De acordo com pt.wedoany.com-O trabalho de inteligência espacial multimodal Spatial-TTT, tendo como primeiro autor o doutorando da Universidade Tsinghua, Liu Fangfu, em colaboração com vários pesquisadores, foi recentemente aceito na principal conferência de visão computacional, ECCV 2026. Este trabalho foca em resolver o problema de inteligência espacial em fluxo contínuo de modelos multimodais de grande porte no mundo físico real, ou seja, como o modelo forma e atualiza continuamente a memória espacial em um fluxo de vídeo em constante mudança, em vez de tratar cada entrada como um segmento independente.
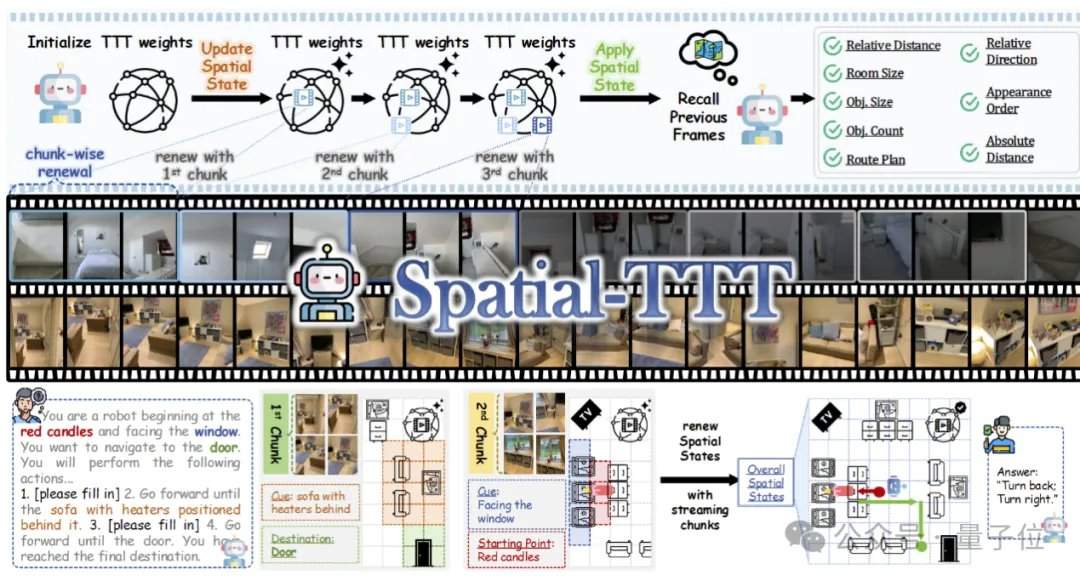
Cenários reais, como navegação de robôs, direção autônoma e realidade aumentada, exigem que os modelos tenham capacidades muito além da compreensão de imagens estáticas. Métodos tradicionais, ao lidar com fluxos de vídeo longos que duram dezenas de minutos ou até horas, sofrem de fragmentação da compreensão espacial devido à falta de um mecanismo eficaz de atualização de memória online. O Spatial-TTT foi proposto para enfrentar esse desafio, introduzindo o conceito de Test-Time Training (TTT) no campo da inteligência espacial, permitindo que o modelo atualize seus parâmetros internos enquanto assiste ao vídeo durante o processo de inferência.
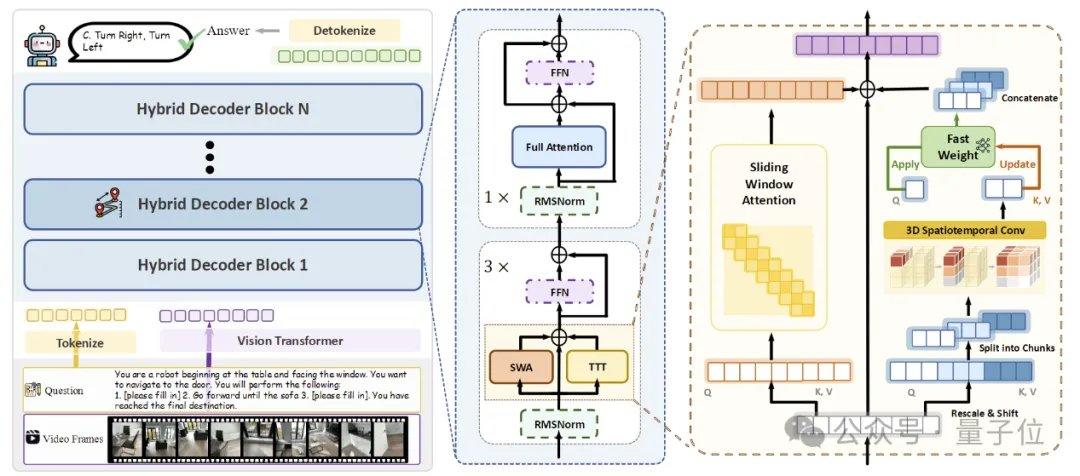
Para alcançar uma memória espacial de fluxo eficiente, a equipe de pesquisa propôs três tecnologias-chave. A primeira é a arquitetura TTT híbrida, que intercala camadas TTT e camadas de ancoragem de autoatenção padrão no decodificador em uma proporção de 3:1. As primeiras são responsáveis por escrever informações de longo alcance em pesos rápidos, enquanto as últimas mantêm a capacidade de alinhamento cross-modal e raciocínio semântico do modelo pré-treinado. A segunda é o mecanismo de previsão espacial, que introduz convoluções espaço-temporais 3D leves no ramo TTT, permitindo que o modelo aprenda relações de previsão entre contextos espaço-temporais, aumentando a estabilidade da atualização online. A terceira é a supervisão densa de descrição de cena, que constrói dados de descrição de cena cobrindo contexto global, categorias de objetos e relações espaciais, treinando o modelo para passar de "responder localmente" para "manter uma memória 3D global".
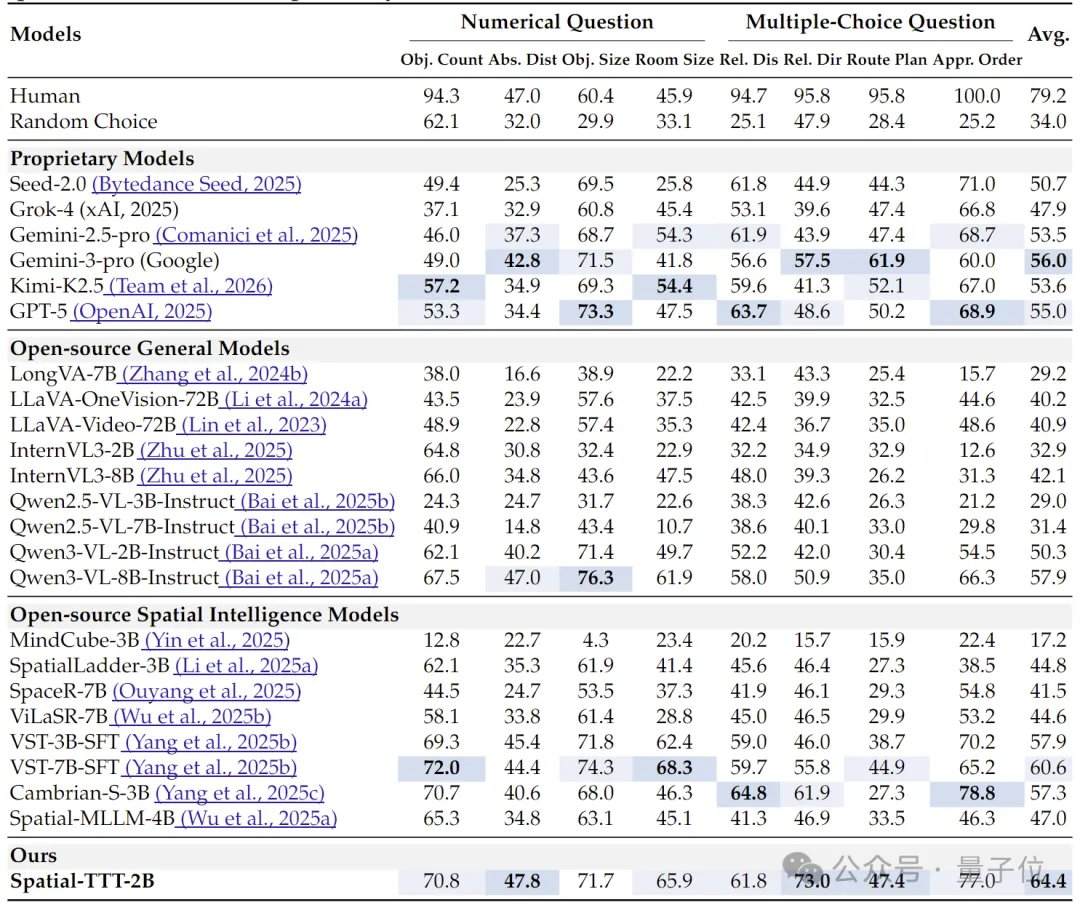
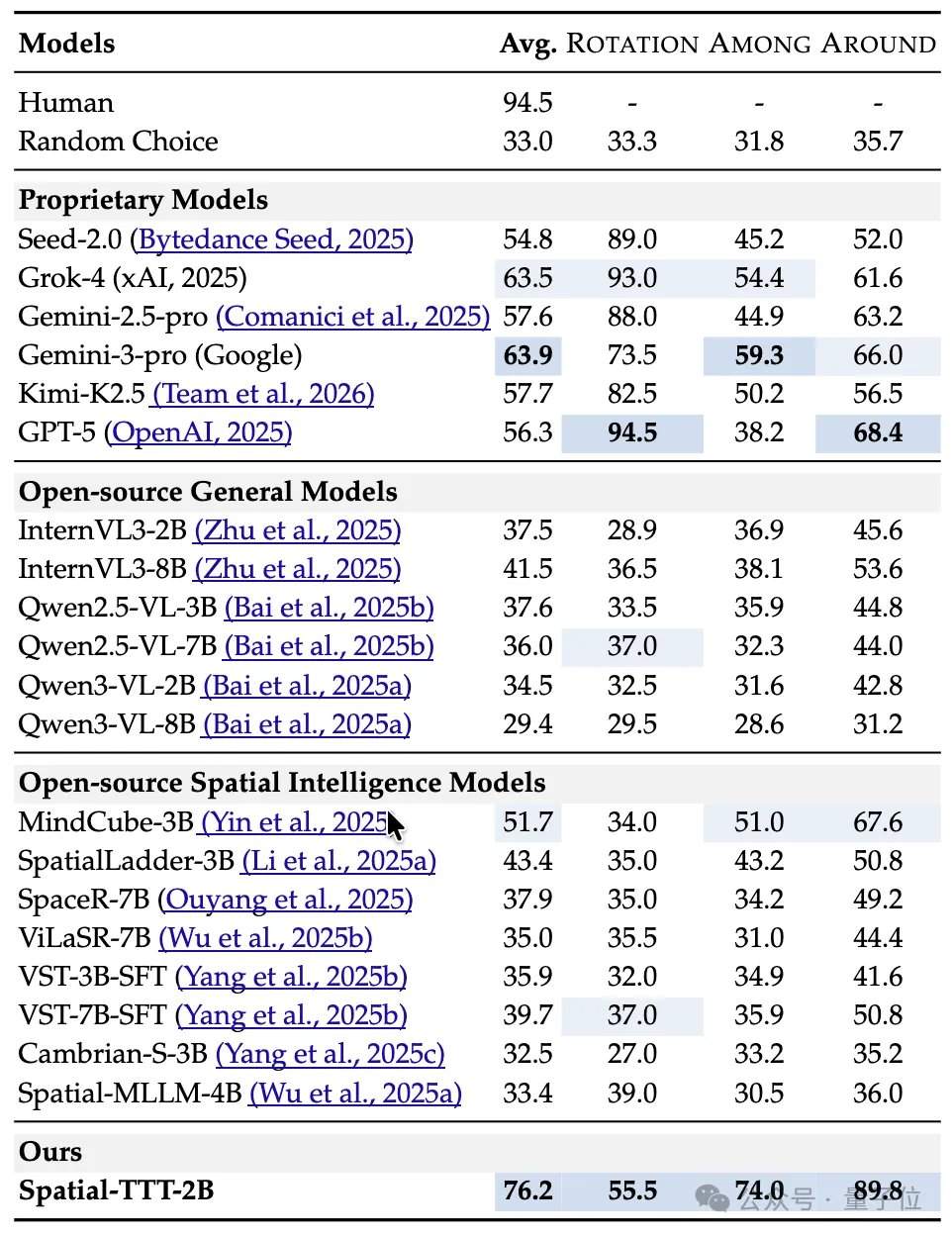
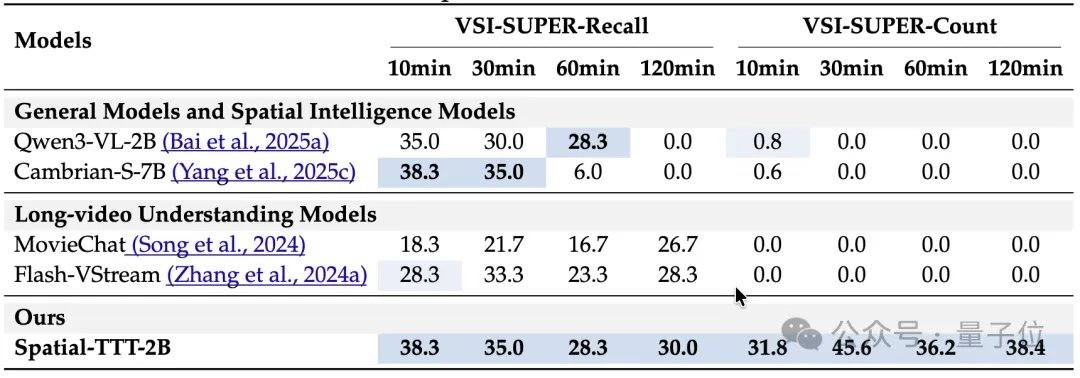
Em termos de resultados experimentais, o Spatial-TTT, com apenas 2B parâmetros, demonstrou vantagens significativas em vários benchmarks especializados de inteligência espacial. No VSI-Bench, sua pontuação média atingiu 64,4, superando modelos fechados como GPT-5 e Gemini-3-pro. No benchmark MindCube-Tiny, que testa o raciocínio espacial multifacetado de granularidade fina, o Spatial-TTT alcançou uma precisão de 76,2%, 12 pontos percentuais a mais que o Gemini-3-pro (63,9%) e quase 25 pontos percentuais a mais que o modelo espacial de código aberto representativo MindCube-3B (51,7%). Nas tarefas da série VSI-SUPER, que testam a memória de longo prazo, o modelo conseguiu processar de forma estável vídeos em fluxo de até 120 minutos. Na tarefa VSI-SUPER-Count, as pontuações do Spatial-TTT em vídeos de 10, 30, 60 e 120 minutos foram de 31,8, 45,6, 36,2 e 38,4, respectivamente.
A análise de eficiência mostra que, com uma configuração de entrada de 1024 quadros, o pico de uso de memória do Spatial-TTT-2B é de 11,9 GB, com uma quantidade teórica de computação de 799,4 TFLOPs, economizando mais de 40% de memória e recursos computacionais em comparação com modelos de base líderes do setor. Experimentos de ablação confirmam ainda que seu ganho de desempenho vem do efeito sinérgico entre a arquitetura híbrida, o mecanismo de previsão espacial e o sinal de supervisão denso. Especificamente: removendo o mecanismo de previsão espacial, a pontuação média no VSI-Bench caiu de 64,4 para 62,1; removendo a supervisão densa de descrição de cena, caiu para 61,3; se a arquitetura híbrida for completamente removida e apenas a estrutura TTT pura for usada, a pontuação média cai diretamente para 53,9.
Esta pesquisa, selecionada para o ECCV 2026, oferece um novo caminho técnico para sistemas de inteligência artificial física que exigem operação contínua de longo prazo. Ao permitir que o modelo acumule, corrija e utilize continuamente informações espaciais, os agentes inteligentes do futuro não enfrentarão mais quadros de imagem fragmentados, mas serão capazes de construir um modelo de mundo interno contínuo, compreensível e no qual possam atuar.
Link do artigo: https://arxiv.org/pdf/2603.12255
Página do projeto: https://liuff19.github.io/Spatial-TTT/
GitHub: https://github.com/THU-SI/Spatial-TTT/
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com