De acordo com pt.wedoany.com-Pesquisadores do Laboratório de Inteligência Artificial de Xangai (Shanghai Artificial Intelligence Laboratory) propuseram um novo paradigma chamado "Self-Harness", que permite que agentes baseados em modelos de linguagem de grande escala (LLM) melhorem sistematicamente suas próprias regras operacionais, sem depender de engenheiros humanos ou modelos externos mais fortes.
O desempenho de agentes baseados em LLM depende não apenas do modelo base, mas também de sua estrutura, que inclui prompts do sistema, ferramentas, memória, regras de validação, políticas de tempo de execução, lógica de orquestração e procedimentos de recuperação de falhas. Falhas comuns em agentes geralmente se originam da estrutura, e não do modelo em si. Por exemplo, um agente pode relatar sucesso sem verificar a resposta do modelo, ou repetir tentativas de operações com falha. SWE-agent, Claude Code, Codex e OpenHands são exemplos populares de estruturas.
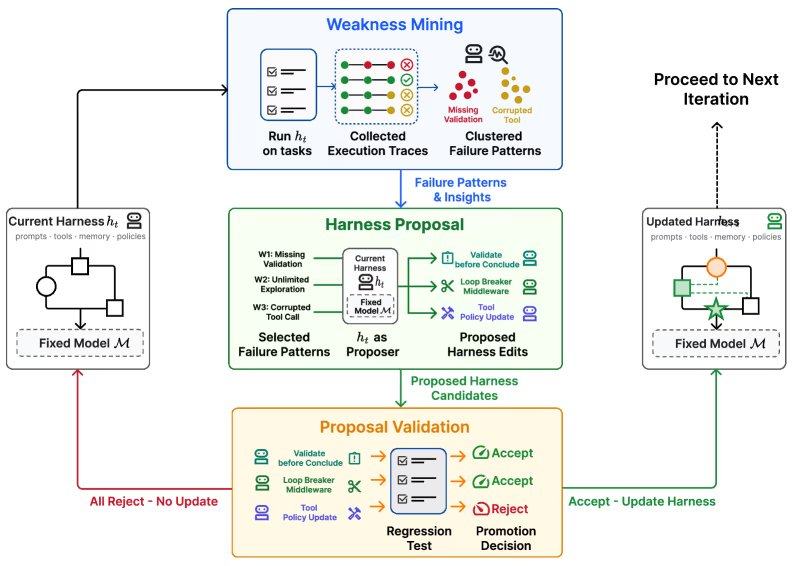
Hangfan Zhang, primeiro autor do artigo sobre Self-Harness, afirmou que o verdadeiro gargalo da engenharia manual de estruturas reside na dependência de depuração ad hoc, em vez de ciclos de feedback sistemáticos. Muitas edições são baseadas em intuição ou em um pequeno número de casos de falha, dificultando o acompanhamento do ritmo acelerado de evolução dos LLMs. O paradigma Self-Harness permite que agentes baseados em LLM alcancem auto-evolução por meio de um ciclo iterativo de três estágios.
O ciclo começa com o estágio de mineração de fraquezas: o agente executa tarefas para gerar trajetórias de execução, classifica trajetórias de falha e detecta padrões de falha específicos do modelo. Em seguida, vem o estágio de proposta de estrutura: o agente usa um papel de "propositor" para gerar um conjunto diversificado e mínimo de modificações na estrutura, cada uma direcionada a um mecanismo de falha específico. Por fim, o estágio de validação de propostas: o sistema avalia as modificações candidatas por meio de testes de regressão, adotando-as apenas se a edição não causar degradação no desempenho das tarefas retidas. Se vários candidatos passarem nos testes, eles são mesclados na próxima versão da estrutura.
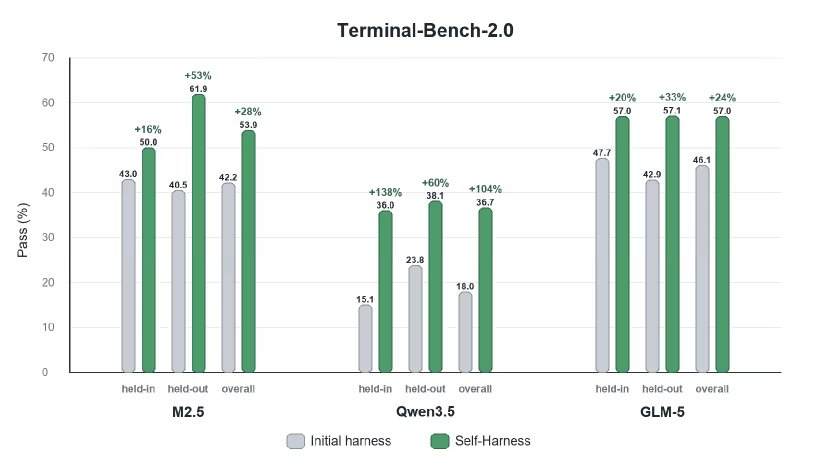
Os pesquisadores avaliaram o Self-Harness no benchmark Terminal-Bench-2.0, que testa execuções baseadas em ferramentas, incluindo gerenciamento de artefatos, uso de comandos, comportamento de validação e recuperação de erros de execução. Eles aplicaram o Self-Harness ao MiniMax M2.5, Qwen3.5-35B-A3B e GLM-5. Os resultados quantitativos mostraram que os agentes melhoraram o desempenho por meio de edições automatizadas da estrutura, com melhorias relativas variando de 33% a 60% entre diferentes modelos nas tarefas retidas.
Os experimentos mostraram que o Self-Harness introduziu alterações direcionadas, refletindo problemas recorrentes de cada modelo durante a execução. Por exemplo, o MiniMax M2.5, sob a estrutura de base, explorava indefinidamente as configurações do conjunto de dados até o tempo limite. O sistema corrigiu isso escrevendo uma regra de "interrupção de loop" (parando após 50 chamadas de ferramenta e redirecionando o método) e adicionando um requisito para criar uma versão inicial o mais cedo possível. O Qwen-3.5 repetia o mesmo comando após encontrar um erro de sobrescrita de arquivo. O sistema introduziu uma disciplina rigorosa de repetição (proibindo a repetição completa de comandos) e um mecanismo para recriar imediatamente artefatos perdidos após erros de arquivo. O GLM-5 tinha dificuldade em manter alterações de ambiente entre comandos diferentes. Sua estrutura autogerada introduziu regras como persistência de variáveis PATH, limitação de computação externa e correção de qualquer verificação de sanidade com falha antes do final da execução.
Zhang destacou que a engenharia automatizada de estruturas requer custos computacionais para geração repetida, avaliação paralela e testes de regressão. O sistema também depende da precisão do pipeline de avaliação, contando com validadores rigorosos e determinísticos nos experimentos. Ele acredita que os melhores alvos de implantação são áreas como codificação, automação de fluxos de trabalho internos e pipelines de dados de DevOps, onde falhas são mensuráveis e tentativa e erro são relativamente seguros. Já áreas como decisões médicas, infraestrutura crítica de segurança ou decisões legais, onde a avaliação é subjetiva e de alto custo, devem evitar a automação completa. À medida que a capacidade dos modelos base aumenta, as estruturas se expandirão para conectar ambientes externos mais ricos. O papel dos engenheiros passará de corrigir manualmente prompts ou chamadas de ferramentas individuais para projetar sistemas de feedback que possibilitem a melhoria dos agentes.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com