De acordo com pt.wedoany.com-A Netflix otimizou a eficiência das consultas ao banco de dados Apache Druid ao introduzir uma estratégia de cache ciente de intervalos, fazendo com que cerca de 84% dos resultados analíticos venham do cache, reduzindo a carga de consultas em aproximadamente 33% e melhorando o tempo de consulta P90 em 66%. Essa otimização é realizada principalmente por uma camada de cache de proxy externa, abordando o problema de cálculos redundantes e varreduras repetidas de grandes conjuntos de dados causados por pequenos deslocamentos nos intervalos de tempo durante consultas contínuas de atualização em painéis de janela rolante.
Na escala da Netflix, seu sistema de análise em tempo real precisa processar trilhões de linhas de dados, fornecendo suporte a painéis para monitoramento, experimentação e tomada de decisões operacionais. Esses painéis executam consultas quase idênticas com frequência, como calcular taxas de erro ou métricas de engajamento dentro de janelas de tempo deslizantes. Evan King, cofundador da Hello Interview, destacou que o cache tradicional trata consultas repetidas com a mesma intenção, mas com pequenos deslocamentos nos limites de tempo, como solicitações diferentes, resultando em baixa taxa de reutilização do cache e cálculos repetidos no Apache Druid.
A abordagem da Netflix decompõe os resultados das consultas em segmentos alinhados por tempo, permitindo a reutilização em consultas de janela rolante sobrepostas. Em vez de armazenar em cache a saída completa da consulta, o sistema armazena agregações intermediárias em intervalos de tempo fixos. Quando uma nova consulta chega, os segmentos em cache são usados para a parte historicamente estável dentro da janela de tempo, e apenas os dados do intervalo de tempo mais recente são recalculados a partir do Druid e mesclados com os resultados em cache.
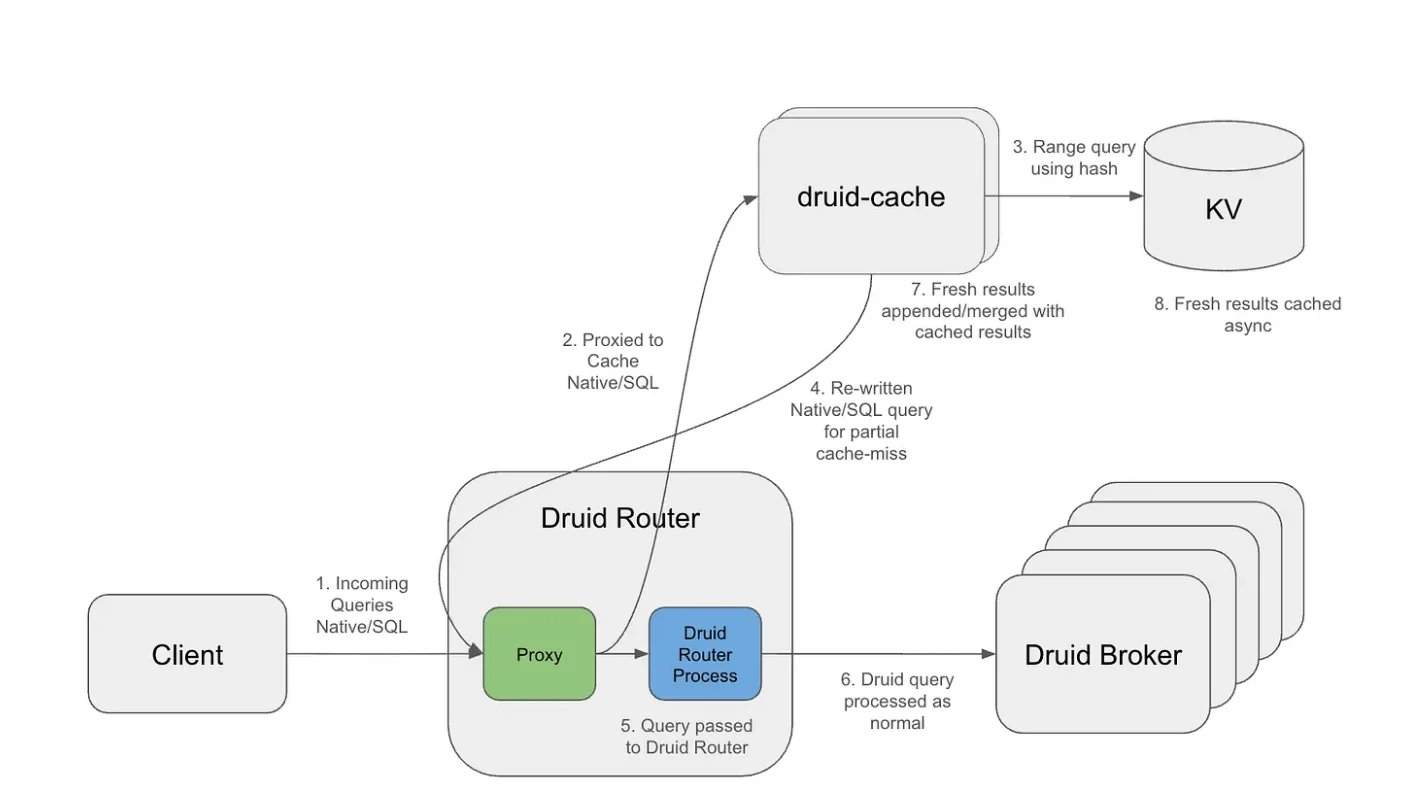
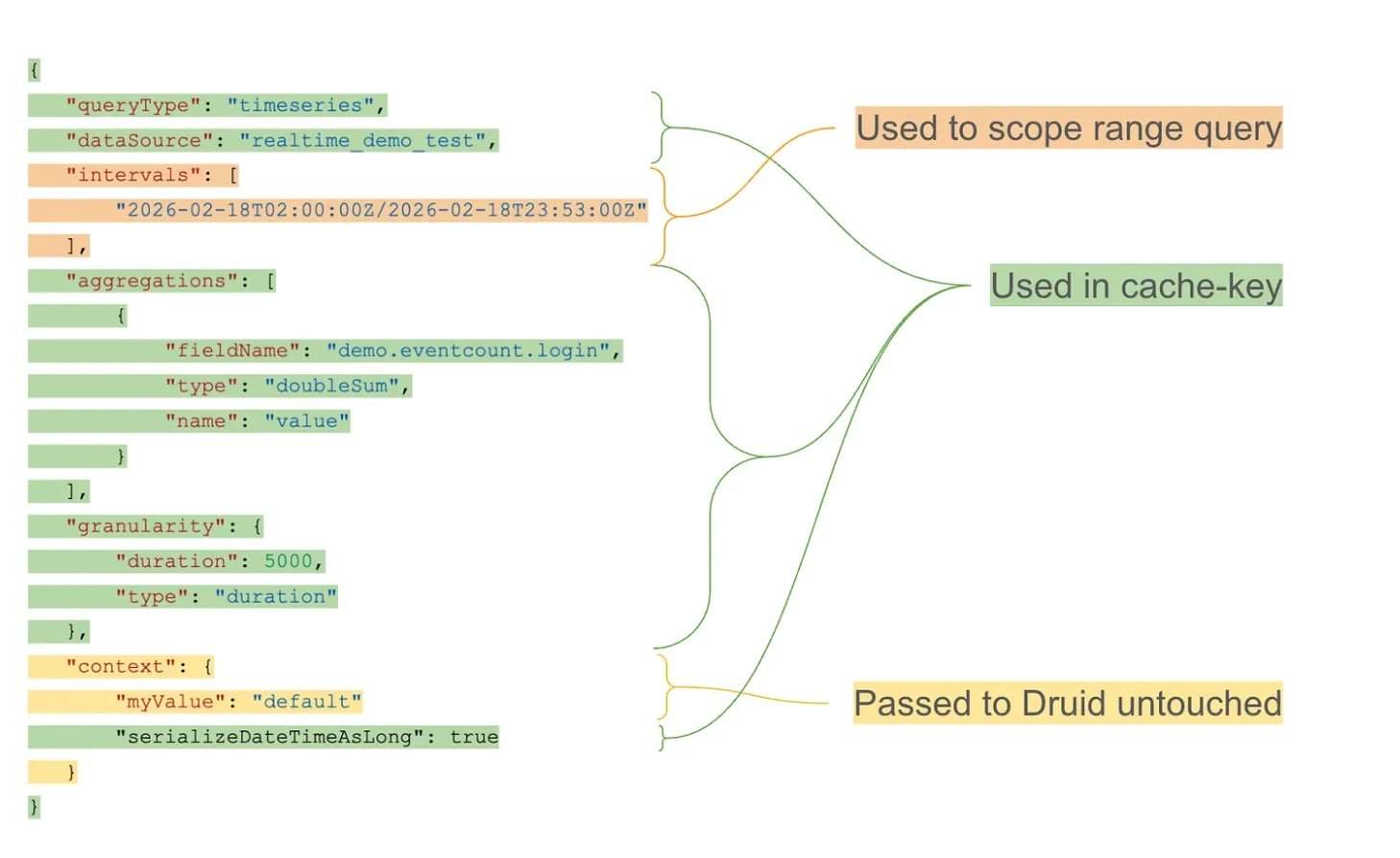
Sob uma carga de trabalho de mais de 10 trilhões de linhas de dados no Apache Druid, consultas repetidas de janela rolante tornaram-se o principal gargalo. A camada de cache, usando buckets alinhados por granularidade e uma estratégia de TTL (tempo de vida) exponencial, alcança cache de longo prazo para intervalos históricos, mantendo a atualidade dos dados mais recentes. Arquiteturalmente, a camada de cache opera como um proxy externo, interceptando consultas recebidas, separando a estrutura da consulta do intervalo de tempo e gerando chaves de cache reutilizáveis. Os segmentos em cache são armazenados em um sistema de chave-valor distribuído, suportando expiração independente e recuperação eficiente.
Com esse design, apenas o intervalo mais recente precisa ser recalculado, enquanto os segmentos históricos podem ser reutilizados em várias consultas sobrepostas. Consequentemente, o intervalo de tempo das operações de consulta que chegam ao Druid é significativamente reduzido, com menos segmentos varridos e menos dados processados. Em algumas cargas de trabalho, a Netflix observou uma redução de até 14 vezes nos bytes de resultado e uma diminuição drástica na varredura de segmentos.
Atualmente, o sistema é implantado como uma camada experimental e continua evoluindo. Trabalhos futuros incluem a expansão do suporte a consultas SQL modeladas usadas por ferramentas de painel, reduzindo a dependência de expressões de consulta nativas do Druid. A Netflix também está explorando a integração direta do cache ciente de intervalos no Apache Druid para eliminar a necessidade de uma camada de proxy externa e melhorar a eficiência do planejamento de consultas.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com