De acordo com pt.wedoany.com-A startup chinesa Catnip lançou recentemente o modelo de áudio e vídeo em streaming MaineCoon, que pode gerar áudio e vídeo em tempo real por até 30 minutos ou mais, atingindo uma velocidade de inferência de 47,5 FPS em uma única GPU H100, com um custo por segundo inferior a US$ 0,001.
O MaineCoon foi desenvolvido por uma startup de apenas 10 pessoas, a Catnip, com sede na China. O projeto foi oficialmente iniciado em março deste ano, e três pesquisadores principais concluíram a entrega completa do sistema, incluindo treinamento do modelo, arquitetura, infraestrutura de dados e sistema de inferência, em dois meses.
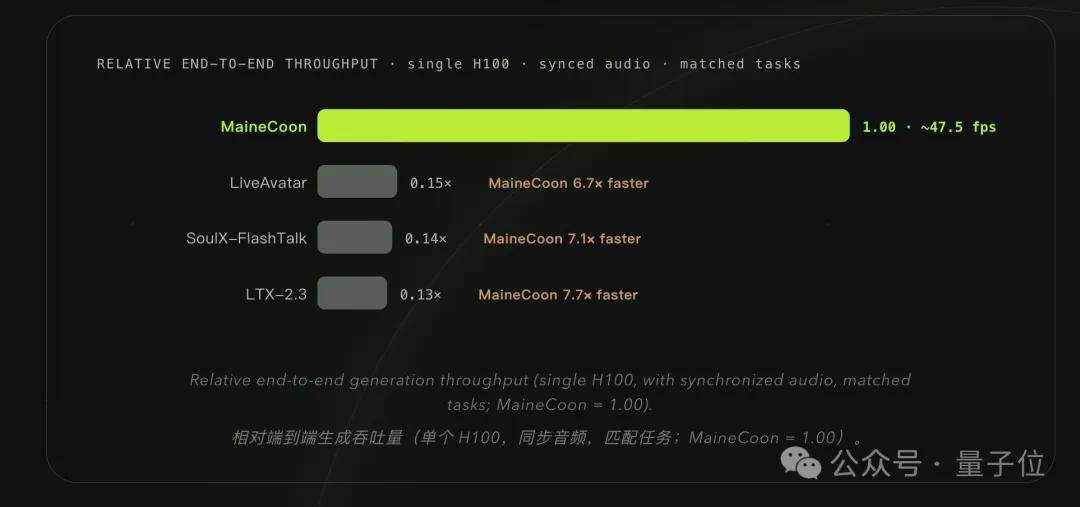
Diferente dos modelos tradicionais de geração de áudio e vídeo, o MaineCoon é o primeiro a focar seu cenário de aplicação na interação social. O modelo suporta reprodução simultânea durante a geração, com áudio e vídeo saindo juntos, e o primeiro quadro pode aparecer em até 1 segundo após a emissão do comando. Com a GPU totalmente ocupada, o custo de inferência por segundo pode ser reduzido para US$ 0,00025, o que é 1/2000 do Veo 3 e 1/560 do Seedance. O modelo possui 22 bilhões de parâmetros e pode operar de forma estável em uma única H100, mantendo uma velocidade de execução em tempo real acima de 30 FPS mesmo em placas de inferência mais baratas, como a RTX Pro 6000.

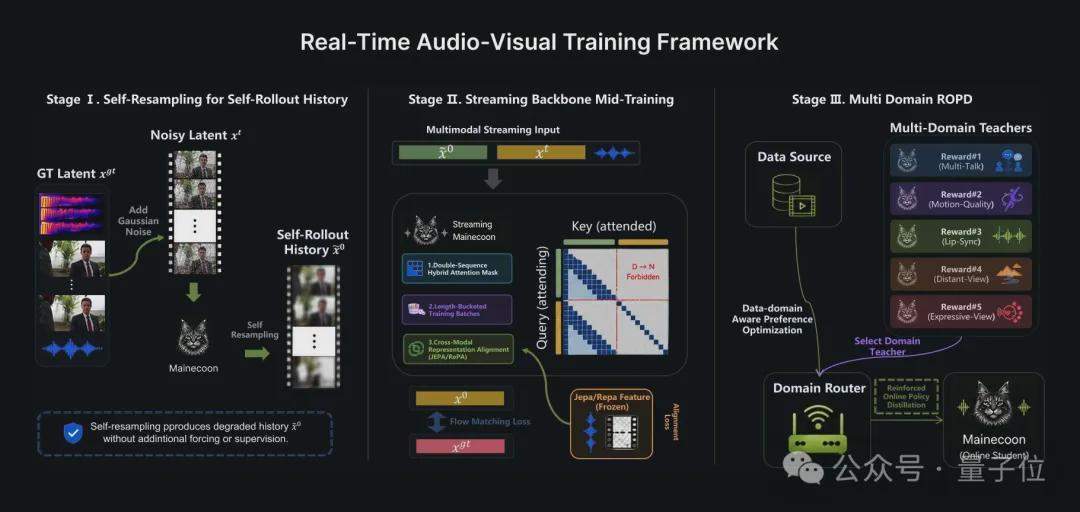
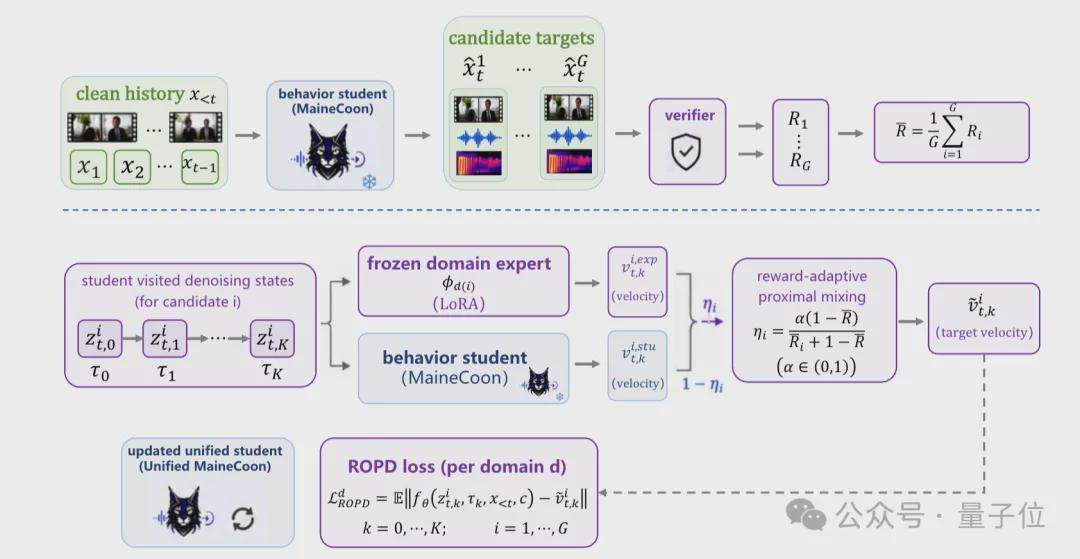
A equipe da Catnip detalhou a arquitetura de treinamento e inferência do MaineCoon em um relatório técnico. A estrutura de treinamento é dividida em três fases: Auto-Reamostragem (Self-Resampling) para resolver a lacuna entre treinamento e inferência; Alinhamento de Representação (Representation Alignment) que acelera a convergência do treinamento conjunto de áudio e vídeo congelando o codificador visual pré-treinado V-JEPA 2; e Otimização de Preferência Ciente de Domínio (DPO) combinada com Destilação de Política Online Reforçada (ROPD), treinando modelos especialistas em preferência para diferentes cenários sociais. Todo o modelo foi treinado em 64 GPUs H100, usando menos de 1 milhão de dados e consumindo 10.000 horas de GPU.
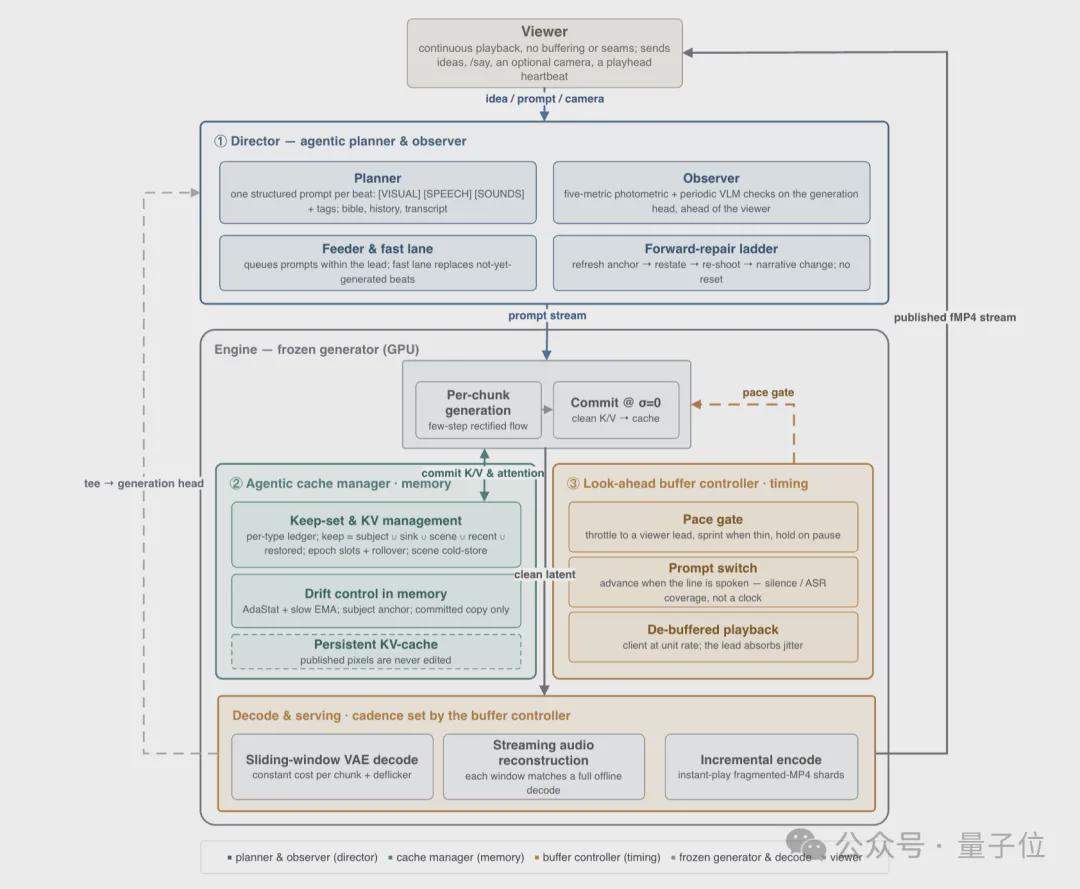
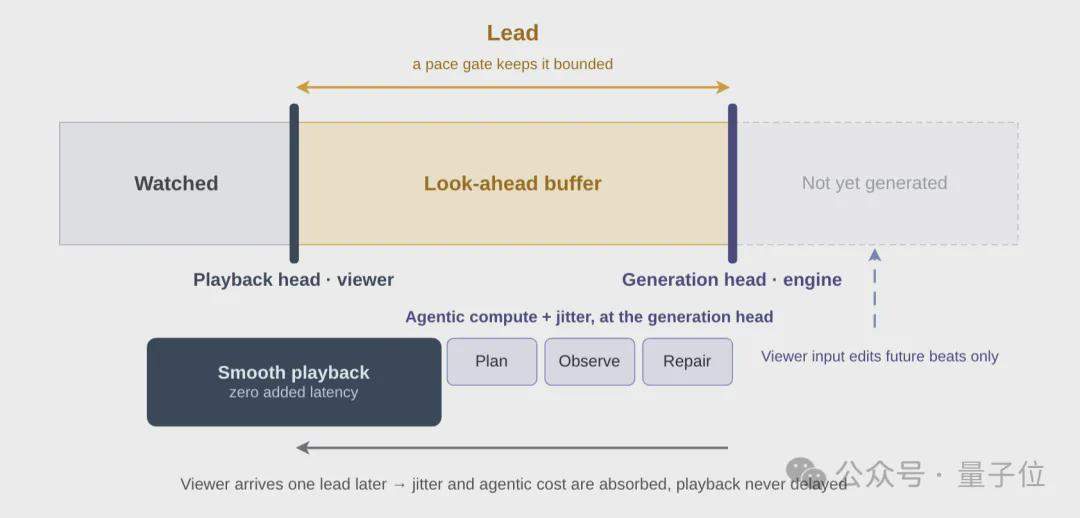
No lado da inferência, é utilizado um framework de inferência Agêntico composto por três controladores inteligentes independentes: o Diretor (Director) é responsável pela narrativa e correção de erros, gerando prompts estruturados batida por batida através de um planejador e monitorando a qualidade da geração através de um observador; o Gerenciador de Cache (Cache Manager) gerencia as estratégias de retenção e exclusão do cache KV, usando a aparência dos personagens e quadros de estabelecimento de cena como âncoras de memória de longo prazo; e o Controlador de Buffer (Buffer Controller) gerencia o buffer de antecipação, equilibrando a capacidade de resposta em tempo real com a interatividade.
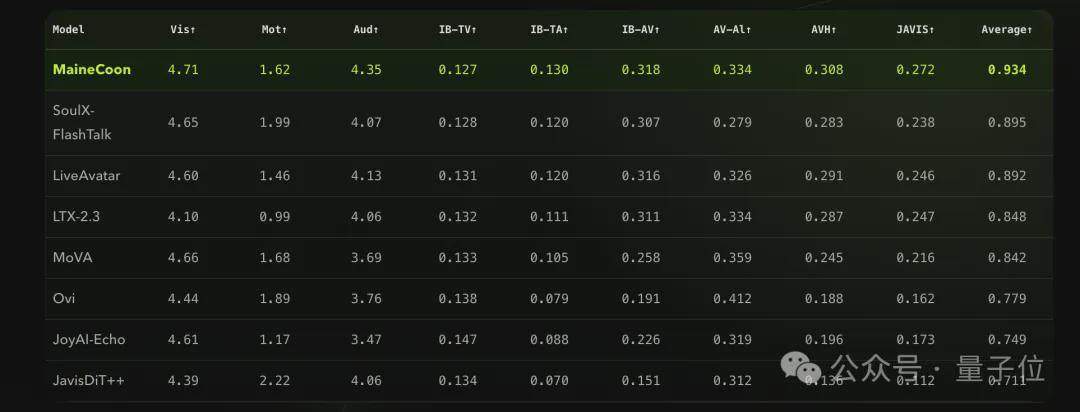
A equipe da Catnip também construiu o primeiro benchmark dedicado a vídeos sociais curtos, o SocialVideo Bench, abrangendo sete cenários: discursos densos, interação entre duas pessoas, performance musical, expressão emocional, dança, desafios criativos e memes sociais. As avaliações mostram que o MaineCoon obteve uma pontuação geral de 0,934, superando 7 modelos populares de geração de áudio e vídeo, como o SoulX-FlashTalk (0,895).
A equipe da Catnip propôs pela primeira vez o conceito de "Modelo de Mundo Social", que acredita incluir três camadas: a camada de percepção (entender as emoções do usuário), a camada de simulação (prever comportamentos sociais) e a camada de renderização (gerar áudio e vídeo em tempo real). O MaineCoon é visto como um avanço na camada de renderização. A equipe planeja, no próximo passo, abandonar o modo de interação half-duplex da IA tradicional, alcançando uma interação bidirecional em tempo real, contínua, entrelaçada e multimodal, semelhante à humana, e promover a implementação do modelo como uma plataforma de conteúdo interativo.
A fundadora da equipe, Yang Shurui, trabalhou anteriormente no TikTok e na PixVerse, sendo responsável pela implementação de produtos de templates e efeitos virais, além de ter experiência como empreendedora em série. O cientista-chefe, Xie Zeke, é professor assistente na Universidade de Ciência e Tecnologia de Hong Kong (Guangzhou), com graduação pela Universidade de Ciência e Tecnologia da China e doutorado pela Universidade de Tóquio. Ele participou de pesquisas de ponta em grandes modelos no Baidu Research Institute e atua como presidente de área em conferências de topo em IA, como NeurIPS, ICLR e ICML. Os demais membros da equipe são principalmente recém-formados.
A equipe da Catnip publicou anteriormente o relatório técnico na plataforma social X, atraindo atenção de várias partes, e a equipe oficial da LTX também buscou ativamente uma colaboração. A equipe revelou que, no início do ano, recebeu rodadas de financiamento anjo de investidores como Sequoia Capital e Mingshi Capital.