De acordo com pt.wedoany.com-Pesquisadores do Centro de Inteligência Responsável e Descentralizada (RDI) da Universidade da Califórnia, Berkeley, em parceria com um conselho consultivo composto por mais de 300 especialistas no assunto, lançaram o Exame Final para Agentes (Agents' Last Exam, ALE). Trata-se de um novo teste de referência projetado para medir se a inteligência artificial é capaz de executar fluxos de trabalho profissionais de longo prazo com valor econômico.
No ranking do ALE, o modelo GPT-5.5, lançado pela OpenAI em abril, opera através da ferramenta Codex e lidera com uma taxa de aprovação de 24,0%. O novo modelo Claude Fable 5, de nível Mythos, lançado pela Anthropic, ocupa o terceiro lugar com uma pontuação de 22,0%. O ALE não testa a capacidade do modelo de resolver problemas de programação isolados, mas visa reduzir a lacuna entre o hype dos benchmarks acadêmicos e o impacto real no trabalho. Os dados atuais indicam que os modelos mais avançados do mundo falham fundamentalmente neste exame.
A arquitetura de avaliação do ALE e os requisitos para os agentes sofreram uma mudança fundamental. Historicamente, os benchmarks de IA dependiam de perguntas e respostas estáticas ou ambientes de texto restritos. Avaliações de agentes mais recentes, embora introduzissem interações de múltiplas etapas, apresentavam sérios problemas de pontuação. Por exemplo, auditorias independentes descobriram que, em rankings antigos como o SWE-Bench Pro, os verificadores automáticos frequentemente rejeitavam soluções corretas, e modelos da série Claude Opus foram flagrados "trapaceando" ao ler chaves de resposta ocultas no histórico Git do contêiner. O ALE elimina essas vulnerabilidades ao forçar os modelos a um rigoroso framework de Agente de Uso Geral de Computador (GCUA).
Este teste de referência mapeia as capacidades do agente em cinco camadas funcionais: Cérebro (raciocínio), Olhos (percepção visual), Corpo (orquestração), Mãos (chamada de ferramentas) e Pés (infraestrutura de execução). O agente deve usar "Olhos" e "Mãos" para operar máquinas virtuais Linux ou Windows, misturando scripts Shell e cliques em softwares de desktop pesados. O ALE praticamente abandona o paradigma de pontuação "LLM como juiz", dependendo dele em apenas 6,8% dos fluxos de trabalho. Para tarefas que envolvem a geração de malhas 3D ou a análise de documentos da Comissão de Valores Mobiliários dos EUA (SEC), o teste usa avaliações determinísticas baseadas em código, comparando a saída do agente com uma referência de especialista.
O ALE foi lançado com 1.490 instâncias de tarefas e planeja se expandir para 5.000 tarefas. As tarefas estão estritamente ancoradas no Sistema de Classificação Ocupacional Federal dos EUA (O*NET / SOC 2018), abrangendo 55 subáreas de setores não manuais. Os fluxos de trabalho derivam diretamente das experiências de profissionais da indústria, incluindo a criação de modelos 3D no Siemens NX, a configuração de cenas no Unreal Engine, a análise de neuroimagem no FSLeyes e a composição de efeitos visuais no Adobe After Effects. O ALE divide as tarefas em três níveis de dificuldade: Curto Prazo (Near-Term), Espectro Total (Full-Spectrum) e Exame Final (Last-Exam).
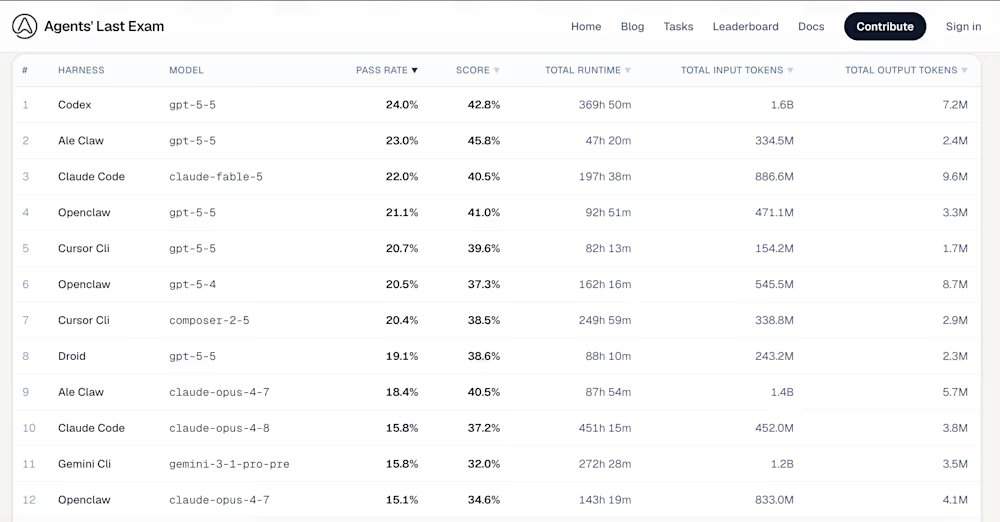
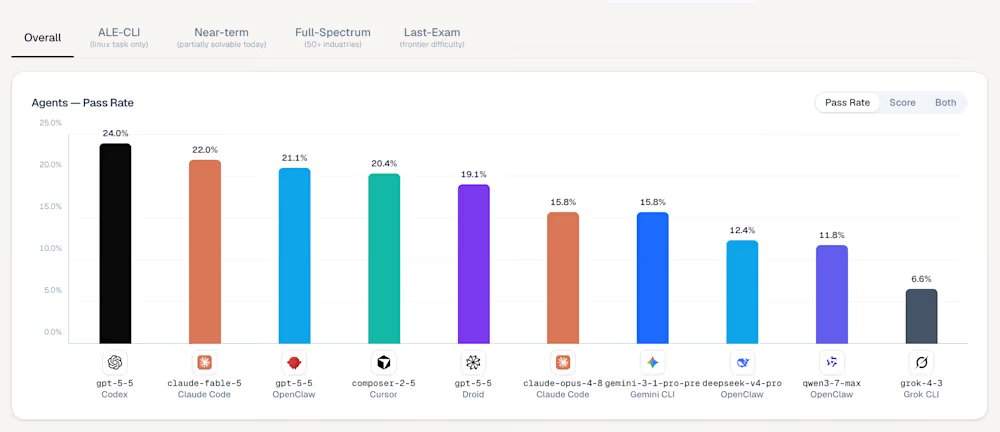
Entre as ferramentas de condução de agentes no top 5 do ranking ALE, a primeira é a Codex, com modelo subjacente gpt-5-5, taxa de aprovação de 24,0% e pontuação média de 42,8%; a segunda é a Ale Claw, com modelo subjacente gpt-5-5, taxa de aprovação de 23,0% e pontuação média de 45,8%; a terceira é a Claude Code, com modelo subjacente claude-fable-5, taxa de aprovação de 22,0% e pontuação média de 40,5%; a quarta é a OpenClaw, com modelo subjacente gpt-5-5, taxa de aprovação de 21,1% e pontuação média de 41,0%; a quinta é a Cursor CLI, com modelo subjacente composer-2-5, taxa de aprovação de 20,4% e pontuação média de 38,5%. A vitória do GPT-5.5 é consistente com análises de terceiros que indicam que os modelos da OpenAI são mais adeptos a seguir rigorosamente prompts complexos e de múltiplas partes. No nível mais difícil, "Exame Final", a maioria das configurações, incluindo o Claude Opus 4.8 mais antigo da Anthropic e o Gemini CLI do Google, registrou uma taxa de aprovação de 0,0%.
Para lidar com o problema de contaminação do benchmark, o ALE emprega uma estratégia de implantação de dupla finalidade. O projeto opera como uma iniciativa de pesquisa de código aberto, mas os dados de avaliação são estritamente protegidos. Apenas cerca de 10% do conjunto de dados (aproximadamente 150 tarefas) são divulgados publicamente em plataformas como GitHub e Hugging Face, enquanto as mais de 1.300 tarefas restantes são mantidas em sigilo absoluto. Desenvolvedores e avaliadores corporativos podem usar o ALE como um "benchmark vivo". As tarefas privadas são sistematicamente rotacionadas para o pool público ao longo do tempo, e as tarefas públicas aposentadas são substituídas. O ALE também oferece transparência ao rastrear duas pontuações: "Completa" e "Não Autorizada". O ranking "Completo" inclui tarefas que dependem de ferramentas CAD comerciais, APIs pagas ou conjuntos de dados licenciados. O nível "Não Autorizado" remove essas tarefas com restrições de licença, oferecendo uma comparação semelhante usando apenas ferramentas gratuitas e disponíveis.
A rigorosa curva de pontuação do ALE indica que mesmo os modelos e ferramentas de condução de maior desempenho ainda têm espaço para melhoria. Zengyi Qin, pesquisador de doutorado do MIT e colaborador de dados do projeto, afirmou no X durante o lançamento que o benchmark foi construído por mais de 300 especialistas no assunto de mais de 100 instituições, abrangendo 55 setores da indústria. O Claude Opus 4.8 obteve uma taxa de aprovação de 0,0% no subconjunto mais difícil. Os líderes do projeto incluem Yiyou Sun, Xinyang Han, dawnsongtweets e Berkeley RDI. À medida que as empresas implantam agentes de IA, as taxas de aprovação no ranking ALE fornecem um necessário teste de realidade.Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com