De acordo com pt.wedoany.com-A Universidade Renmin da China, em parceria com a Microsoft Research, lançou o framework Arbor, que transforma a otimização autónoma de sistemas de IA de um processo de tentativa e erro num mecanismo de aprendizagem cumulativa. Através da gestão estruturada de hipóteses, o framework alcança um ganho de desempenho verificável superior a 2,5 vezes em tarefas reais de engenharia.

Com o aumento das capacidades dos grandes modelos de linguagem e sistemas de IA, a otimização autónoma tornou-se um desafio central. Ao otimizar agentes de IA, as equipas de engenharia frequentemente precisam ajustar simultaneamente múltiplos parâmetros, como estratégias de particionamento, métodos de recuperação e prompts do sistema. Esses ajustes são interdependentes, dificultando a atribuição precisa e resultando em baixa eficiência do processo de otimização. Jiajie Jin, coautor do artigo, salienta que simplesmente dar mais tempo ou recursos computacionais ao agente de codificação não produz melhores resultados: "Se o objetivo é vago ou as métricas são facilmente manipuláveis, executar por mais tempo geralmente só gera 'melhorias' que ninguém realmente deseja, e mais rapidamente."
Os agentes de codificação existentes dependem de registos de diálogo como memória, mas as tarefas de otimização autónoma envolvem centenas de interações, excedendo facilmente os limites da janela de contexto. Os agentes têm dificuldade em reter evidências factuais em históricos longos, perdendo a estrutura geral do processo de investigação, e tendem a estagnar em falhas iniciais ou a perseguir flutuações ruidosas nas avaliações. Além disso, os frameworks genéricos organizam cadeias de chamadas de ferramentas em árvores de trabalho partilhadas, impossibilitando testar hipóteses paralelas em ambientes isolados.
O Arbor resolve este desafio através de uma arquitetura de separação entre coordenador e executor: o coordenador atua como investigador principal, detendo o estado global do estudo de otimização, propondo hipóteses e decidindo direções experimentais, sem editar diretamente a base de código; o executor é um agente de curta duração que testa hipóteses específicas em árvores de trabalho git independentes. Os dois componentes colaboram através do mecanismo de "refinamento da árvore de hipóteses", representando o processo de investigação como uma árvore de ramificações persistente, onde cada nó está vinculado a uma hipótese, artefacto executável, evidência factual e perceção refinada. O coordenador coloca ideias amplas no nó raiz e refinamentos específicos nos nós folha, podendo explorar múltiplas direções concorrentes simultaneamente. Experiências falhadas são registadas como restrições negativas, impedindo que o sistema repita os mesmos erros.
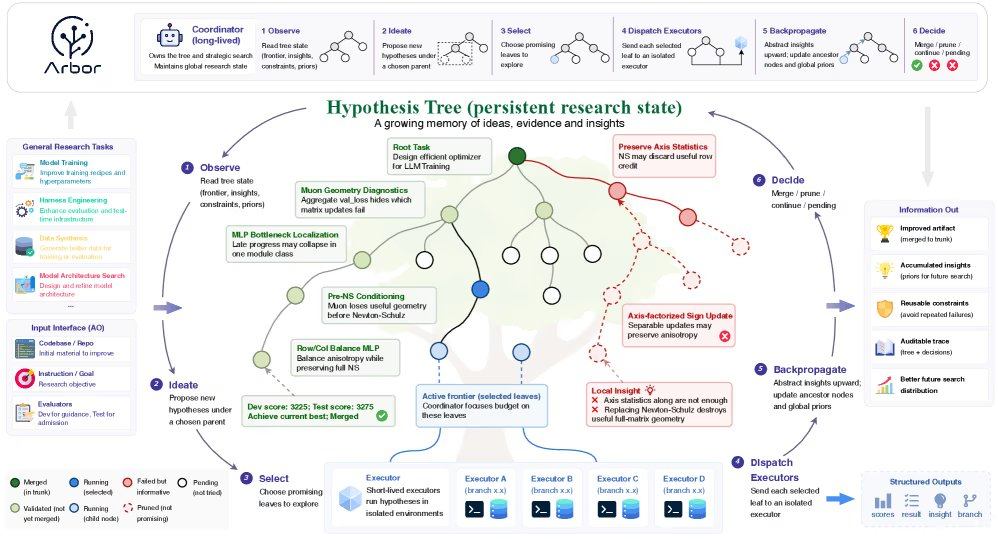
Em cenários reais de engenharia, o Arbor alcança uma atribuição clara de propriedades ao tratar cada alavanca de otimização como uma hipótese separada. Após o executor retornar o relatório, o coordenador escreve as evidências na árvore e propaga as perceções de volta ao nó pai. Para evitar overfitting, o framework impõe um "portão de fusão", testando candidatos em árvores de trabalho independentes e só os fundindo com o tronco atual melhor quando há melhoria na pontuação de retenção.
Os investigadores avaliaram o Arbor num conjunto de tarefas de otimização autónoma baseadas em ambientes reais de investigação e no benchmark de engenharia de machine learning MLE-Bench Lite. O conjunto AO abrange tarefas como treino de modelos, engenharia de frameworks e síntese de dados. Ao utilizar modelos base como Claude Opus 4.6, GPT-5.5 e Gemini-3-Flash, o ganho relativo médio do Arbor foi superior a 2,5 vezes em comparação com Codex e Claude Code. Na tarefa BrowseComp de otimização de agentes de pesquisa, o Arbor elevou a precisão de retenção do sistema de 45,33% para 67,67%, enquanto Codex e Claude Code ficaram em 50% e 53,33%, respetivamente. No MLE-Bench Lite, o Arbor obteve os resultados mais fortes quando equipado com GPT-5.5.
O Arbor demonstra resiliência ao overfitting. Na experiência Terminal-Bench 2.0, o Claude Code obteve uma pontuação de desenvolvimento de 75, mas caiu para 71 nos dados de retenção; o Arbor teve uma pontuação de desenvolvimento mais baixa, 72,22, mas alcançou a pontuação de retenção mais alta, 77,36. Experiências de transferência entre tarefas mostraram que a base de código otimizada para o framework de pesquisa BrowseComp pode melhorar significativamente o desempenho em tarefas não relacionadas, como HLE e DeepSearchQA.
O framework foi concebido para ser construído sobre fluxos de trabalho Git existentes. Jin afirma que a saída do Arbor são ramos git comuns, que podem ser diretamente inspecionados por revisões de código e revisões humanas existentes. O principal custo de implantação é o consumo de tokens gerado pela manutenção do coordenador e pela gestão da árvore, bem como os requisitos de computação e recursos de disco para múltiplas árvores de trabalho isoladas. O framework é adequado para tarefas com métricas claras e fiáveis, que toleram longos períodos de tempo e apresentam múltiplas direções de pesquisa razoáveis, como otimização de pipelines, qualidade de síntese de dados e ajuste de treino de modelos. Não deve ser aplicado a tarefas de latência em tempo real, correções simples ou cenários onde as métricas de avaliação são defeituosas. Jin acredita que o próximo passo evolutivo é fazer com que os artefactos de cada nó passem de uma única pontuação escalar para uma pesquisa multiobjetivo de Pareto, transportando vetores de precisão, latência e custo.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com