De acordo com pt.wedoany.com-A Cafe24 anunciou no dia 23 o lançamento de um serviço de infraestrutura de IA chamado "Roteador de Modelo de Linguagem de Grande Escala (LLM)", que permite integrar e usar mais de 120 modelos de IA através de uma única Interface de Programação de Aplicações (API).
A função principal do Roteador LLM é atuar como um "orquestrador", conectando mais de 120 interfaces dos principais modelos de IA, como ChatGPT, Claude e Gemini, a uma única plataforma, selecionando, distribuindo e alternando automaticamente o modelo adequado com base na solicitação inserida pelo usuário.
O serviço suporta o uso de mais de 120 modelos de IA, incluindo a série GPT da OpenAI, bem como Claude, Gemini, DeepSeek, Qwen, Llama, entre outros, através de uma única API. Seu núcleo é o mecanismo de roteamento, que analisa os tipos de trabalho, como codificação, raciocínio, tradução e criação, com base no conteúdo da solicitação do usuário, e conecta-se automaticamente ao modelo de IA mais adequado. Se o usuário pré-definir o intervalo de modelos disponíveis, o sistema se conectará automaticamente apenas dentro desse intervalo, sem que o usuário precise comparar ou selecionar modelos um a um.
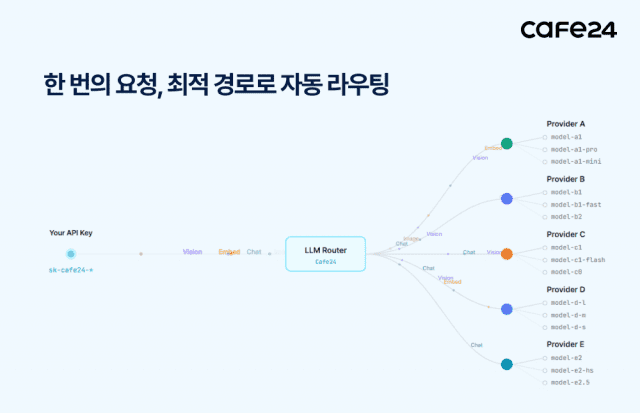
O serviço também oferece uma função para definir a prioridade dos provedores de serviços de IA de acordo com os critérios do usuário. Entre vários provedores de serviços de IA que oferecem o mesmo modelo, o sistema se conecta automaticamente ao provedor mais adequado com base nos critérios selecionados pelo usuário, como custo, velocidade e capacidade de processamento. Por exemplo, para o mesmo modelo Claude, se o usuário definir o custo como critério, o sistema se conecta automaticamente ao provedor com melhor relação custo-benefício; se a velocidade for o critério, conecta-se ao provedor com a resposta mais rápida. Além disso, o serviço suporta funções de lista de permissões e lista de bloqueios, permitindo que o usuário especifique provedores de serviços de IA a serem permitidos ou excluídos, controlando assim de forma flexível o escopo da conexão automática.
Para lidar com situações em que um modelo de IA específico não responde, o Roteador LLM suporta uma "função de alternância automática". O usuário pode pré-configurar um modelo principal e modelos alternativos. Quando o modelo principal não responde, o próximo modelo candidato assume automaticamente o processamento da solicitação. Por exemplo, se o Claude, usado como modelo principal, não responder, outro modelo pré-especificado assumirá automaticamente a tarefa, construindo assim um ambiente operacional de execução contínua.
Os usuários podem gerenciar vários modelos de IA de forma intuitiva em um único ambiente. Através do "Painel em Tempo Real", os usuários podem visualizar em uma única tela dados como número de solicitações, custo, tendências de uso de tokens, proporção de custos por modelo e taxas de sucesso e falha. O serviço também suporta registros detalhados em nível de solicitação e rastreamento de uso por equipe, projeto e ambiente, ajudando os usuários a compreender de forma mais eficiente o uso de IA e a estrutura de custos.
Os usuários também podem conectar suas próprias chaves de modelo de IA ao Roteador LLM para uso. Através do modo "BYOK (Bring Your Own Key)", os usuários registram as chaves dos modelos GPT, Claude, Gemini, etc., que estão usando, e podem usar diretamente esses modelos no ambiente do Roteador LLM, gerenciando diretamente os custos de uso dos modelos de IA.
O Roteador LLM adota um modelo de faturamento baseado em créditos de uso recarregáveis. Os usuários recebem créditos gratuitos ao se registrarem, podendo experimentar o serviço diretamente.
A Cafe24 planeja continuar expandindo o suporte para novos modelos de IA e provedores de serviços de IA no futuro, e continuará promovendo funcionalidades que aumentem a conveniência da operação e gestão de IA.
Lee Jae-seok, representante da Cafe24, afirmou que, com o rápido crescimento do número de tipos de modelos de IA, como conectá-los e operá-los de forma eficiente tornou-se um novo desafio. Ele disse que continuará a desempenhar diligentemente o papel de infraestrutura relevante, permitindo que os usuários utilizem vários modelos de IA com mais facilidade.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com