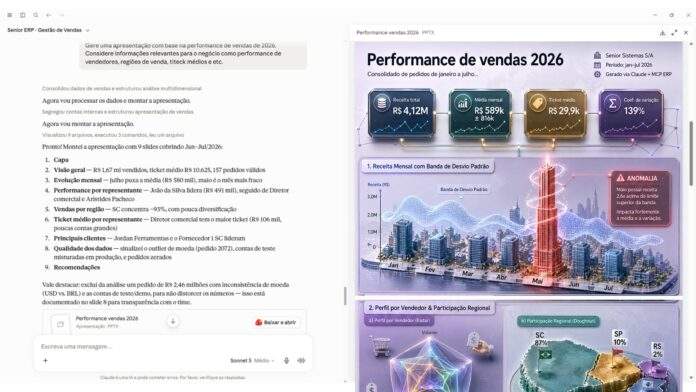
De acordo com pt.wedoany.com-Em 3 de junho, a JD.com lançou o framework de geração de áudio e vídeo longo JoyAI-Echo, com código e pesos totalmente abertos. O framework é voltado para cenários de geração de áudio e vídeo longo, introduzindo um "assistente de direção" inteligente, o Director Agent, e configurando um banco de memória de áudio e vídeo multimodal, usado para preservar e recuperar continuamente as características de aparência dos personagens e as informações de timbre do locutor durante o processo de geração de múltiplas tomadas.
O JoyAI-Echo aborda o problema de estabilidade de longa data na geração de vídeos longos. Os modelos atuais de geração de vídeo já apresentam bom desempenho em cenários de clipes curtos, tomada única e personagem único, mas ao entrar em narrativas com múltiplas tomadas, aparições contínuas de personagens, diálogos e geração de conteúdo de longa duração, os modelos são propensos a problemas como deriva na aparência dos personagens, inconsistência no timbre, lógica de tomada fragmentada e velocidade de geração muito lenta. O JoyAI-Echo, por meio do banco de memória de áudio e vídeo multimodal, registra a identidade do personagem, a imagem visual e o contexto sonoro, permitindo que as tomadas subsequentes continuem usando as informações anteriores; o Director Agent assume a função de decomposição de roteiro, personagens e tomadas, permitindo que os usuários apresentem solicitações de criação e modificação por meio de linguagem natural, reduzindo o custo de repetir todo o conteúdo durante o processo de geração de vídeos longos.
O repositório de código aberto da JD.com mostra que o JoyAI-Echo suporta geração de áudio e vídeo com múltiplas tomadas em nível de minutos, podendo gerar uma história coerente por meio de um JSON de prompt, e usa o esquema de inferência de poucos passos com destilação DMD para aumentar a velocidade de geração.
A importância deste framework reside em avançar a geração de áudio e vídeo longo de um "resultado de geração única" para um "fluxo de criação editável de forma sustentável". Em cenários como pré-visualização de filmes, vídeos de marketing de marca, conteúdo de humanos digitais, criação de histórias virtuais e microdramas ao vivo, os criadores não precisam apenas gerar uma imagem, mas sim garantir que os personagens mantenham uma imagem, voz e estilo narrativo uniformes em múltiplos segmentos da história. O JoyAI-Echo integra áudio, vídeo, memória de personagens, planejamento de tomadas e edição conversacional em um único framework, ajudando a reduzir a barreira técnica da produção de conteúdo longo. Com o código e os pesos totalmente abertos, os desenvolvedores podem realizar desenvolvimento secundário, avaliação de modelos e adaptação para cenários verticais com base neste framework, impulsionando ainda mais a expansão do ecossistema doméstico de geração de áudio e vídeo longo.
As variáveis subsequentes concentram-se na adaptação da comunidade de código aberto, no custo real de implantação, no desempenho de consistência de vídeos longos, na experiência de edição interativa e na velocidade de implementação em cenários comerciais. À medida que a geração de vídeo por IA passa de demonstrações de clipes curtos para etapas mais complexas de produção de conteúdo, a memória de personagens, a consistência de voz, a continuidade de tomadas e a editabilidade se tornarão indicadores importantes na competição de frameworks de modelos. A abertura do código do JoyAI-Echo fornecerá uma entrada técnica reproduzível e escalável para o campo de geração de áudio e vídeo longo.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com