

De acordo com pt.wedoany.com-Com a desaceleração da escala de densidade de transistores, a embalagem avançada tornou-se a principal via de expansão. No entanto, os aceleradores de inteligência artificial são volumosos e exigem velocidades de interconexão extremamente altas, fazendo com que a própria embalagem enfrente seus limites. Os interpositores redondos limitam o tamanho da embalagem e a utilização do wafer, a tecnologia HBM4E dobra o número de I/Os enquanto aumenta a velocidade, e embalagens de múltiplos quilowatts tornam as arquiteturas de resfriamento tradicionais insustentáveis.
O ECTC é o principal evento de tecnologia de embalagem da indústria. As publicações deste ano estão intimamente relacionadas a produtos comerciais que serão lançados em breve. A Intel delineou a integração EMIB-T, a escala do tamanho da embalagem e o roteiro de desenvolvimento futuro. A Marvell mostrou como remover a lógica de interface do acelerador através de HBM personalizado, ao mesmo tempo que encurta o roteamento da embalagem. A TSMC e a Microsoft integram refrigerante diretamente no silício, enquanto a Marvell e a Lightmatter integram interconexões ópticas na embalagem.
Esta visão geral abrange as tecnologias do ECTC 2026 com maior probabilidade de moldar as soluções de aceleradores de IA nos próximos anos.
Intel EMIB-T
A Intel é a maior palestrante corporativa na feira ECTC. Seu foco principal é o EMIB-T. Este é o chip EMIB de próxima geração que utiliza tecnologia Through-Silicon Via (TSV). Após o lançamento inicial, a Intel refinou ainda mais a arquitetura e o roteiro, incluindo passo de bump menor, tamanho de embalagem maior e funcionalidade de ponte. Sua demonstração indica que o EMIB-T está previsto para ser usado no TPU v9 do Google e é a alternativa mais confiável à plataforma CoWoS da TSMC no campo de aceleradores de IA de grande embalagem.
Chip de teste de extensão EMIB-T, com teor de silício equivalente a duas vezes a retícula. Imagens de microscopia eletrônica de varredura em vista superior mostram passos de bump de 110, 55 e 36 micrômetros.

A Intel já verificou a tecnologia EMIB-T em chips encapsulados com silício de tamanho de retícula dupla, com passo de bump de 36/35 micrômetros. Em comparação com o passo de 45 micrômetros usado na embalagem Granite Rapids, a densidade de bump aumentou 65%. O Granite Rapids-AP é uma embalagem grande, medindo 70 mm × 105 mm, com área ligeiramente inferior a 9 retículas. Atualmente, a verificação para o passo de bump de 36/35 micrômetros está sendo expandida para encapsulamento de silício de 4,5 vezes o tamanho da retícula, com o objetivo de concluir a certificação até o final de 2026.

A próxima etapa de passo também está em andamento, com a Intel testando um passo de bump de 25 µm, baseado em um chip composto por dois chips de silício de 1 retícula conectados por uma única ponte EMIB-T de 3 mm × 18 mm.
Reduzir ainda mais o tamanho se tornará mais difícil. Abaixo de 25 µm, o volume de solda em cada esfera de solda se torna muito pequeno. A probabilidade de curtos-circuitos, circuitos abertos e perda de rendimento devido ao processo de montagem aumenta significativamente. O EMIB-T pode continuar a reduzir o tamanho, mas o fator limitante muda da densidade de roteamento da ponte para a formação de esferas de solda, precisão de posicionamento e rendimento de montagem.
A Intel também demonstrou os limites de tamanho da embalagem EMIB-T. Embora embalagens de tamanho de painel completo sejam possíveis, a Intel definiu a embalagem de painel de um quarto como meta prática. Eles mostraram uma amostra de teste de 240 mm × 240 mm, com área equivalente a aproximadamente 67 máscaras de litografia. No entanto, as amostras no estande apresentaram empenamento severo. Neste tamanho, a ponte é apenas parte do problema. O manuseio do substrato, empenamento, precisão de sobreposição e padronização em nível de painel tornam-se os principais fatores limitantes. A Intel também está avaliando tecnologias de litografia avançada para garantir precisão de sobreposição suficientemente alta para esses substratos grandes em tamanhos de painel de um quarto ou mesmo painel completo.
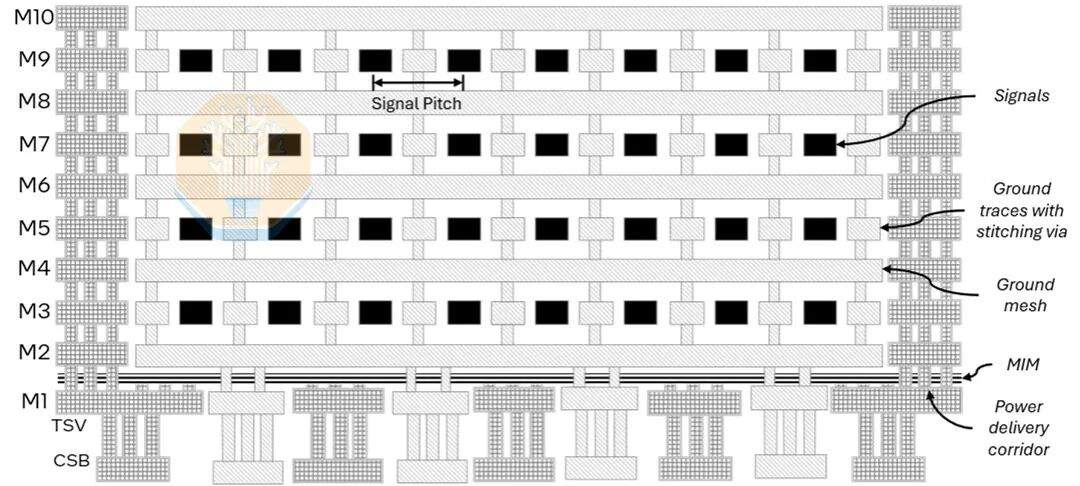
Embora o passo de bump e o tamanho da embalagem sejam importantes, o circuito de ponte é igualmente crucial. O EMIB-T é muito mais complexo que o EMIB usado nos produtos atuais. Ele adiciona TSVs, mais camadas de metal, grades de alimentação e camadas de capacitor MIM, permitindo que o circuito de ponte transmita simultaneamente sinais de alta densidade e alimentação vertical. A Intel mostrou uma imagem de seção transversal contendo 10 camadas de metal (incluindo 4 camadas de roteamento) e um capacitor MIM entre M1 e M2. A Intel destacou suas melhorias para o HBM4E.
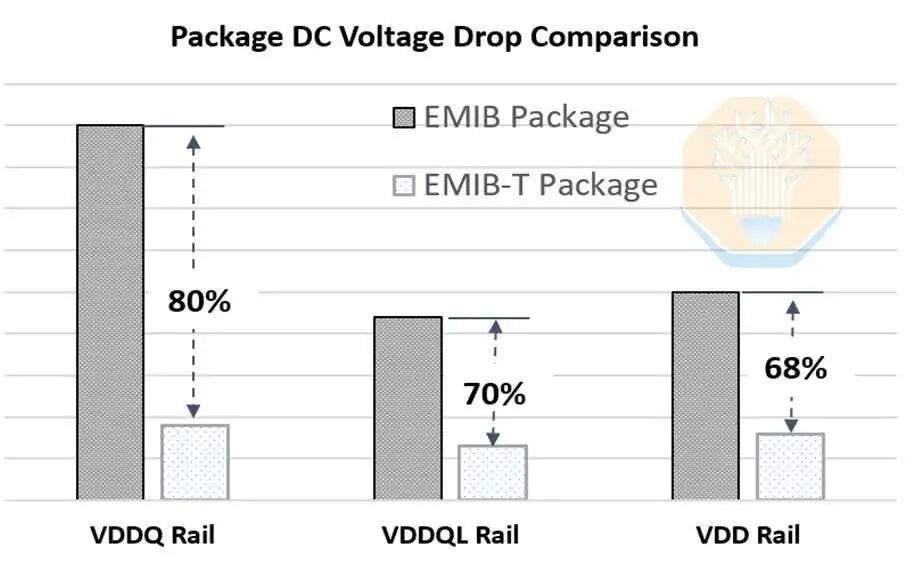
O "T" em EMIB-T significa TSV (Through-Silicon Via). Sua função é fornecer alimentação. No EMIB tradicional, a alimentação nas áreas não-ponte é transmitida verticalmente através do substrato, enquanto a alimentação perto da área da ponte deve se difundir lateralmente para o roteamento da embalagem e do chip. Ao usar TSVs na área da ponte, a alimentação pode ser transmitida diretamente através da área da ponte, encurtando significativamente o caminho da corrente. A Intel afirma que o uso desses TSVs pode reduzir a queda de tensão DC em 68% a 80%.
A dificuldade do HBM4E reside no fato de que a interconexão deve aumentar simultaneamente a densidade do sinal e a capacidade de fornecimento de energia. O HBM4 tem o dobro do número de pinos do HBM3, e a PHY requer trilhos de alimentação adicionais, como VDDQ e VDDQL. Esses trilhos de alimentação ocupam parte do espaço de roteamento de sinal, aumentando assim a densidade do sinal no espaço restante.
Para resolver este problema, a Intel não usa o mesmo método de roteamento para todos os canais HBM. Ela coloca os caminhos de sinal mais longos em camadas com roteamento mais limpo. Na camada M9, apenas cerca de 28% do comprimento do canal mais longo passa pela área de roteamento mais densa, enquanto em camadas inferiores como M3, essa proporção sobe para cerca de 84%, mas esses canais são mais curtos. Isso evita que a diafonia e a perda de inserção sejam causadas principalmente pelas áreas de pior roteamento.
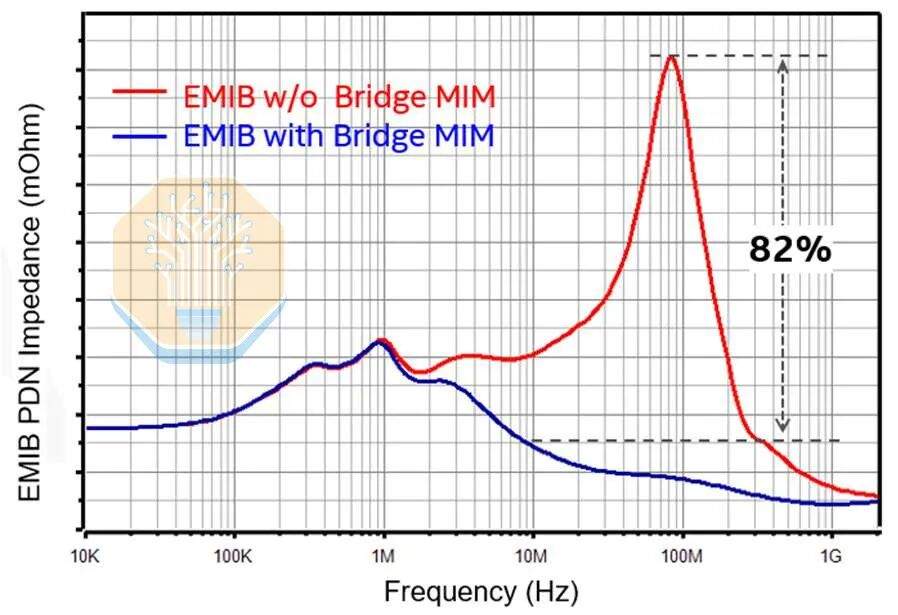
A transmissão de energia também foi transferida para a camada de ponte. O EMIB-M introduziu capacitores Metal-Isolante-Metal (MIM) entre M1 e M2, e o EMIB-T melhora isso. A Intel divulgou uma densidade de capacitância de 500 nF/mm², aproximadamente equivalente ao capacitor MIM do Intel 18A. A Intel afirma que, em comparação com uma embalagem EMIB-T sem capacitores MIM de ponte, esses capacitores de ponte podem reduzir a impedância AC da rede de distribuição de energia (PDN) em mais de 82%.
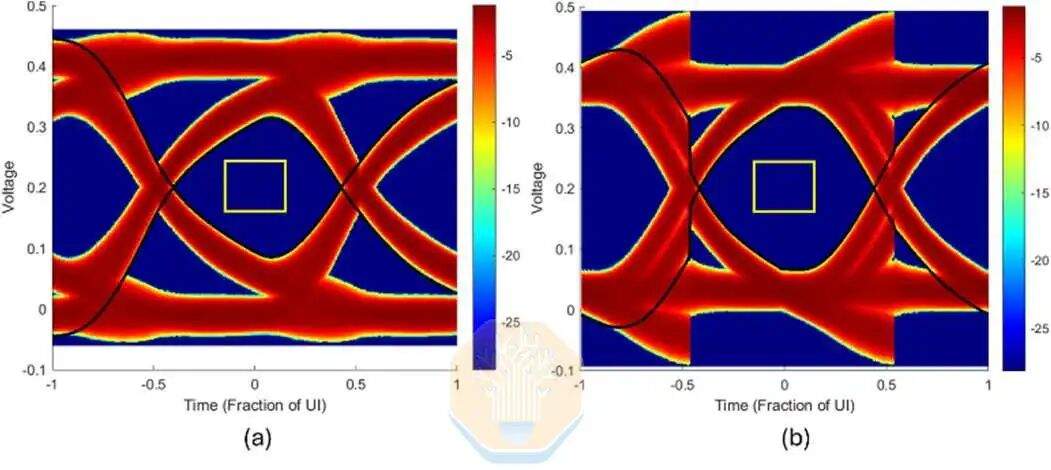
A Intel também realizou simulações do EMIB-T com HBM4E. A uma taxa de 12 Gb/s, sem usar equalização no receptor, a largura do olho da UI da Intel era de cerca de 67%. Com o uso de um equalizador de decisão realimentada de um único tap (DFE), esse valor pode ser aumentado para aproximadamente 72,5%. O DFE é um circuito do lado do receptor usado para reduzir a interferência de bits anteriores após o sinal passar pelo canal da embalagem.
A Intel também simulou velocidades de transmissão mais altas, de 12,8 Gb/s, 14 Gb/s e 16 Gb/s. Em todas as velocidades testadas, a largura da janela da interface do usuário manteve-se acima de 60%, com uma ligeira queda na capacitância do pad.
O roteiro EMIB da Intel vai além da tecnologia de ponte passiva que contém apenas roteamento e capacitores. Versões futuras incluirão capacitores MIM de ponte de maior densidade, chips de ponte de alta proporção de aspecto em tamanhos maiores, passo de bump inferior a 25 micrômetros, pontes ativas e reguladores de tensão integrados dentro do chip EMIB. A Intel também divulgou o conceito de capacitores de trincheira profunda (DTC) embutidos no núcleo do substrato e capacitores eMIM-T de >2500 nF/mm² embutidos sob o substrato, embora essas tecnologias ainda não tenham sido vistas em produtos EMIB já enviados.
O EMIB-T ainda está atrás da plataforma CoWoS da TSMC em vários aspectos. A TSMC já alcançou a integração DTC/eDTC e foi mais longe na integração de reguladores de tensão e interconexão local de silício ativa (LSI). O EMIB-T está reduzindo a diferença, mas a Intel ainda está alcançando um ecossistema que já opera em grande escala há anos.
HBM Personalizado da Marvell
No Dia do Analista da Indústria da Marvell em 2024, a Marvell anunciou o HBM personalizado. Na época, era uma declaração vaga, sem detalhes técnicos. O design do HBM sempre girou em torno da compatibilidade com JEDEC: pilhas de DRAM padrão fornecidas por fornecedores de memória, PHY HBM padrão no acelerador e uma interface larga fixa entre eles. Na Hot Chips 2025, a Marvell mostrou o layout do chip base personalizado.

No ECTC, a Marvell finalmente forneceu detalhes em nível de embalagem do HBM4E personalizado.
A especificação JEDEC fixa a interface entre a pilha HBM e o host. Isso é bom para a interoperabilidade: o HBM de qualquer fabricante de memória pode ser pareado com qualquer host compatível. No entanto, isso é ruim para consumo de energia, desempenho e área. O ASIC host deve implementar uma PHY HBM padrão e usar um layout de pad padronizado e regras de roteamento para rotear uma interface paralela muito larga. À medida que o tamanho da embalagem aumenta e a velocidade do HBM aumenta, esse limite fixo torna mais difícil otimizar o litoral, a densidade de roteamento, o fornecimento de energia e a integridade do sinal.

A tecnologia HBM personalizada não requer nenhuma alteração no chip de núcleo DRAM. Em vez disso, um chip base personalizado com uma interface interchip otimizada é fabricado usando um processo lógico avançado. Este chip base personalizado pode integrar o controlador HBM, funções de gerenciamento e monitoramento, lógica personalizada e uma interface estendida.

A Marvell afirma que isso reduz a área ocupada pelo ASIC host para a PHY HBM e lógica relacionada em cerca de 60%, liberando diretamente mais espaço para computação, cache ou I/O. Esta interface personalizada move a maior parte da interface do lado da memória para o chip base HBM.
O exemplo da Marvell usa 1024 canais a uma taxa de 32 Gb/s, atingindo 4,1 TB/s, equivalente a uma interface JEDEC HBM4(E) de 2048 bits a 16 Gb/s.
O roteamento da embalagem também se torna mais fácil, com a interface personalizada reduzindo o comprimento do canal do interpositor de 6,5 mm para 1,5 mm, permitindo que a Marvell aumente a largura de banda mantendo as mesmas 9 camadas de roteamento e 2/2 µm de linha/espaçamento (L/S).
No exemplo da Marvell, um interpositor de camada de redistribuição orgânica (RDL) é usado em vez de silício, reduzindo o custo da embalagem. O RDL orgânico tem largura de linha/espaçamento muito menor do que o interpositor de silício no CoWoS-S ou as pontes de silício no CoWoS-L e EMIB-T, o que aumenta a dificuldade de layout. A Marvell depende de blindagem personalizada e padrões de roteamento em diferentes partes para maximizar a densidade de largura de banda enquanto controla a diafonia.

Na GTC, a Nvidia anunciou que o Feynman usará HBM personalizado. As razões da Nvidia são provavelmente semelhantes às da Marvell: maior largura de banda, menor consumo de energia e menos área de chip do acelerador dedicada ao HBM. Cerca de 16% da área do chip GPU Rubin é usada para lógica e PHY relacionadas ao HBM. O HBM personalizado pode permitir que a Nvidia transfira a maior parte do fardo para o chip base HBM.
O HBM personalizado também suporta interfaces estendidas além do link HBM padrão. O chip base pode atuar como um controlador de memória auxiliar e distribuir o tráfego para memória adicional, em vez de forçar todo o tráfego de memória a passar pelos canais limitados da borda do chip acelerador. Essa memória adicional pode ser LPDDR de maior capacidade e menor largura de banda, ou mesmo uma segunda camada de HBM. Isso permite que o acelerador expanda a capacidade de memória sem ocupar os valiosos canais de borda do chip necessários para I/O externo. Isso é particularmente importante para as próximas GPUs MI450 e futuras MI500 da AMD, que suportarão LPDDR para aumentar a capacidade de memória.
Interpositor HBM da Samsung
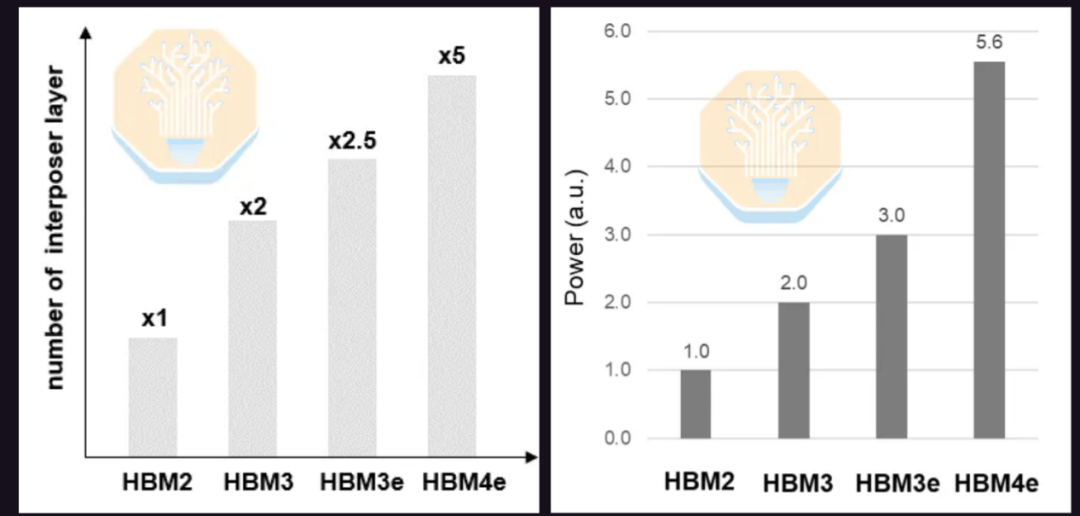
A Samsung também demonstrou sua solução HBM4E baseada em interpositor. O HBM4E aumenta a taxa de transferência de dados para 12 Gb/s e acima, e dobra o número de pinos de I/O, aumentando a complexidade do roteamento. O HBM4E pode exigir o dobro de interpositores em comparação com o HBM3E e cinco vezes mais em comparação com o HBM2. Devido ao aumento no número de pinos de I/O e na taxa de transferência de dados, espera-se que o consumo de energia também aumente 86% em relação ao HBM3E e 5,6 vezes em relação ao HBM2.
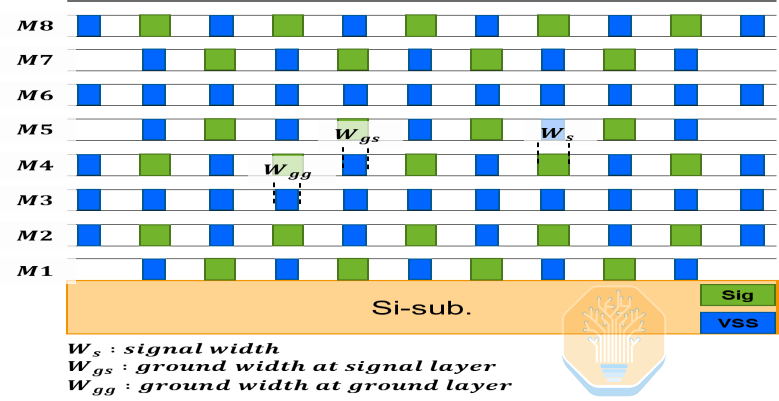
A Samsung propôs uma solução de interpositor de silício de 8 camadas, que, segundo eles, reduz o número de camadas em 20% em comparação com a demanda estimada. O interpositor usa um padrão de intercalação repetitivo de dois sinais/um terra para blindar sinais de alta velocidade, com 75% das camadas usadas para roteamento de sinal.
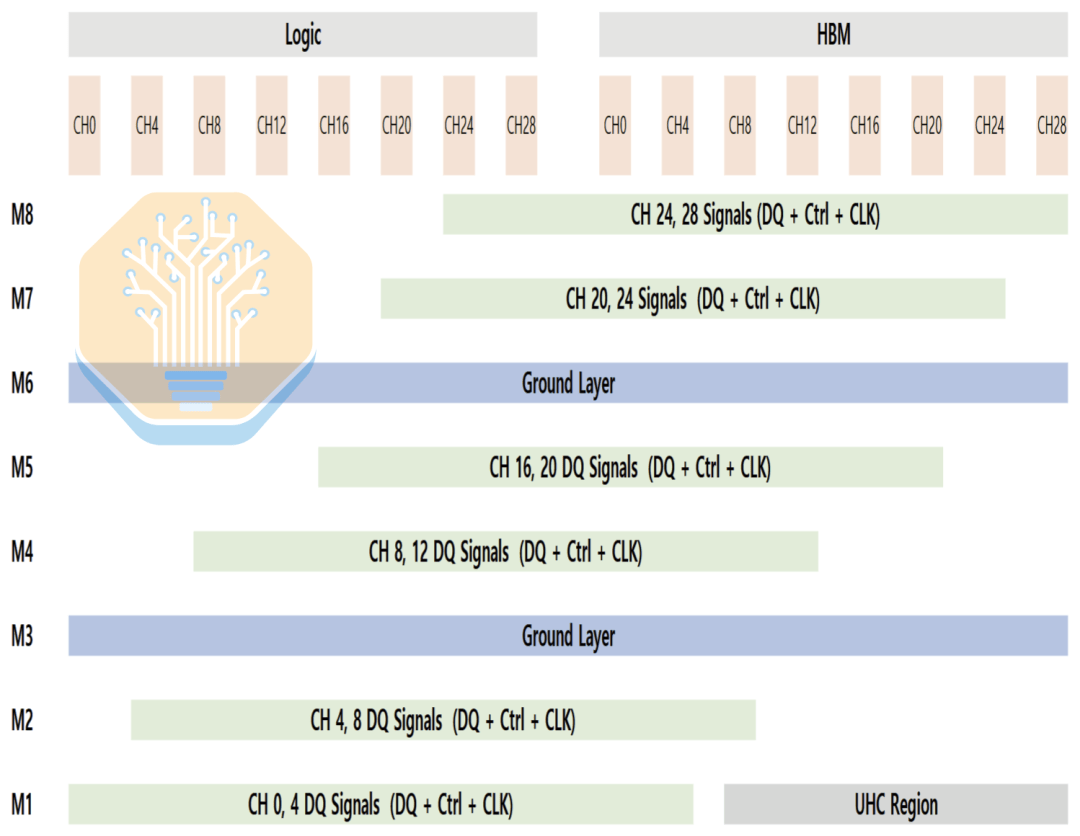
Outra característica chave do interpositor é o capacitor de ultra-alta densidade (UHC). A Samsung não especifica claramente a estrutura do capacitor, mas eles são provavelmente semelhantes aos capacitores MIM do EMIB-T da Intel ou aos capacitores DTC do CoWoS da TSMC. O capacitor UHC só pode ser colocado na camada M1, que também é usada principalmente para roteamento de sinal, portanto a área disponível é limitada.
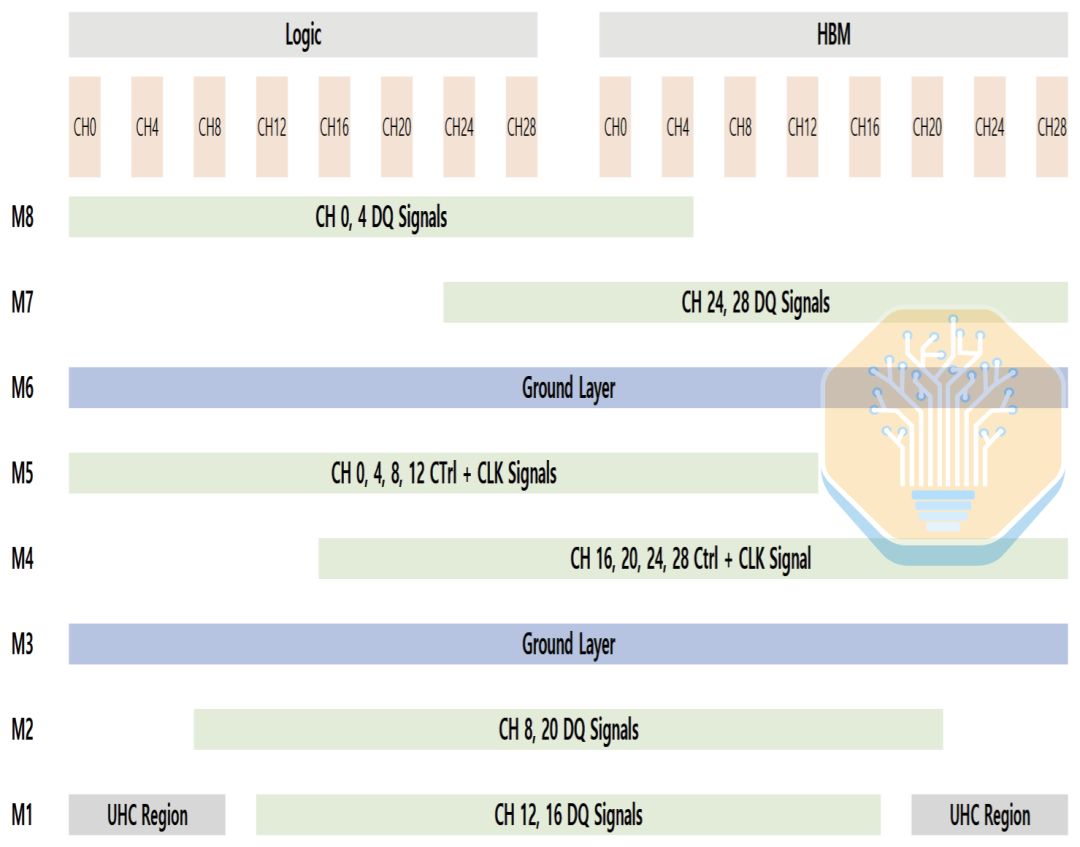
Se o roteamento for desequilibrado, o capacitor será empurrado para um lado da interface, resultando em desempenho desigual da rede de distribuição de energia (PDN) entre o lado lógico e o lado HBM. O layout da Samsung redistribui o roteamento para a camada M1 e outras camadas, permitindo que o capacitor UHC seja distribuído mais uniformemente por toda a interface. Isso reduz a impedância PDN e o ruído de tensão, mantendo a densidade de roteamento controlável.
Térmica de Hibrid Bonding HBM da Samsung
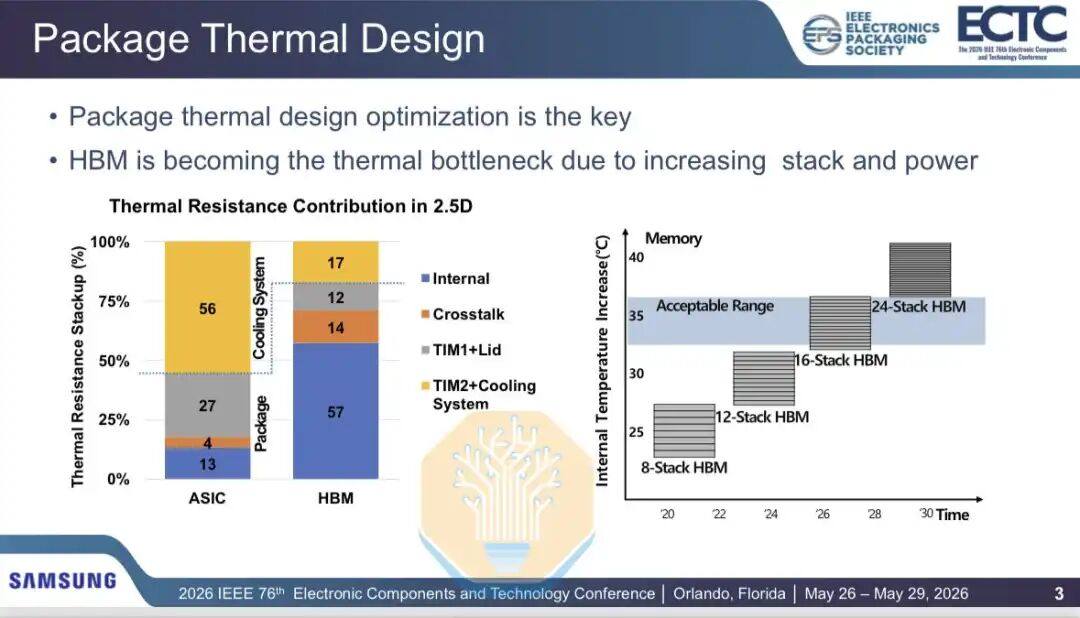
A Samsung também discutiu os problemas térmicos do HBM, particularmente a tecnologia de hibrid bonding. As pilhas HBM estão se tornando cada vez mais altas e rápidas, enquanto o consumo de energia do chip lógico abaixo delas também está aumentando. Para HBM de 16 camadas, a resistência térmica ainda é aceitável, mas à medida que as futuras gerações de produtos se movem para HBM de 20 e 24 camadas, novas soluções serão necessárias.
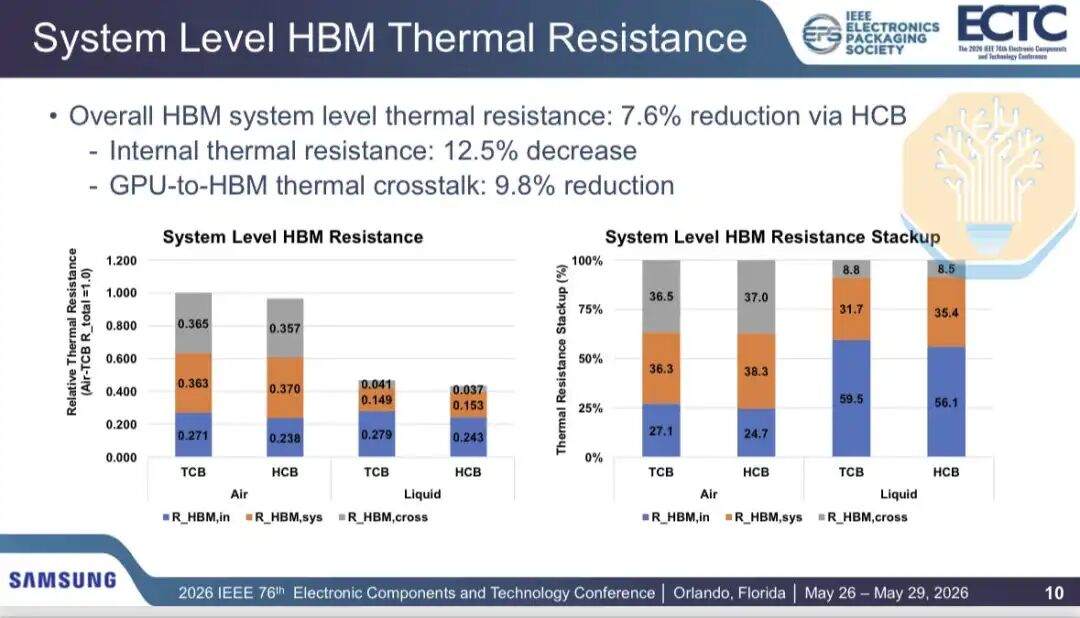
A Samsung comparou o desempenho térmico do HBM entre a termocompressão (TCB) e a hibrid copper bonding (HCB) em uma embalagem GPU 2.5D (contendo 2 chips GPU e 8 pilhas HBM, semelhante à arquitetura Nvidia Blackwell). Os resultados mostram que o resfriamento a ar pode reduzir a resistência térmica interna do HBM em 12,2%, e o resfriamento líquido pode reduzi-la em 12,9%. A resistência térmica total do HBM pode ser reduzida em 3,5% com resfriamento a ar e 7,7% com resfriamento líquido.
Como o HCB visa apenas parte da rede térmica, a melhoria não é uniforme. A Samsung divide o caminho térmico em resistência térmica interna, resistência térmica em nível de sistema e diafonia GPU-para-HBM. A resistência térmica interna e a diafonia foram reduzidas em cerca de 12,5% e 9,8%, respectivamente, mas a resistência térmica em nível de sistema, incluindo material de interface térmica e dissipador, aumentou cerca de 2,3%.
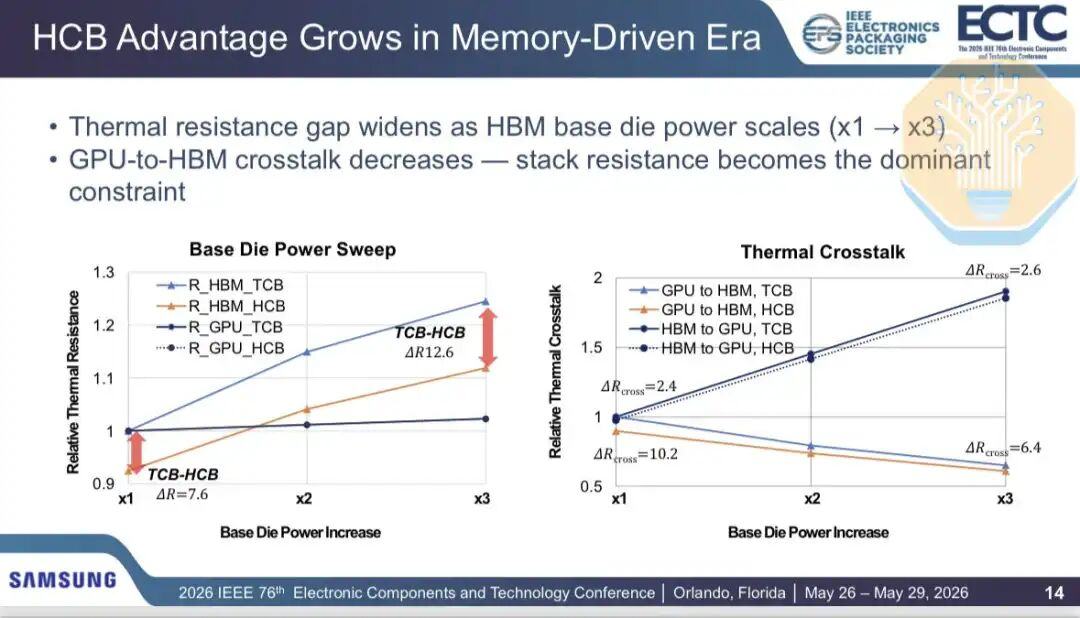
À medida que mais energia é transferida para o substrato HBM (por exemplo, em cargas de trabalho com uso intensivo de memória), o gargalo térmico muda. Isso é particularmente importante para HBM personalizado, onde o controlador de memória e mais circuitos lógicos são integrados ao substrato. A proporção da diafonia GPU-para-HBM na resistência térmica total diminui, caindo de 13% quando o consumo de energia do substrato dobra para 5% quando o consumo de energia do substrato triplica.
A Samsung afirma que a tecnologia HCB pode permitir aumentar a temperatura do ar de entrada ou aumentar a potência da embalagem. De acordo com suas estimativas, com a tecnologia HCB, a temperatura do ar de entrada pode ser aumentada em 1-2°C com a potência da embalagem mantida constante; ou a potência da embalagem pode ser aumentada em cerca de 4% com a temperatura mantida constante. A Samsung também estima que a potência de dissipação de calor será reduzida em cerca de 7%.
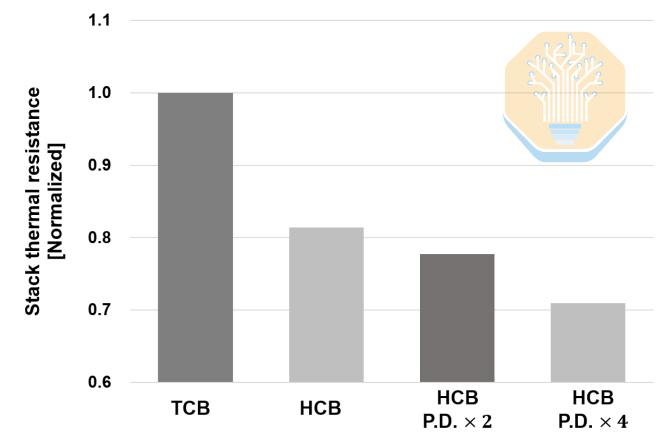
A Samsung também estudou separadamente o impacto do HCB no nível da pilha. A melhoria aqui é maior: em comparação com o TCB, o HCB de referência pode reduzir a resistência térmica da pilha em cerca de 19%. Aumentando o número de pads HCB, a redução da resistência térmica pode chegar a 22,3% com um aumento de 2x na densidade de pads e 29,1% com um aumento de 4x na densidade de pads.
Resfriamento Microfluídico
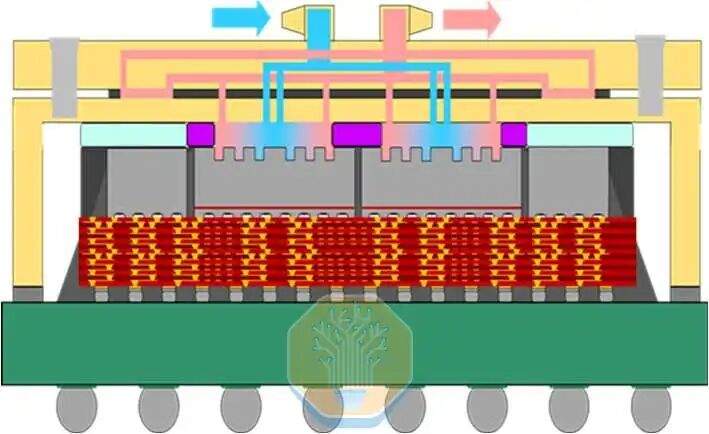
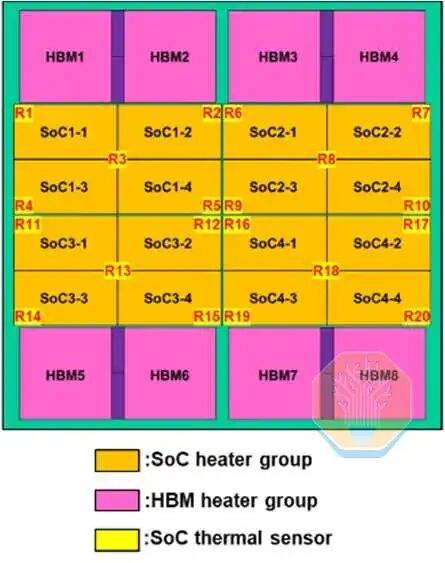
A TSMC demonstrou tecnologia de resfriamento direto de silício em um chip CoWoS-R, usado em uma plataforma de teste grande semelhante a uma GPU. O CoWoS-R difere do CoWoS-S por usar materiais orgânicos em vez de um interpositor de silício. O CoWoS-R foi escolhido por sua melhor tolerância ao empenamento e compatibilidade de processo. A plataforma de teste usa um interpositor de 3,3 vezes a retícula, contendo 4 chips SoC e 8 pilhas HBM. Cada chip SoC consiste em 4 grupos de aquecedores SoC, que juntos cobrem aproximadamente metade da área do interpositor.
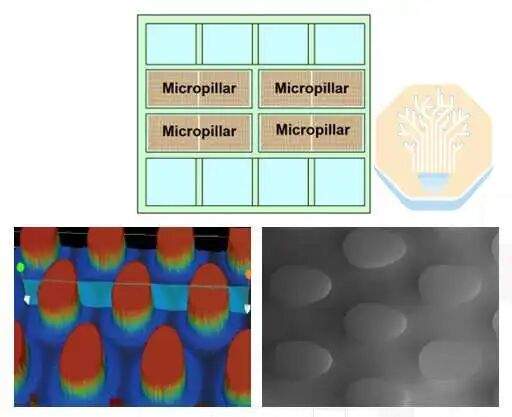
A TSMC comparou três soluções: embalagem tradicional com tampa e cold plate, embalagem sem tampa com cold plate e seu design de embalagem direta de silício com micropilares. As soluções com e sem tampa ainda usam cold plate tradicional e material de interface térmica (TIM). A última solução forma micropilares diretamente na parte traseira do chip SoC.
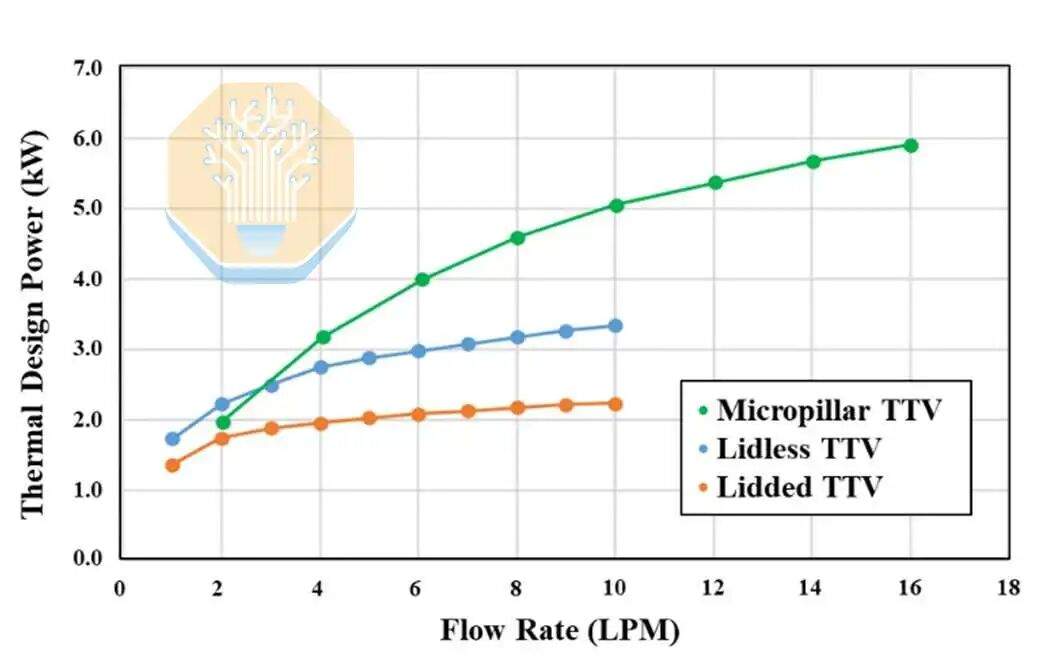
Com resfriamento convencional, a uma vazão de 1-2 litros por minuto (LPM), a embalagem com tampa dissipa 1,9-2,3 kW, enquanto a embalagem sem tampa dissipa 2,5-3,0 kW, usando água deionizada a 40 °C como refrigerante. Ambas as soluções saturam após uma vazão superior a 4 LPM, pois o material de interface térmica (TIM) se torna o gargalo.
O veículo de teste com micropilares teve desempenho comparável ao cold plate sem tampa a 2 LPM, superando-o em vazões mais altas, dissipando 4 kW a 4 LPM e 5,3 kW a 8 LPM. A TSMC relata que a potência de dissipação excedeu 5 kW uniformemente em todo o veículo de teste. A estrutura de micropilares aproxima o refrigerante líquido da fonte de calor, facilitando o desempenho da dissipação de calor.
No entanto, a estrutura de micropilares não é perfeita. A TSMC teve que formar os micropilares após a conclusão do processo de chip-on-wafer (CoW), evitando danificar a estrutura CoWoS-R e desenvolvendo novos materiais de vedação para garantir que o refrigerante permanecesse selado apesar do empenamento da embalagem e da incompatibilidade do coeficiente de expansão térmica. As amostras de teste passaram no teste de nível de sensibilidade à umidade 4 (MSL4) sem vazamento de hélio ou delaminação do selante.
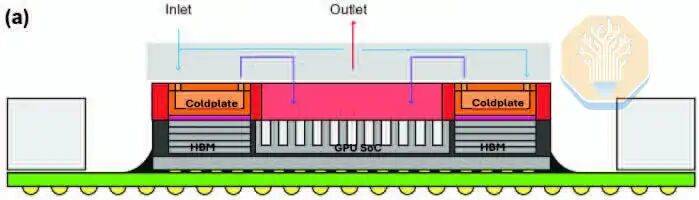
A abordagem de resfriamento da Microsoft difere da da TSMC na estrutura de resfriamento. A TSMC usa micropilares de silício, enquanto a Microsoft usa microcanais retos gravados no silício da GPU. A Microsoft não usou uma plataforma de teste térmica, mas testou diretamente em uma GPU Nvidia GH200. Isso pode permitir que a Microsoft capture com mais precisão a distribuição térmica real e os pontos quentes. A Microsoft testou várias cargas de trabalho na GPU, como HPCG e HPL, cada uma com diferentes características de pressão computacional e de memória.
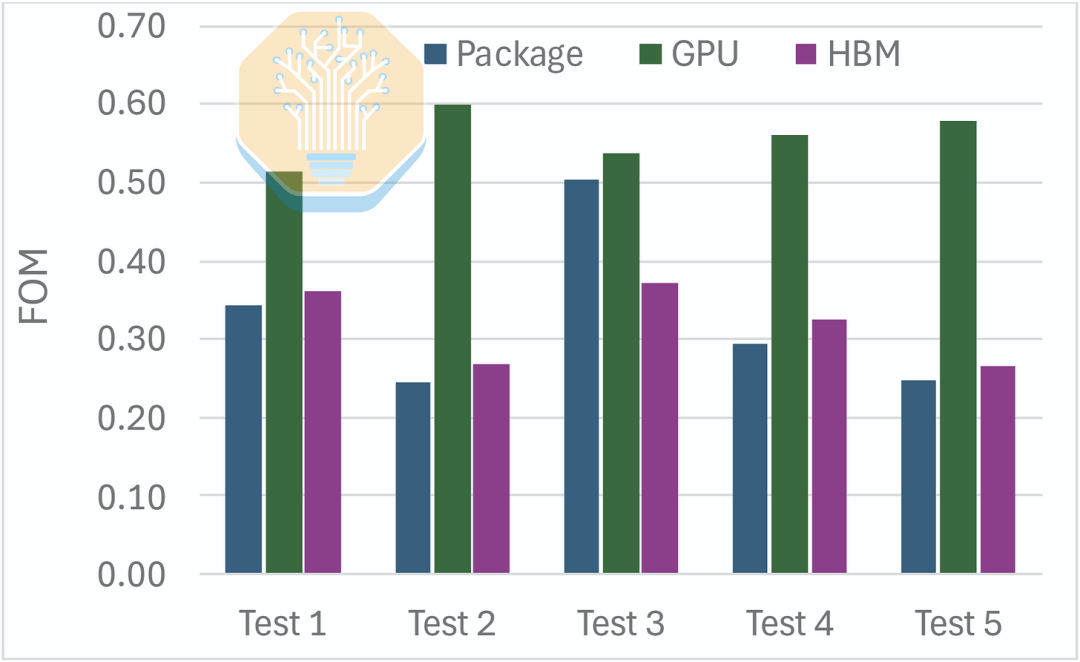
Sob essas cargas de trabalho, a Microsoft relatou uma redução de 51-60% na resistência térmica da junção à entrada da GPU a uma vazão de 1 LPM. A melhoria para o HBM foi menor, de 27-37%, pois ainda é resfriado através do cold plate e material térmico. No geral, isso resultou em uma redução de 50% na resistência térmica da embalagem.
A Microsoft também apresentou alguns dados preliminares de confiabilidade. Embora o desempenho térmico seja importante, a implantação em data centers também requer alta confiabilidade e baixo tempo de inatividade. Ao longo de 6 meses, a Microsoft registrou apenas 9 eventos potenciais de bloqueio em aproximadamente 4370 observações. A taxa de bloqueio diminuiu ao longo do tempo, indicando instabilidade inicial na instalação seguida por uma operação mais estável. Mesmo após 6 meses, não houve corrosão mensurável do silício nos microcanais. No nível do nó, o GH200 completou com sucesso 3 semanas de testes de benchmark repetidos, seguidos por 1 semana de operação contínua com potência de embalagem estável. A Microsoft ainda está testando o tempo médio entre falhas (MTBF) e a disponibilidade no nível do cluster.










