
De acordo com pt.wedoany.com-A empresa chinesa de IA DeepSeek, em colaboração com a Universidade de Pequim, lançou em 27 de junho o framework de aceleração de inferência DSpark, propondo um novo método para lidar com o gargalo de eficiência de inferência em serviços de alta concorrência de grandes modelos. Baseado na direção de decodificação especulativa, o framework utiliza uma estrutura de geração semi-autorregressiva e um mecanismo de verificação dinâmica baseado em confiança para melhorar a qualidade dos tokens de rascunho e reduzir cálculos de verificação ineficazes. No sistema de serviço online DeepSeek-V4, o DSpark aumentou a velocidade de inferência em cerca de 60% a 85% em comparação com o modelo de base, e reduziu a perda de throughput em cenários de alta concorrência.
A decodificação especulativa é uma das principais rotas atuais para acelerar a inferência de grandes modelos. Ao gerar texto, grandes modelos geralmente precisam prever token por token, onde o próximo token só pode ser calculado após a geração do anterior. Esse método autorregressivo garante a coerência contextual, mas também dificulta a paralelização completa do processo de inferência. A ideia da decodificação especulativa é primeiro permitir que um modelo de rascunho mais leve gere vários tokens candidatos antecipadamente, que são então verificados pelo grande modelo alvo; se os tokens candidatos forem aceitos, vários passos de geração podem ser avançados de uma só vez, aumentando assim a velocidade geral de saída.
O problema é que, embora os métodos existentes de geração paralela de rascunhos possam produzir blocos de tokens mais longos de uma só vez, a correlação entre os tokens é insuficiente, fazendo com que os tokens subsequentes se desviem mais facilmente da distribuição do modelo alvo, aumentando a taxa de rejeição. Tokens de rascunho rejeitados não apenas não trazem aceleração, mas também consomem poder computacional de verificação, especialmente em serviços online de alta concorrência, resultando em desperdício adicional de computação. O DSpark aborda esse ponto crítico adicionando um módulo sequencial leve à espinha dorsal de geração paralela, permitindo uma dependência mais forte entre os tokens de rascunho e aumentando o comprimento aceitável das sequências candidatas.
A estrutura semi-autorregressiva é o design central do DSpark. Ela não retorna completamente à autorregressão token por token, nem gera todo o bloco de rascunho de uma só vez de forma puramente paralela, mas sim faz um compromisso entre eficiência paralela e dependência sequencial. A espinha dorsal paralela é responsável por gerar rapidamente blocos candidatos, enquanto o módulo sequencial leve complementa as relações contextuais entre tokens adjacentes, aproximando o modelo de rascunho do caminho de geração do modelo alvo. Dessa forma, o modelo alvo aceita mais facilmente tokens consecutivos durante a fase de verificação, permitindo que uma única verificação avance uma distância de geração maior.
Outro mecanismo chave do DSpark é a verificação dinâmica baseada em confiança. A probabilidade de sucesso dos rascunhos varia entre diferentes solicitações, contextos e posições de geração. Se o sistema fixar o comprimento de verificação, pode desperdiçar computação em solicitações de baixa probabilidade de sucesso ou não aproveitar totalmente os rascunhos aceitáveis em solicitações de alta probabilidade. O DSpark ajusta adaptativamente o comprimento de verificação com base na probabilidade de sucesso da solicitação e na carga do sistema, evitando situações de "verificar rascunhos longos mesmo com baixa taxa de aceitação" e alocando poder computacional de forma mais razoável sob alta carga.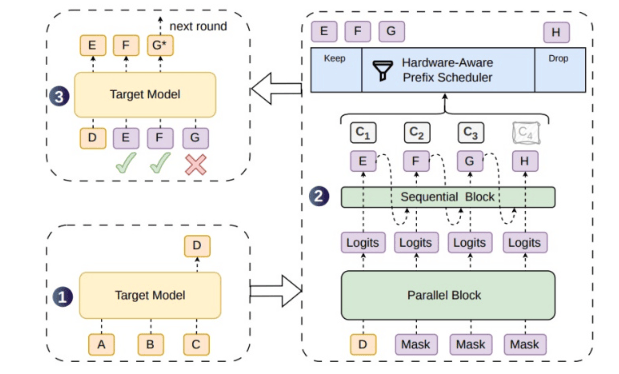
Este mecanismo é particularmente importante para ambientes de produção online. Ambientes de teste offline geralmente têm solicitações mais controláveis e menor pressão de concorrência, mas serviços reais de grandes modelos enfrentam um grande número de solicitações de usuários simultaneamente, com diferentes comprimentos de entrada, tipos de tarefa, estilos de saída e dificuldades de geração. Um framework de aceleração de inferência que só funciona em experimentos de pequeno lote dificilmente suporta implantação comercial. O DSpark alcançou um aumento de 60% a 85% na velocidade de inferência no sistema online DeepSeek-V4, demonstrando que seu design foi validado para pressões reais de serviço, e não apenas para otimização de métricas de laboratório.
O DSpark também melhora o throughput de alta concorrência ao aumentar o comprimento de geração aceitável. O custo dos serviços de grandes modelos não vem apenas da latência de solicitações individuais, mas também da capacidade total de throughput dos clusters de GPU sob alta carga. Quanto maior a qualidade do rascunho, mais tokens são aprovados em uma única verificação pelo modelo alvo, e maior é a saída efetiva por unidade de recurso computacional. Para serviços de API, sistemas de agente, geração de código, busca e resposta a perguntas e aplicações empresariais de IA, a redução do custo de inferência significa que a mesma capacidade computacional pode atender a mais solicitações, ou fornecer tempos de resposta mais rápidos pelo mesmo custo.
A DeepSeek também lançou simultaneamente o checkpoint do modelo e o framework de treinamento DeepSpec de código aberto, fornecendo à comunidade um conjunto completo de ferramentas para continuar a pesquisa em algoritmos de decodificação especulativa. O DeepSpec inclui treinamento de modelos de rascunho, preparação de dados, scripts de avaliação e implementações de vários algoritmos, suportando o treinamento e a comparação de modelos de rascunho como DSpark, DFlash e Eagle3. O significado de um framework de código aberto é que desenvolvedores externos e instituições de pesquisa podem reproduzir, ajustar e avaliar em torno de diferentes modelos alvo, dados de tarefas e cenários de serviço, impulsionando a decodificação especulativa de algoritmos pontuais para ferramentas de engenharia.
Este resultado também reflete que a competição de grandes modelos está se expandindo da escala de parâmetros do modelo para a eficiência da engenharia de inferência. A capacidade do modelo determina o limite superior do serviço, enquanto a velocidade de inferência e o custo unitário determinam a velocidade de comercialização. Com aplicações empresariais, agentes, assistentes de programação e sistemas multimodais entrando em uso de alta frequência, os usuários não exigem apenas que o modelo "responda bem", mas também que "responda rápido, com baixo custo e estabilidade em alta concorrência". O que o DSpark resolve é precisamente o problema de eficiência fundamental dos grandes modelos ao entrarem em serviços online em larga escala.
Os próximos pontos de interesse concentram-se em três aspectos: primeiro, se o DSpark pode manter aceleração estável em mais arquiteturas de modelo e tipos de tarefa; segundo, se o mecanismo de verificação dinâmica pode continuar a reduzir cálculos ineficazes em ambientes de concorrência ultra-alta; terceiro, após a abertura do código do DeepSpec, se a comunidade formará mais modelos de rascunho especializados para tarefas de código, matemática, texto longo e agente com base no DSpark. À medida que o custo do lado da inferência se torna uma variável central na comercialização de grandes modelos, frameworks de aceleração de inferência como o DSpark se tornarão uma parte importante da competição de infraestrutura de IA.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com









