
De acordo com pt.wedoany.com-Uma equipe de nove pesquisadores do Weibo lançou o VibeThinker-3B, um modelo de linguagem compacto com 3 bilhões de parâmetros, que em vários testes de referência de raciocínio igualou ou superou sistemas maiores de instituições como Google DeepMind, OpenAI, a empresa de segurança de inteligência artificial Anthropic e DeepSeek.
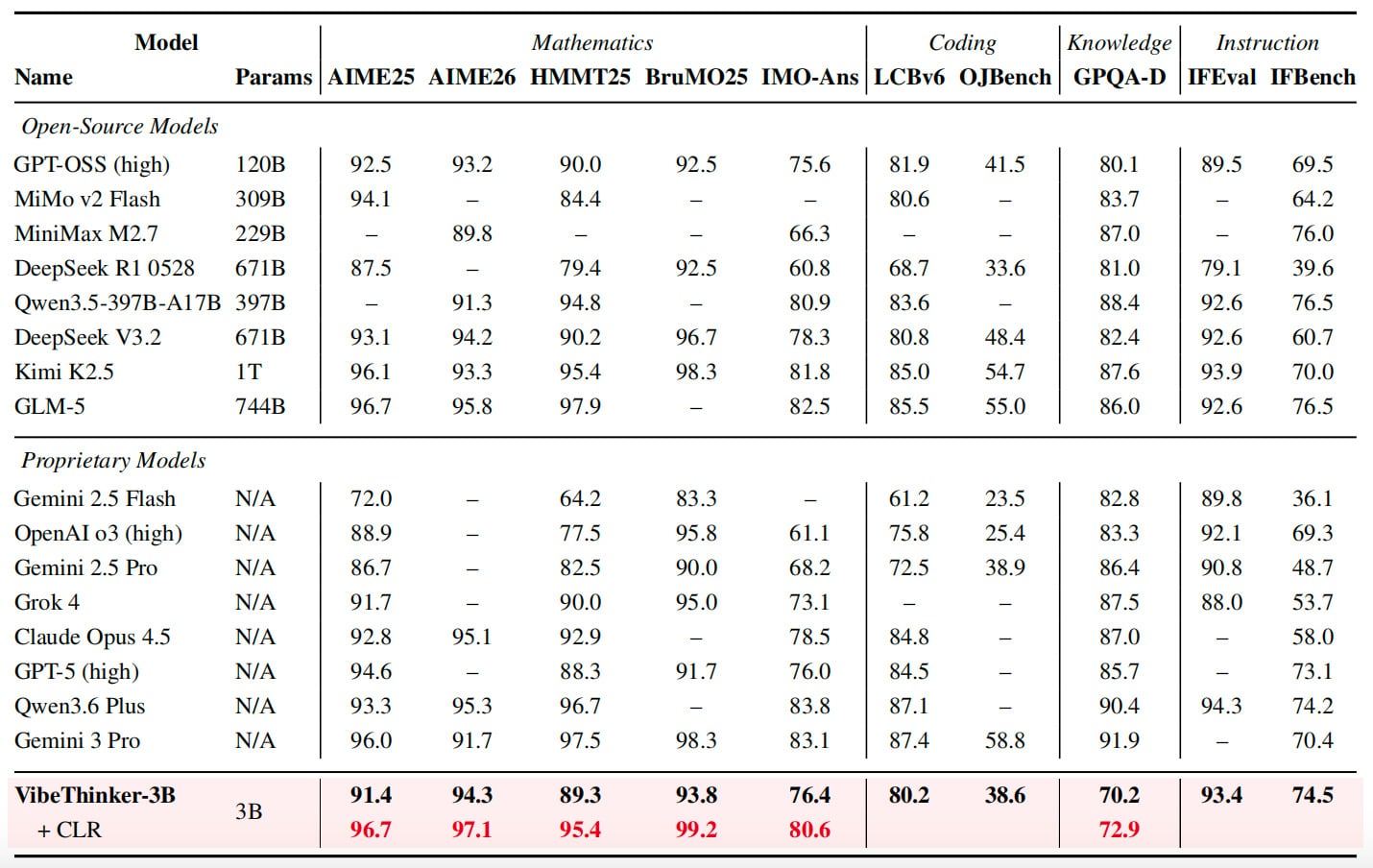
O modelo obteve 94,3 pontos no AIME 2026, comparável ao desempenho do DeepSeek V3.2, que possui 671 bilhões de parâmetros, e superou os 91,7 pontos do Gemini 3 Pro. Através de um método de expansão em tempo de teste chamado "Avaliação de Confiabilidade em Nível de Declaração" (Claim-Level Reliability Assessment), a pontuação do VibeThinker-3B no AIME 2026 foi ainda mais elevada para 97,1.
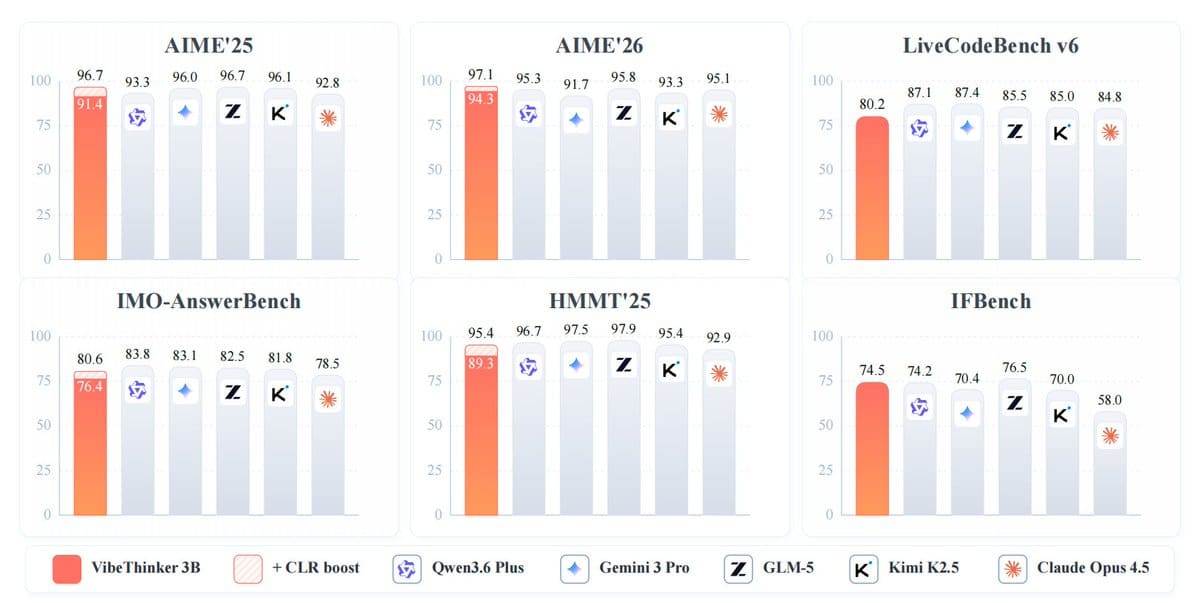
Em outros benchmarks, o VibeThinker-3B obteve 91,4 no AIME 2025, 89,3 no HMMT 2025, 93,8 no BruMO 2025 e 76,4 no IMO-AnswerBench. Em capacidade de codificação, o modelo alcançou uma pontuação Pass@1 de 80,2 no LiveCodeBench v6 e uma taxa de aceitação de submissão de 96,1% em concursos semanais e quinzenais inéditos do LeetCode realizados entre o final de abril e o final de maio de 2026. No teste de seguimento de instruções IFEval, sua pontuação foi de 93,4.
O modelo passou em 123 das 128 questões do LeetCode submetidas na primeira tentativa, superando o GPT-5.2, Doubao Seed 2.0 Pro, Kimi K2.5 e Claude Opus 4.6 nas mesmas condições de avaliação.
O VibeThinker-3B tem aproximadamente 1/224 dos parâmetros do DeepSeek V3.2. Em comparação, o GLM-5 possui 744 bilhões de parâmetros, enquanto o Kimi K2.5 ultrapassa um trilhão. O modelo é pequeno o suficiente para ser executado em laptops de consumo. A equipe de pesquisa acredita que tarefas de raciocínio verificáveis (como matemática e codificação) podem ser comprimidas de forma mais eficaz em modelos menores do que conhecimento factual amplo, chamando isso de "hipótese de cobertura de compressão de parâmetros".
O modelo não se destaca em todas as áreas. No teste GPQA-Diamond, obteve 70,2 pontos, enquanto o Gemini 3 Pro alcançou 91,9 e o Claude Opus 4.5, 87,0. A equipe de pesquisa afirma que isso apoia seu argumento de que modelos compactos podem ter um desempenho robusto em tarefas de raciocínio verificáveis, mas não podem substituir modelos maiores que oferecem uma cobertura de conhecimento mais ampla.
O VibeThinker-3B é baseado no Qwen2.5-Coder-3B da Alibaba e foi aprimorado através de um processo de pós-treinamento de quatro estágios. O primeiro estágio usa ajuste fino supervisionado, direcionado a dados de matemática, codificação, raciocínio STEM, diálogo e seguimento de instruções, passando então para problemas de raciocínio mais difíceis e longos. Nas amostras de treinamento, aquelas com cadeias de raciocínio mais curtas que 5000 tokens foram removidas, assim como problemas que a versão anterior, VibeThinker-1.5B, conseguia resolver em mais de 75% dos casos. O segundo estágio usa Otimização de Política Guiada por Entropia Máxima (MaxEnt-Guided Policy Optimization) com aprendizado por reforço em tarefas de matemática, codificação e STEM. Os pesquisadores usaram uma única janela de 64000 tokens, em vez de expandir progressivamente a janela de contexto, pois a expansão progressiva reduziu o desempenho na escala de 3B. Um estágio independente de "Aprendizado por Reforço Matemático Longo para Curto" (Long2Short Math RL) recompensa respostas corretas mais curtas para reduzir a verbosidade desnecessária. O terceiro estágio destila cadeias de raciocínio bem-sucedidas de checkpoints de aprendizado por reforço de volta para um modelo unificado. O estágio final aplica aprendizado por reforço a tarefas de seguimento de instruções usando verificações baseadas em regras e um modelo de recompensa.
Os resultados dos testes geraram atenção, mas também levantaram preocupações sobre a possibilidade de o modelo estar excessivamente otimizado para os benchmarks. Alguns usuários relataram que o modelo tem desempenho fraco em problemas de codificação do mundo real, incluindo dificuldades com ferramentas de desenvolvimento comuns. Outros questionaram por que o modelo não foi testado em benchmarks de engenharia de software mais amplos. Os pesquisadores afirmam que os dados de treinamento passaram por uma rigorosa descontaminação de benchmarks, incluindo a filtragem de texto sobreposto. As competições recentes do LeetCode oferecem maior proteção contra vazamento de dados, pois ocorreram após qualquer possível data de corte de treinamento. No entanto, os relatos de usuários ainda indicam uma lacuna entre as pontuações dos benchmarks e o desempenho real.
O modelo é lançado sob a licença MIT, e seus pesos podem ser obtidos através do Hugging Face e do ModelScope. No primeiro dia de lançamento, os desenvolvedores já haviam gerado versões quantizadas GGUF e modelos derivados.
O Weibo é mais conhecido por sua plataforma de mídia social do que por pesquisa de IA de ponta. O VibeThinker-3B é o segundo grande lançamento de IA de código aberto da empresa em sete meses. O VibeThinker-1.5B, lançado em novembro de 2025, supostamente superou o DeepSeek R1 original em vários benchmarks de matemática. A equipe afirma que seu custo de pós-treinamento foi de US$ 7.800, enquanto o custo estimado do DeepSeek R1 foi de US$ 294.000.
Os pesquisadores não afirmam que o VibeThinker-3B pode substituir grandes modelos de uso geral. Eles acreditam que, em sistemas de IA híbridos, modelos pequenos podem lidar com tarefas de raciocínio, enquanto sistemas maiores fornecem conhecimento factual. Essa abordagem pode reduzir o custo de implantação de raciocínio avançado e oferecer fortes capacidades de matemática e codificação em dispositivos com hardware limitado. A questão-chave é se o desempenho do modelo em benchmarks pode se traduzir em aplicações confiáveis no mundo real.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com









