De acordo com pt.wedoany.com-A Microsoft lançou recentemente um novo framework de código aberto chamado SkillOpt, que visa transformar documentos de habilidades de agentes de IA em objetos treináveis, melhorando sistematicamente o desempenho dos agentes em tarefas complexas através da introdução de métodos de otimização inspirados no aprendizado profundo.

Em aplicações empresariais de IA, as habilidades dos agentes geralmente existem na forma de arquivos Markdown baseados em texto, contendo instruções que orientam o modelo a se adaptar a fluxos de trabalho específicos. No entanto, a otimização tradicional dessas habilidades depende de edição manual, um processo lento e propenso a erros, onde os usuários frequentemente precisam tentar repetidamente para encontrar a combinação de instruções que melhora o desempenho. O lançamento do SkillOpt resolve esse problema. Este framework (licenciado sob MIT) trata os documentos de habilidades como objetos treináveis que podem ser ajustados iterativamente com base no feedback de desempenho, permitindo uma adaptação programática em nível de documento sem alterar os pesos do modelo subjacente.
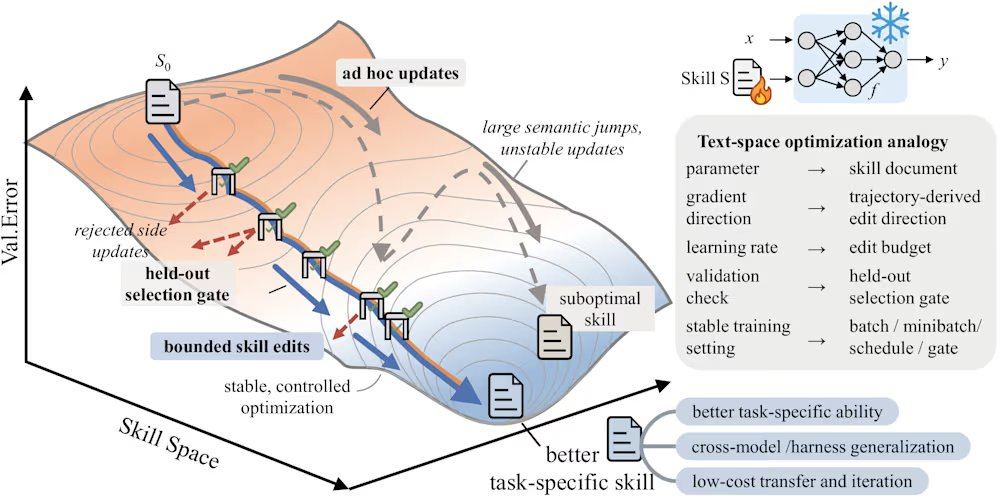
Yifan Yang, engenheiro sênior de pesquisa e desenvolvimento da Microsoft Research Asia, aponta que a edição manual de documentos de habilidades enfrenta três modos de falha principais: falta de controle de passo, levando à deriva das habilidades; ausência de mecanismo de validação, fazendo com que modificações aparentemente corretas possam causar queda de desempenho; e falta de memória de feedback negativo, resultando na repetição dos mesmos erros. Por exemplo, uma reescrita irrestrita reduziu o GPT-5.5 de 41,8 para 41,1 no benchmark SpreadsheetBench. Yang enfatiza que esses erros são amplificados em fluxos de trabalho de múltiplas etapas, que são justamente o ponto fraco dos modelos de ponta atuais em raciocínio de zero-shot.
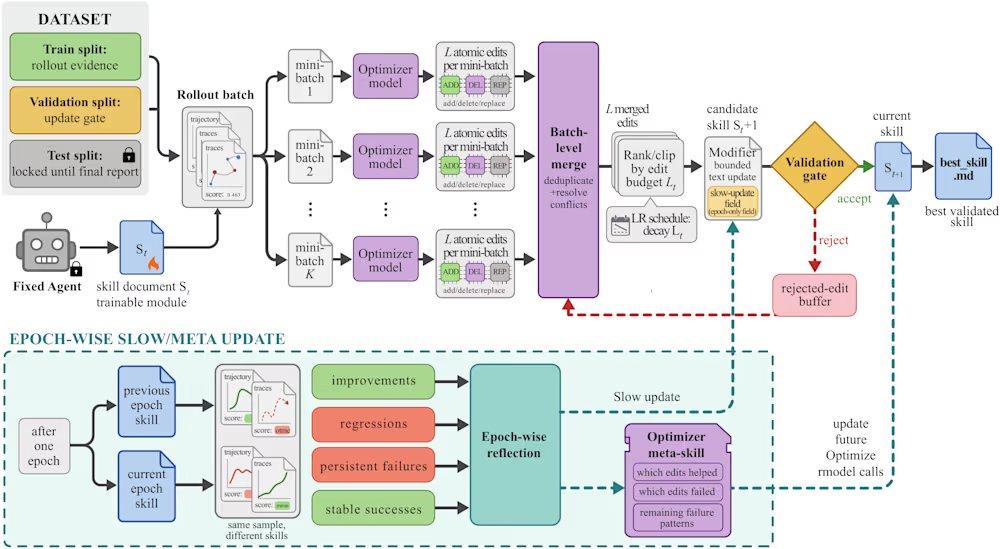
O SkillOpt resolve esses problemas através de um ciclo iterativo de proposta e teste. O processo começa com um modelo alvo congelado executando um lote de tarefas, gerando trajetórias de execução como evidência do estado atual. Em seguida, um otimizador offline analisa essas trajetórias, identifica erros programáticos sistemáticos e propõe edições estruturais no documento de habilidades. Essas edições são revisadas e classificadas antes de serem aplicadas, com um orçamento máximo de edição por etapa (semelhante à taxa de aprendizado no aprendizado profundo) para evitar mudanças drásticas na versão da habilidade. As habilidades candidatas são avaliadas em um conjunto de validação reservado: se melhorarem a pontuação de validação, são aceitas; se falharem, são rejeitadas e enviadas para um buffer de edições rejeitadas, fornecendo feedback negativo ao otimizador. Além disso, o framework executa atualizações lentas comparando o desempenho das tarefas entre as habilidades das rodadas anterior e atual, similar a um termo de momentum, para transmitir experiência programática duradoura.
Em avaliações práticas, a equipe de pesquisa testou o SkillOpt em vários modelos, incluindo GPT-5.5, GPT-5.4-mini e Qwen3.5-4B, abrangendo benchmarks como perguntas e respostas de rodada única, geração de código de múltiplas rodadas e raciocínio multimodal em documentos. Os resultados mostram que o SkillOpt superou várias linhas de base, incluindo TextGrad, GEPA e EvoSkill, em todas as 52 combinações de avaliação. No modelo de ponta GPT-5.5, houve um aumento médio absoluto de 23,5 pontos percentuais na precisão em comparação com a linha de base sem habilidades. Para modelos menores, como o GPT-5.4-nano, as pontuações quase dobraram ou triplicaram. Esses ganhos de desempenho se traduzem diretamente em necessidades críticas das empresas, como extração precisa de números em contratos, faturas e tabelas, além de operações como automação de AP, sinistros e conformidade. Yang afirma que a melhoria está na confiabilidade, incluindo formatação precisa, autovalidação e saídas auditáveis, e que esses benefícios vêm do aprendizado de procedimentos, não da memorização de respostas.
O framework SkillOpt demonstra boa portabilidade e compatibilidade. Experimentos confirmam que o framework é independente do framework de execução, alcançando melhorias significativas em ambientes de execução suportados por ferramentas como Codex CLI e Claude Code. Por exemplo, uma habilidade de planilha treinada inteiramente dentro do loop do Codex pode ser transferida diretamente para o Claude Code sem qualquer alteração, gerando um ganho de desempenho de até 59,7 pontos percentuais em relação à linha de base nativa do Claude Code. Além disso, os artefatos de habilidade podem ser transferidos entre diferentes escalas de modelo: habilidades otimizadas para o GPT-5.4, quando implantadas em modelos menores como GPT-5.4-mini e GPT-5.4-nano, ainda produzem ganhos positivos. Os documentos de habilidade finais nunca excedem 2.000 tokens, com comprimento médio de cerca de 920 tokens, sendo altamente legíveis e auditáveis.
Em termos de custo, para casos de uso empresarial diários, o ônus real do SkillOpt é leve. Yang menciona que, em frameworks comunitários como GBrain, as atualizações do SkillOpt são executadas no Claude Sonnet, com um custo médio de treinamento de uma habilidade para uma única tarefa entre 1 e 5 dólares, sendo esse custo de otimização um investimento único. No entanto, a operação eficaz do framework requer duas condições: dezenas de exemplos representativos e um sinal de feedback que possa ser pontuado. As equipes devem evitar aplicá-lo a tarefas abertas ou subjetivas. Ao mesmo tempo, o SkillOpt pode trabalhar em conjunto com pilhas de orquestração existentes (como DSPy), sendo complementares e não substitutos. Olhando para o futuro, a comunidade de código aberto já começou a implantar execuções periódicas do SkillOpt em trajetórias passadas de agentes, visando construir um ecossistema de plugins de agentes de código auto-otimizável. Yang acredita que as habilidades são o primeiro passo mais rápido, mais barato e mais reversível para a IA descobrir conhecimento de forma autônoma e melhorar seu próprio comportamento, e que essa mesma linha de pensamento aponta para que os agentes eventualmente se auto-otimizem, até mesmo em seus próprios pesos.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com