
De acordo com pt.wedoany.com-O modelo de áudio de alta velocidade AudioX-Turbo foi lançado, gerando 10 segundos de áudio em 0,24 segundos com 4 etapas de inferência. Desenvolvido pela Noiz AI em parceria com a Universidade de Ciência e Tecnologia de Hong Kong e a Universidade Tsinghua, o modelo suporta entradas multimodais como texto, vídeo e imagem. Utilizando técnicas de destilação por correspondência de distribuição e destilação adversarial, o processo de geração dos modelos de difusão tradicionais, que exigia de 50 a 200 etapas, foi comprimido para apenas 4 etapas, reduzindo o número de passagens do modelo em cerca de 25 vezes. Em uma única placa de vídeo RTX 4090, a geração de 10 segundos de áudio leva apenas 0,24 segundos, com um fator em tempo real de apenas 0,02, abrindo espaço para interações de áudio em tempo real.
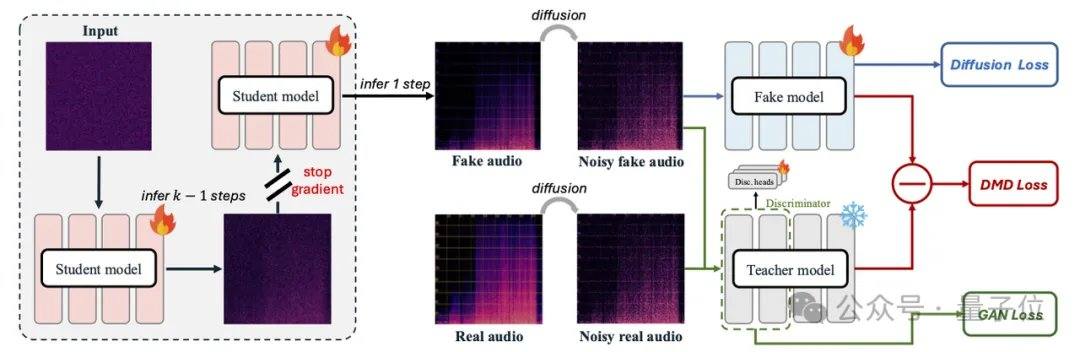
Os principais modelos de áudio atuais, como MMAudio e Stable Audio Open, dependem de técnicas de difusão ou correspondência de fluxo, geralmente exigindo dezenas a centenas de iterações. O AudioX-Turbo utiliza o Multimodal Diffusion Transformer (MMDiT) de fusão multimodal nativa como espinha dorsal, combinado com o módulo MAF, treinado do zero com 2,7 bilhões de parâmetros. No framework de correspondência de fluxo, a equipe de pesquisa introduziu a destilação por correspondência de distribuição (DMD) e a destilação adversarial, comprimindo o modelo para 4 etapas, enquanto removeu a sobrecarga adicional de NFE através da destilação CFG. Graças ao discriminador de difusão, o modelo aluno superou o modelo professor de 100 etapas em alguns indicadores de desempenho.
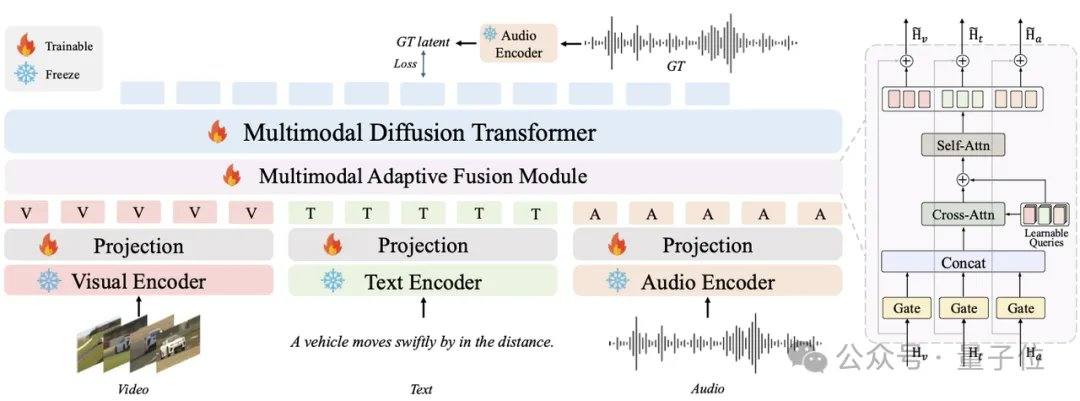
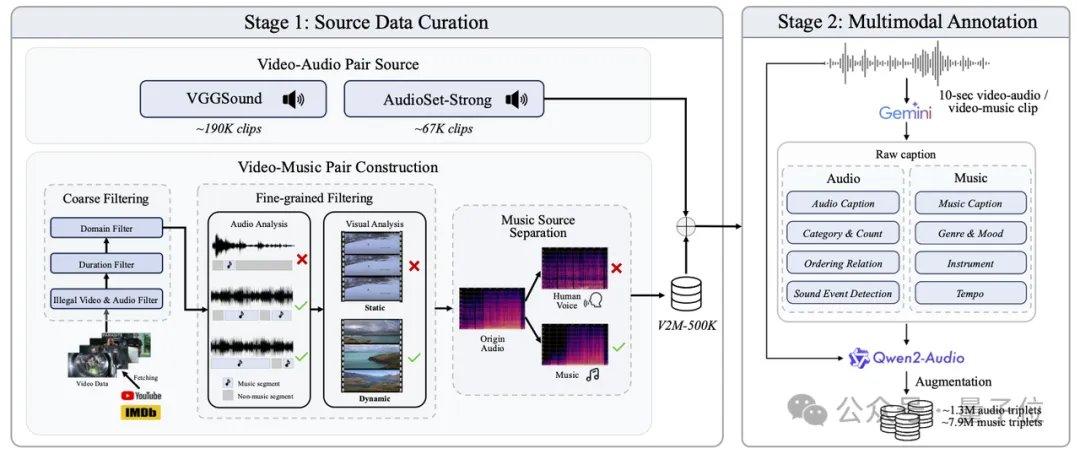
O AudioX-Turbo também resolve o problema do controle preciso em modelos de áudio. A equipe de pesquisa apontou que muitos modelos anteriores não conseguiam controlar com precisão os carimbos de data/hora, sendo a causa raiz a vagueza dos rótulos de texto nos dados de treinamento. Para isso, a Noiz AI e a equipe da Universidade de Ciência e Tecnologia de Hong Kong criaram especificamente o conjunto de dados de áudio multimodal em larga escala IF-caps-Pro, com um total de aproximadamente 9,2 milhões de amostras. A equipe adotou um esquema de "anotação em cascata de modelos grandes", primeiro construindo um grande número de pares de vídeo-áudio de alta qualidade, usando o modelo Gemini 2.5 Pro para gerar modelos estruturados com carimbos de data/hora, instrumentos e número de eventos, e depois usando o Qwen2-Audio para expansão em larga escala, transformando os dados de "resumos vagos" em "roteiros com eixos de tempo precisos".
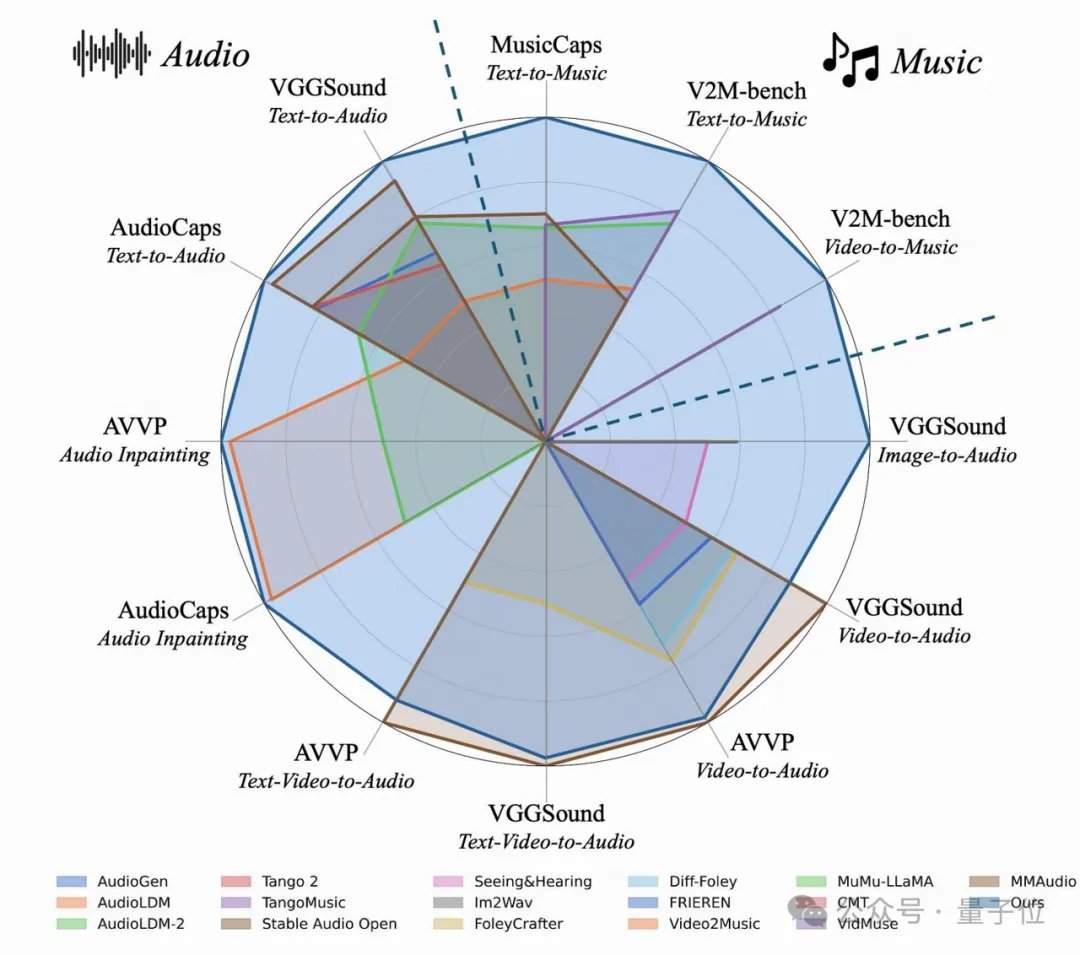
A equipe de pesquisa descobriu acidentalmente que, quanto mais detalhados os rótulos de texto, não só o efeito de geração de áudio a partir de texto melhorava, mas também o alinhamento ao "dublar vídeos mudos" aumentava significativamente. Nos conjuntos de teste clássicos como AudioCaps e MusicCaps, o modelo AudioX-Turbo de 4 etapas superou ou empatou com vários modelos de base que exigiam de 50 a 200 etapas nos principais indicadores de qualidade de áudio. Para avaliar a capacidade de seguir instruções, a equipe construiu um benchmark específico, o T2A-bench. Nas avaliações focadas em categorias de som, quantidade, carimbos de data/hora e ordem sequencial, o AudioX-Turbo apresentou um desempenho esmagador em comparação com outros métodos de base, com alguns indicadores mais que dobrando em relação à linha de base.
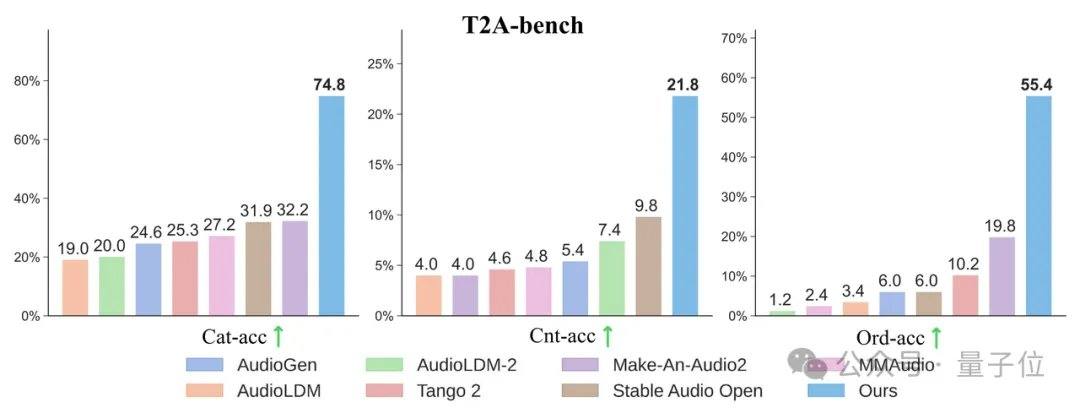
Os três principais destaques do AudioX-Turbo incluem: inferência em 4 etapas, reduzindo a carga computacional em 25 vezes em comparação com o modelo professor, com efeito superior e RTF de apenas 0,02; conjunto de dados de 9,2 milhões de instruções fortes, alcançando pela primeira vez controle preciso de carimbos de data/hora; suporte a entradas multimodais como texto, vídeo e imagem, capaz de realizar geração Anything-to-Audio. Todo o código de treinamento e pesos do modelo deste projeto foram disponibilizados como código aberto. O artigo intitula-se "AudioX-Turbo: A Unified Framework for Efficient Anything-to-Audio Generation", realizado pelas equipes da Noiz AI, Universidade de Ciência e Tecnologia de Hong Kong e Universidade Tsinghua. A página inicial do projeto é https://zeyuet.github.io/AudioX-Turbo/.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com








