De acordo com pt.wedoany.com-A equipe Qwen da Alibaba lançou o Qwen-AgentWorld, que inclui dois modelos. Eles não são usados para executar ações em ambientes de agente, mas sim para prever os resultados retornados por esses ambientes, abrangendo sete áreas: MCP, busca, terminal, engenharia de software, Android, Web e sistema operacional.
Este lançamento dá continuidade ao recente investimento da Alibaba em agentes autônomos. O Qwen3.7-Max, lançado em maio, foi construído em torno de 35 horas de capacidade de execução autônoma. A equipe destacou que o principal gargalo no treinamento de agentes em larga escala reside nas limitações do treinamento em ambientes reais: mecanismos de busca não podem injetar condições controladas, terminais em tempo real não permitem simular sob demanda casos extremos, como espaço em disco insuficiente, e os agentes têm dificuldade em serem expostos sistematicamente a cenários raros.
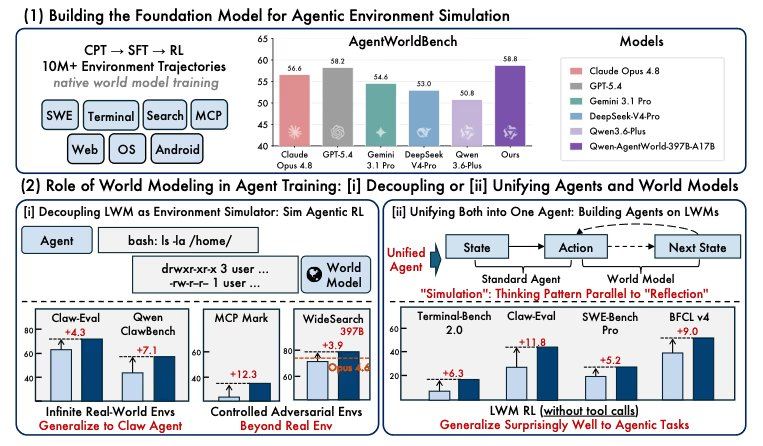
A equipe de pesquisa treinou agentes em simuladores gerados e descobriu que o desempenho melhorou mais do que o treinamento apenas em ambientes reais. Em outro teste, usar o treinamento do modelo de mundo como uma etapa de aquecimento antes do ajuste fino do agente melhorou o desempenho em todos os sete benchmarks, três dos quais nunca foram vistos durante o treinamento. O artigo que acompanha o lançamento aponta que a modelagem do mundo é uma etapa crucial para alcançar agentes universais.
Ao contrário dos modelos de agente tradicionais que otimizam a seleção de ações, o Qwen-AgentWorld é treinado para responder à pergunta inversa: dado que o agente acabou de executar uma ação, o que o ambiente exibirá em seguida? O artigo chama essa abordagem de "modelo de mundo de linguagem", onde o modelo aprende a prever o próximo estado do ambiente em todos os sete domínios sob um único objetivo de treinamento. Pesquisas anteriores relacionadas tinham escopo mais restrito, como o WebWorld lançado pela Qwen em fevereiro, que cobria apenas ambientes web; e o Agent World Model lançado pela Snowflake no mesmo mês, que gerava ambientes de suporte SQL orientados por código, em vez de treinar modelos para prever estados. O Qwen-AgentWorld é o primeiro modelo a abranger sete domínios em um único modelo e a incorporar a modelagem do ambiente desde o estágio inicial de pré-treinamento.
O processo de treinamento usou mais de dez milhões de trajetórias de interação ambiental de execuções reais de agentes, dividido em três estágios: o primeiro estágio ensina ao modelo como o ambiente funciona, incluindo sistema de arquivos, estado do terminal, mudanças no DOM do navegador e respostas de API; o segundo estágio treina o modelo a raciocinar sobre o estado subsequente antes de fazer a previsão; o terceiro estágio, por meio de aprendizado por reforço, utiliza verificações baseadas em regras e pontuações de qualidade abertas para refinar as previsões. Ambos os modelos adotam um design de especialistas mistos, onde apenas uma pequena parte dos parâmetros é ativada por token. O modelo de 35B ativa 3B, e o de 397B ativa 17B, ambos suportando uma janela de contexto de 256K. Para os domínios de GUI (Android, Web e sistema operacional), os modelos trabalham a partir de árvores de acessibilidade de texto e hierarquias de visualização da interface do usuário, em vez de capturas de tela. Os pesos do modelo de 35B e o AgentWorldBench estão disponíveis sob a licença Apache 2.0; os pesos do modelo de 397B ainda não foram divulgados publicamente.
As pontuações dos benchmarks mostram a precisão com que o modelo prevê o conteúdo retornado pelo ambiente, mas os resultados do treinamento revelam o valor prático dessa capacidade preditiva para a construção de equipes de agentes, e esses números são mais importantes. Segundo os pesquisadores, os agentes treinados em simulações controladas tiveram desempenho superior aos treinados em ambientes reais. A injeção de perturbações direcionadas elevou o MCPMark de 24,6 para 33,8. Em tarefas de busca, agentes treinados em mundos completamente fictícios foram transferidos para tarefas de busca reais, melhorando o WideSearch F1 Item no modelo de código aberto de 35B de 34,02 para 50,31. Testes de aquecimento mostraram que o pré-treinamento do modelo de mundo elevou o BFCL v4 de 62,29 para 71,25 e o Claw-Eval de 53,60 para 64,88, sem qualquer ajuste fino específico para o agente.
Após a publicação do artigo, gerou discussões entre pesquisadores de IA. Alguns acreditam que a Qwen inverteu a questão central, treinando o modelo para prever o ambiente em si, e esse conhecimento preditivo é então transferido para tarefas de agente, mesmo sem ajuste fino específico para o agente. Outros pesquisadores apontaram que o AgentWorldBench é um benchmark construído e publicado pela Alibaba no mesmo artigo, e o modelo venceu com uma margem de 0,46, o que pode levar a um escrutínio sobre a independência dos critérios de avaliação. O problema tradicional com abordagens de RL simulada é que os agentes tendem a superajustar as características do simulador; se o modelo de mundo for muito limpo, o agente aprende o modelo em vez da tarefa. As divisões de validação e os resultados de dados no artigo respondem parcialmente a essas preocupações. Os resultados da busca em mundos fictícios mostram que agentes treinados nesses ambientes podem ser transferidos para tarefas de busca reais.
Para equipes que constroem e expandem pipelines de agentes, este trabalho oferece uma terceira opção: simulações controladas que injetam casos extremos que não ocorreriam em ambientes de produção. Ambientes sintéticos são uma camada de treinamento legítima, um complemento ao RL em ambientes reais, e não um atalho para contorná-lo. A fundamentação ambiental antes do treinamento do agente atua mais cedo no processo de desenvolvimento do que a maioria das práticas atuais, capaz de melhorar o desempenho em vários benchmarks sem a necessidade de treinamento específico para o agente. O que o modelo aprende antes do treinamento é muito mais importante do que a maioria dos pipelines considera.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com