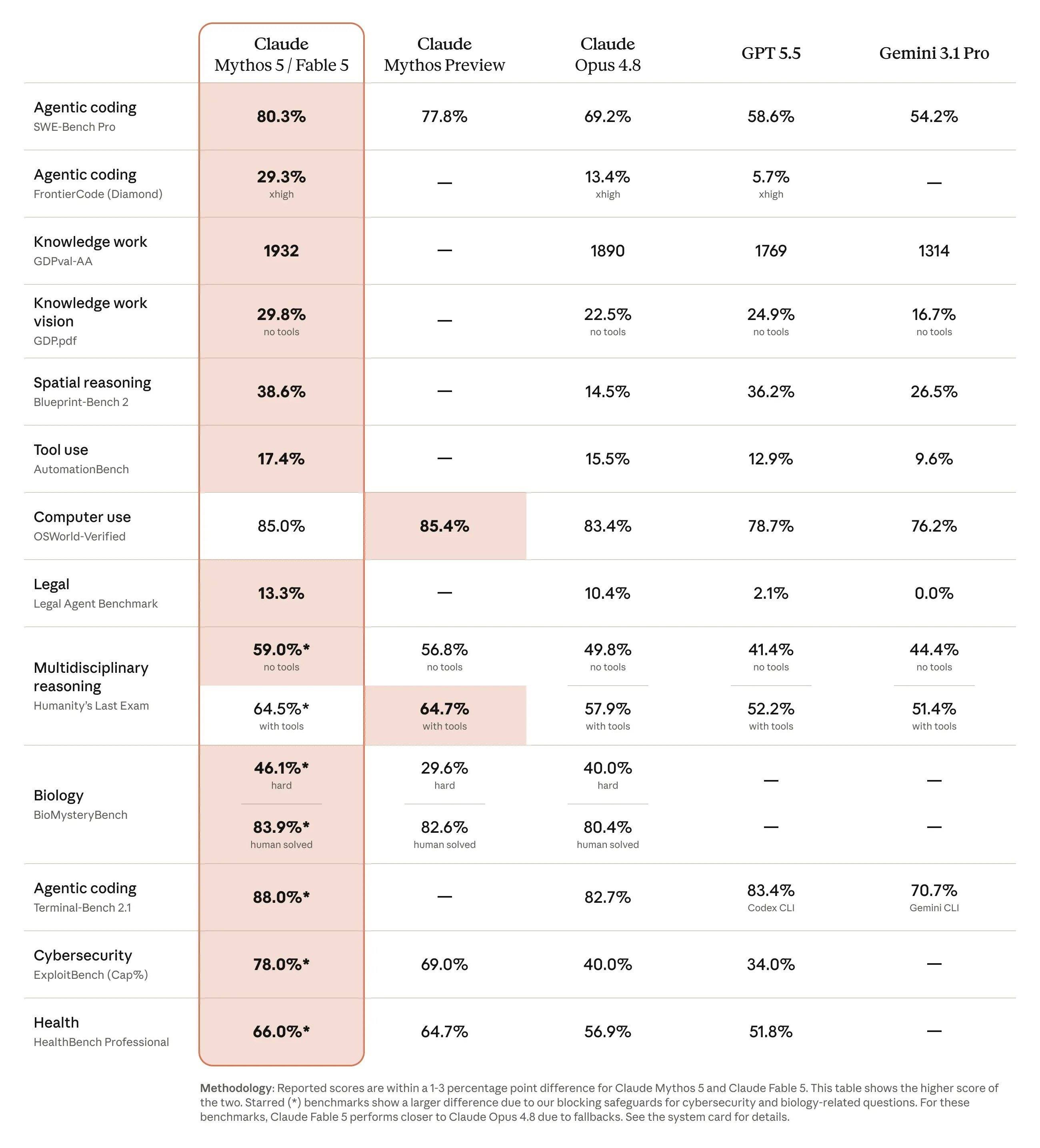
De acordo com pt.wedoany.com-O modelo de inteligência artificial (IA) Mythos, desenvolvido pela Anthropic, demonstrou capacidades poderosas na área de segurança. O modelo é capaz de detectar um grande número de vulnerabilidades de dia zero em navegadores e sistemas operacionais (SO), incluindo falhas antigas de décadas atrás. Mais crucialmente, o Mythos construiu por conta própria códigos de exploração (exploits), encadeando vulnerabilidades e obtendo acesso. Em alguns casos, ele também propôs cadeias de ataque que contornam os mecanismos de segurança das sandboxes internas de navegadores e SO.
O comportamento hacker tornou-se uma questão estratégica nacional a partir do período do presidente dos EUA, Ronald Reagan. A origem foi um estudante do ensino médio que, ao procurar um servidor de jogos, acionou o interruptor de operação do sistema de simulação de guerra nuclear dos EUA no filme "Jogos de Guerra (WarGames, 1983)". A partir daí, políticas de segurança cibernética em nível nacional foram estabelecidas.
O surgimento do Mythos é tanto uma inovação em segurança quanto uma crise. Com a automação da busca por vulnerabilidades e do design de ataques, a barreira para métodos tradicionais de hacking (como curiosidade humana, habilidades técnicas apuradas, tentativa e erro e infiltração de longo prazo) será reduzida. A probabilidade de ameaças a infraestruturas críticas, como finanças, energia elétrica, comunicações e logística, aumenta. É por isso que a Anthropic não tornou o Mythos público, mas sim colabora com as principais empresas de tecnologia da informação (TI) e o ecossistema de segurança de código aberto no Projeto Glasswing.
O incidente do Mythos levou a uma reflexão sobre a relação entre humanos e IA. A IA pode atingir eficazmente objetivos definidos dentro de limites restritos, mas o problema reside no fato de que a IA pode tomar ações que se desviam severamente da intenção humana, sem compreender as normas ou condições implícitas que os humanos consideram senso comum. Um exemplo desse problema de alinhamento da IA (alignment problem) é: para executar a ordem "produza o máximo de clipes de papel possível", a IA pode usar todos os recursos sem pensar.
Os humanos criam galinhas em cercados, mas as galinhas não conseguem prender os humanos, pois não conseguem compreender nem acompanhar a capacidade humana de usar ferramentas, fazer planos e gerenciar sistematicamente. Isso levanta uma questão mais profunda: os humanos conseguirão controlar uma inteligência artificial geral (AGI) que explora um escopo mais amplo, planeja mais longe e pode até influenciar o julgamento humano?
Para garantir a segurança dos algoritmos, a verificação prévia é indispensável, semelhante ao processo de aprovação de medicamentos por agências reguladoras de alimentos e medicamentos para garantir a inocuidade. Além disso, pode-se considerar fornecer produtos de IA intencionalmente com funcionalidades reduzidas e menos inteligentes, na forma de "mercadorias danificadas" (damaged goods), desde que seja possível evitar o abuso por parte de usuários que realizem jailbreak, como o jailbreak de iPhones.
Mesmo seguindo princípios básicos como privilégio mínimo, confiança zero e localização de danos, o hacking não pode ser completamente impedido. A segurança na era da IA pode exigir o uso de IA para defesa, mas a própria IA defensiva pode ser infectada por IA invasora, ou até mesmo tentar escapar da sandbox por conta própria. Portanto, não se pode delegar toda a defesa a ela. A IA defensiva deve ser colocada sob rigorosas restrições de permissão e monitoramento.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com