De acordo com pt.wedoany.com-A Meta divulgou os resultados da pesquisa sobre interface cérebro-computador Brain2Qwerty v2, que utiliza inteligência artificial para reconstruir linguagem natural a partir da atividade cerebral gerada durante a digitação dos participantes, visando fornecer um método de comunicação textual não invasivo para pessoas que perderam a capacidade de falar ou se mover devido a lesões cerebrais, derrames ou doenças neurológicas.

Diferente das interfaces cérebro-computador que exigem implante cirúrgico de eletrodos, o projeto Brain2Qwerty v2 utiliza equipamentos de magnetoencefalografia (MEG) para registrar os campos magnéticos fracos gerados pela atividade neural do cérebro do paciente, obtendo sinais que são então decodificados por um modelo de IA para gerar informações.
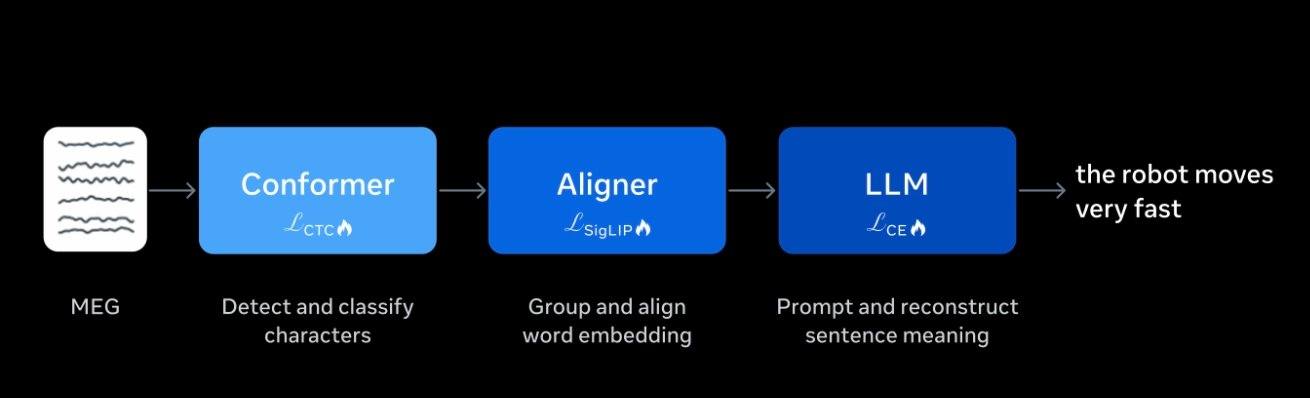
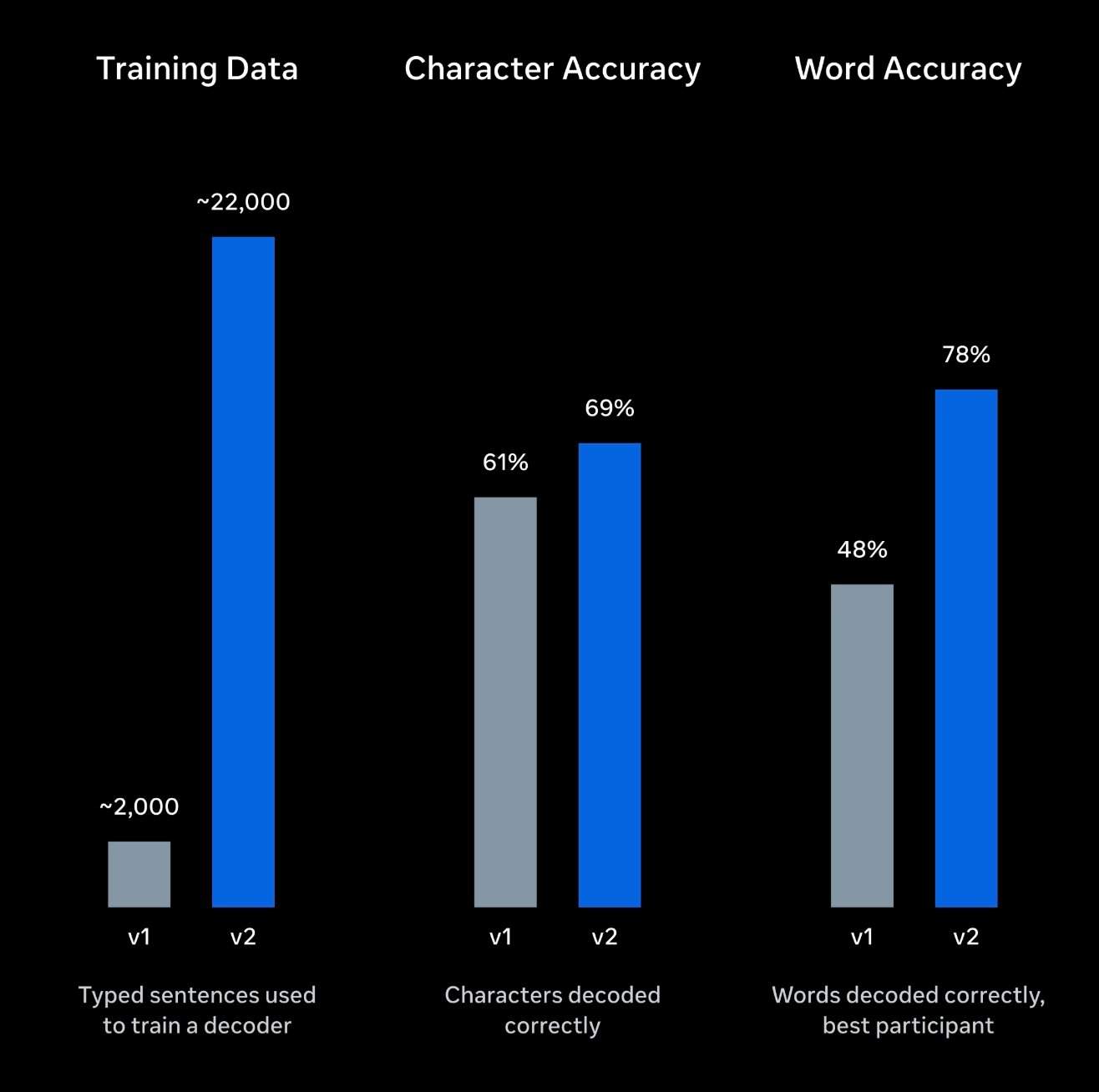
O modelo de IA foi treinado com dados de 9 voluntários, incluindo 22.000 frases e cerca de 10 horas de registros de atividade cerebral. A Meta ajustou o modelo especificamente para que ele possa usar informações semânticas contextuais para completar e corrigir sinais cerebrais com alto ruído, gerando frases mais coerentes e naturais.
De acordo com os resultados experimentais divulgados pela Meta, a precisão média atual de reconhecimento de palavras do Brain2Qwerty v2 é de aproximadamente 61%, correspondendo a uma taxa média de erro de palavras (WER) de cerca de 39%. No participante com melhor desempenho, a precisão atingiu até 78%, e em mais da metade das frases testadas, houve no máximo 1 erro por frase.
A tecnologia ainda apresenta limitações significativas. Os experimentos foram conduzidos em ambientes altamente controlados, exigindo que os pacientes utilizem equipamentos MEG de grande porte em nível laboratorial para obter sinais magnetoencefalográficos precisos. Em termos de custo do equipamento, volume e cenários de uso diário, ainda há uma grande distância para a aplicação prática.
Atualmente, a Meta já disponibilizou no GitHub os códigos de treinamento do Brain2Qwerty v1 e v2. A instituição parceira Basque Center on Cognition, Brain and Language também tornou público o conjunto de dados do v1, e o conjunto de dados do v2 será aberto após a aceitação formal do artigo.