De acordo com pt.wedoany.com-Robótica A disputa de rotas tecnológicas tornou-se o foco da indústria na Conferência de Inteligência Artificial de Pequim, em junho. No último ano, com o aquecimento da indústria robótica, o debate sobre se os robôs devem seguir a rota VLA (Visão-Linguagem-Ação) ou a rota do Modelo Mundial tem se intensificado. O Dr. Guo Yandong, fundador e CEO da ZhiPingFang, deu uma resposta clara em seu discurso de abertura no Fórum de CEOs da Indústria Corporificada da conferência: o Modelo Mundial não é uma rota concorrente do VLA, mas sim um componente central de seu sistema; após a fusão do Modelo Mundial com o VLA, a arquitetura neuromórfica se tornará uma importante direção evolutiva para o cérebro da próxima geração de robôs.

Por trás desse julgamento está o planejamento tecnológico da ZhiPingFang nos últimos três anos. Guo Yandong acredita que, do ponto de vista da evolução da vida, a capacidade de ação não surge isoladamente; a vida primeiro percebe e compreende o ambiente para então gerar ação. Ele redefiniu o VLA, considerando-o como um termo geral para uma arquitetura de modelo ponta a ponta orientada por big data que funde múltiplas modalidades, e acredita que não há diferença essencial entre o Modelo Mundial e o VLA, nem uma relação de substituição. O Modelo Mundial resolve a previsão 4D densa e com dimensão temporal do ambiente físico, sendo uma parte da percepção espacial do VLA, que pode ajudar a melhorar as capacidades do cérebro robótico. Guo Yandong exemplificou a razão pela qual ambos devem se fundir: a lógica de raciocínio cognitivo, como pegar o saquinho de chá antes de derramar água para fazer chá, depende do modelo de linguagem, enquanto o Modelo Mundial é bom em previsões de curto prazo, como a possibilidade de um copo cair ao se aproximar da borda da mesa. A combinação de ambos permite que o robô possua tanto previsão física de curto prazo quanto capacidade de planejamento de tarefas de longo prazo. A ZhiPingFang também utiliza o Modelo Mundial para gerar dados de borda difíceis de coletar em ambientes reais, a fim de complementar o treinamento do VLA.
Com base nesse julgamento, a ZhiPingFang, em novembro de 2025, em parceria com a Universidade de Pequim, lançou a nova geração de arquitetura Video2Act que funde o Modelo Mundial, realizando pela primeira vez o paradigma de modelo robótico "primeiro prever, depois executar". O Video2Act não é um modelo tradicional de geração de vídeo, mas sim uma arquitetura VLA que funde o Modelo Mundial 4D. Através da modelagem de informações espaciais densas e da entrada contínua de sequências de ações, o robô pode compreender antecipadamente as mudanças de estado futuro e converter a capacidade preditiva em decisões de ação. Em avaliações de terceiros, o Video2Act obteve uma melhoria de desempenho superior a 30% em comparação com os modelos mais avançados similares do Vale do Silício. Na pesquisa abrangente de autoridade mundial sobre Modelos Mundiais, "World Model for Robot Learning: A Comprehensive Survey", conduzida por acadêmicos globais de ponta, como Philip Torr, membro de ambas as academias reais do Reino Unido e pesquisador de classe mundial em Inteligência Artificial da Turing, e Pieter Abbeel, fundador da área de aprendizado por reforço, o Video2Act foi citado como um resultado representativo da "rota de fusão Modelo Mundial + VLA".

Após resolver o problema da fusão entre o Modelo Mundial e o VLA, a ZhiPingFang concentrou-se em superar o desafio de como os robôs podem agir de forma estável e eficiente como os humanos. Guo Yandong apresentou na Conferência de Inteligência Artificial de Pequim o mais recente sistema de inteligência corporificada neuromórfica da ZhiPingFang, o NeuroVLA. Este é atualmente o único sistema de inteligência corporificada que possui simultaneamente as três principais capacidades de movimento biológico: percepção ativa, autorrecuperação de falhas e memória temporal. Guo Yandong apontou que, embora os robôs nas arquiteturas VLA existentes tenham uma forte capacidade de compreensão, ainda enfrentam problemas como resposta lenta, tremor de movimento e alto consumo de energia em ambientes reais complexos, pois a maioria dos robôs depende de um único modelo grande para processar simultaneamente percepção, raciocínio e controle.
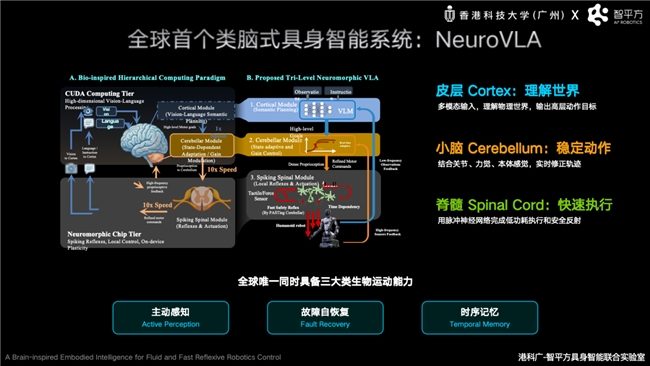
Inspirando-se no mecanismo em que o córtex cerebral humano é responsável pelo pensamento, o cerebelo pela coordenação motora e a medula espinhal pelos reflexos instintivos, a ZhiPingFang construiu a arquitetura neuromórfica de três níveis "córtex-cerebelo-medula espinhal", inédita globalmente, chamada NeuroVLA. Nela, o córtex é responsável pela compreensão semântica e planejamento de tarefas, o cerebelo pela coordenação motora de alta frequência e correção dinâmica, e a medula espinhal pela execução motora em milissegundos e reflexos de segurança. Este design permite que o robô melhore a estabilidade, o tempo real e a eficiência energética no mundo físico real a partir do nível da arquitetura. Resultados experimentais mostram que o NeuroVLA pode reduzir o tremor de movimento do robô em mais de 75%, completar a resposta reflexa em 20 milissegundos após uma colisão e reduzir significativamente o consumo de energia do sistema.

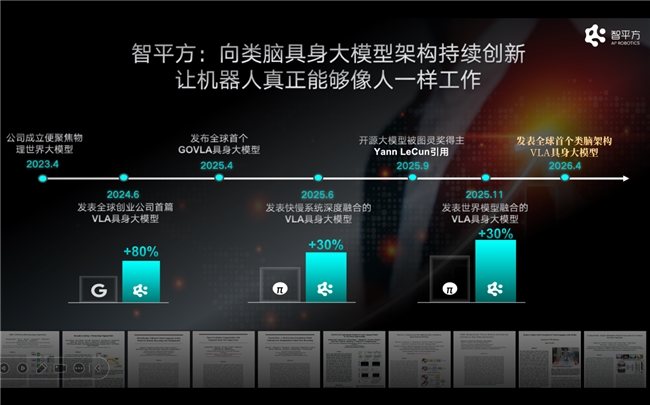
Do VLA ponta a ponta ao Video2Act, e depois ao NeuroVLA, a ZhiPingFang tem realizado inovações sistemáticas em torno do cérebro robótico nos últimos três anos. Esta rota evolutiva corresponde a uma mesma direção: dar ao robô um "cérebro" mais semelhante ao cérebro humano.