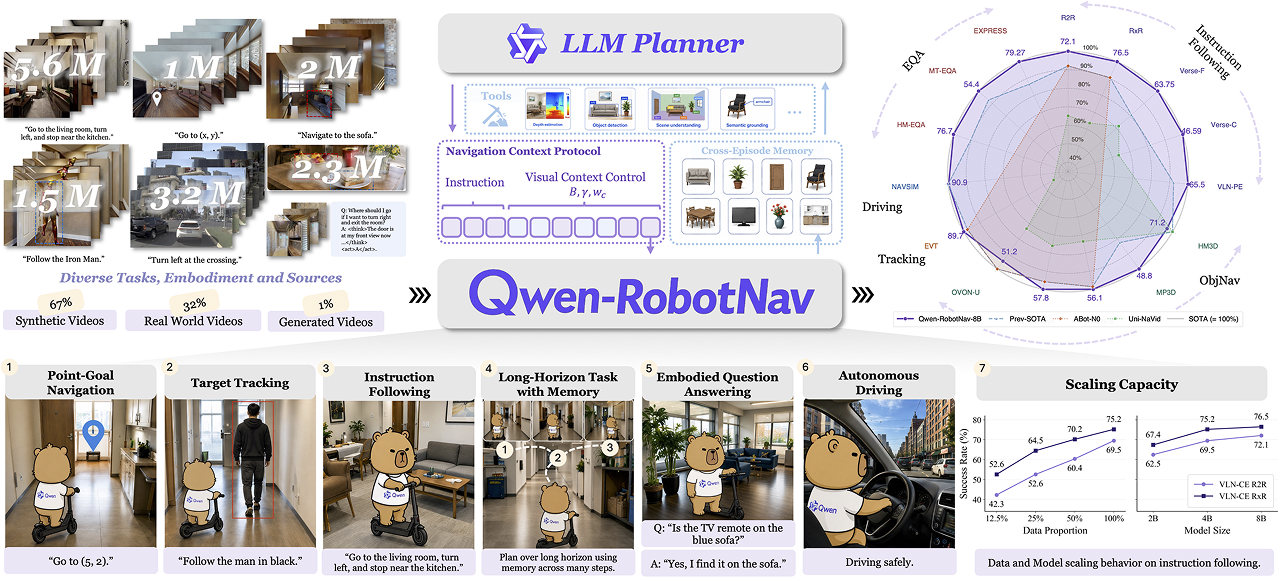
O modelo suporta a configuração de protocolos de observação, permitindo que o sistema realize ajustes dinâmicos ao processar contexto visual, como ajustar o número de tokens ou os pesos de diferentes câmeras. Os engenheiros o treinaram em 15,6 milhões de amostras, expandindo o número de parâmetros de 2 bilhões para 8 bilhões para melhorar o desempenho.
O Qwen-RobotManip é um modelo de visão-linguagem-ação baseado no Qwen-VL, especializado na interação física com objetos. Este modelo visa resolver o problema da heterogeneidade de dados robóticos, ou seja, as diferenças causadas por variações na estrutura, sensores e métodos de controle entre diferentes robôs.
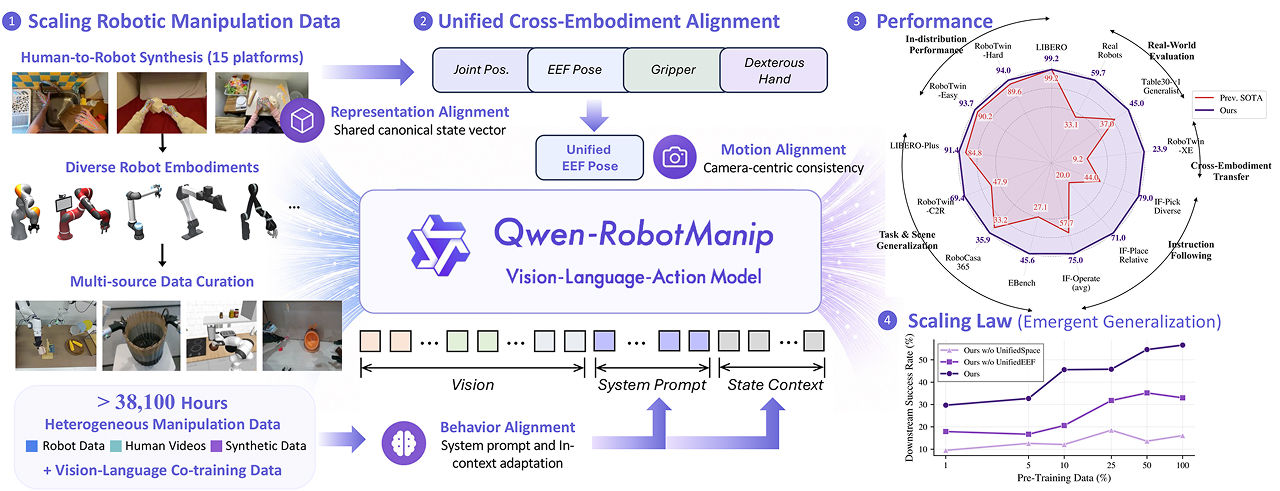
Para resolver esse problema, o Qwen-RobotManip adota um mecanismo de alinhamento de representação, ação e comportamento, permitindo que desenvolvedores realizem a transferência de habilidades entre diferentes robôs de forma mais simples. O modelo foi treinado em um conjunto de dados contendo 38 mil vídeos, dados robóticos e dados sintéticos.
O Qwen-RobotWorld é um modelo de mundo que pode "prever" a evolução do ambiente físico com base em observações em tempo real e instruções de texto. Este modelo pode gerar trajetórias visuais futuras para diferentes cenários.
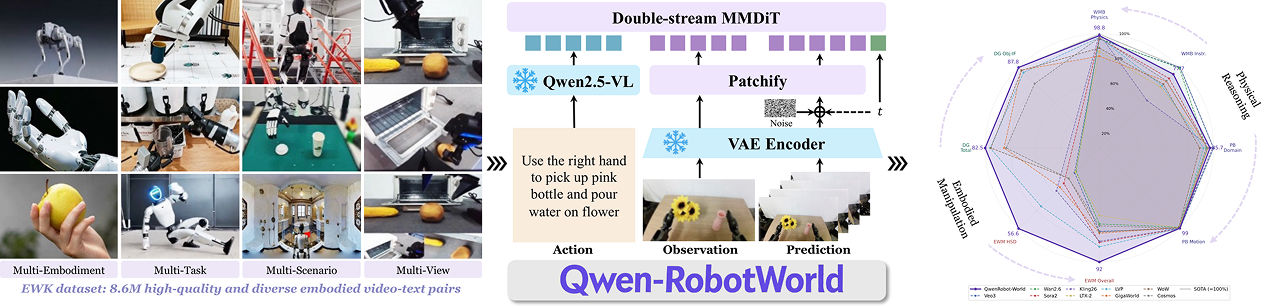
Atualmente, todos os modelos do conjunto foram lançados como código aberto e os vídeos de demonstração podem ser visualizados na página oficial.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com









