De acordo com pt.wedoany.com-A pilha de software de inferência da NVIDIA (NVIDIA) em sua plataforma Blackwell reduziu o custo por token do modelo DeepSeek V4 em até um quinto do valor original em um mês. À medida que as empresas passam de pilotos de IA para fábricas de IA em produção, as decisões de infraestrutura mudaram do foco em especificações de pico de chip para o custo por token, ou seja, quantos tokens úteis são produzidos por dólar e por watt de energia, atendendo aos objetivos de latência. A pilha de software de inferência da NVIDIA, co-projetada com GPUs, CPUs, redes e sistemas NVIDIA, e aprimorada por um amplo ecossistema de código aberto, continua a melhorar o desempenho do hardware.
Empresas líderes e provedores de inferência já começaram a experimentar o valor agregado da pilha de software de inferência da NVIDIA no Blackwell. A Baseten usa a biblioteca de código aberto NVIDIA TensorRT-LLM para fornecer o serviço DeepSeek V4 Pro em GPUs Blackwell, adequado para cargas de trabalho de inferência, codificação e contexto longo, com um aumento de até 50% na saída de tokens por segundo por meio de otimizações de runtime proprietárias. A Cognition usa o framework de inferência NVIDIA Dynamo para gerenciar GPUs de inferência, fornecendo à sua equipe um caminho pronto para dimensionar cargas de trabalho de aprendizado por reforço sem precisar construir infraestrutura do zero. A Deep Infra usa a pilha de software de inferência da NVIDIA para executar modelos de ponta de código aberto, incluindo o DeepSeek V4, com alto desempenho no Blackwell desde o primeiro dia. A Together AI usa o NVIDIA TensorRT-LLM no Blackwell para ajudar a Cursor a acelerar o caminho da otimização do modelo até o endpoint de produção, a fim de apoiar sua experiência de codificação em tempo real.
Cargas de trabalho tradicionais da web, busca e software como serviço são relativamente previsíveis, mas a IA agente é diferente. Os agentes podem raciocinar, planejar, invocar ferramentas, iniciar subagentes especializados e gerenciar grandes quantidades de contexto em fluxos de trabalho de múltiplas rodadas, transformando uma única solicitação em um problema de computação distribuída que pode envolver centenas de subagentes, milhares de tarefas e vários modelos de linguagem grandes, executando em GPUs, CPUs, DPUs e sistemas de armazenamento. A pilha de software determina se essa complexidade se traduz em poder computacional desperdiçado ou em um custo por token mais baixo.
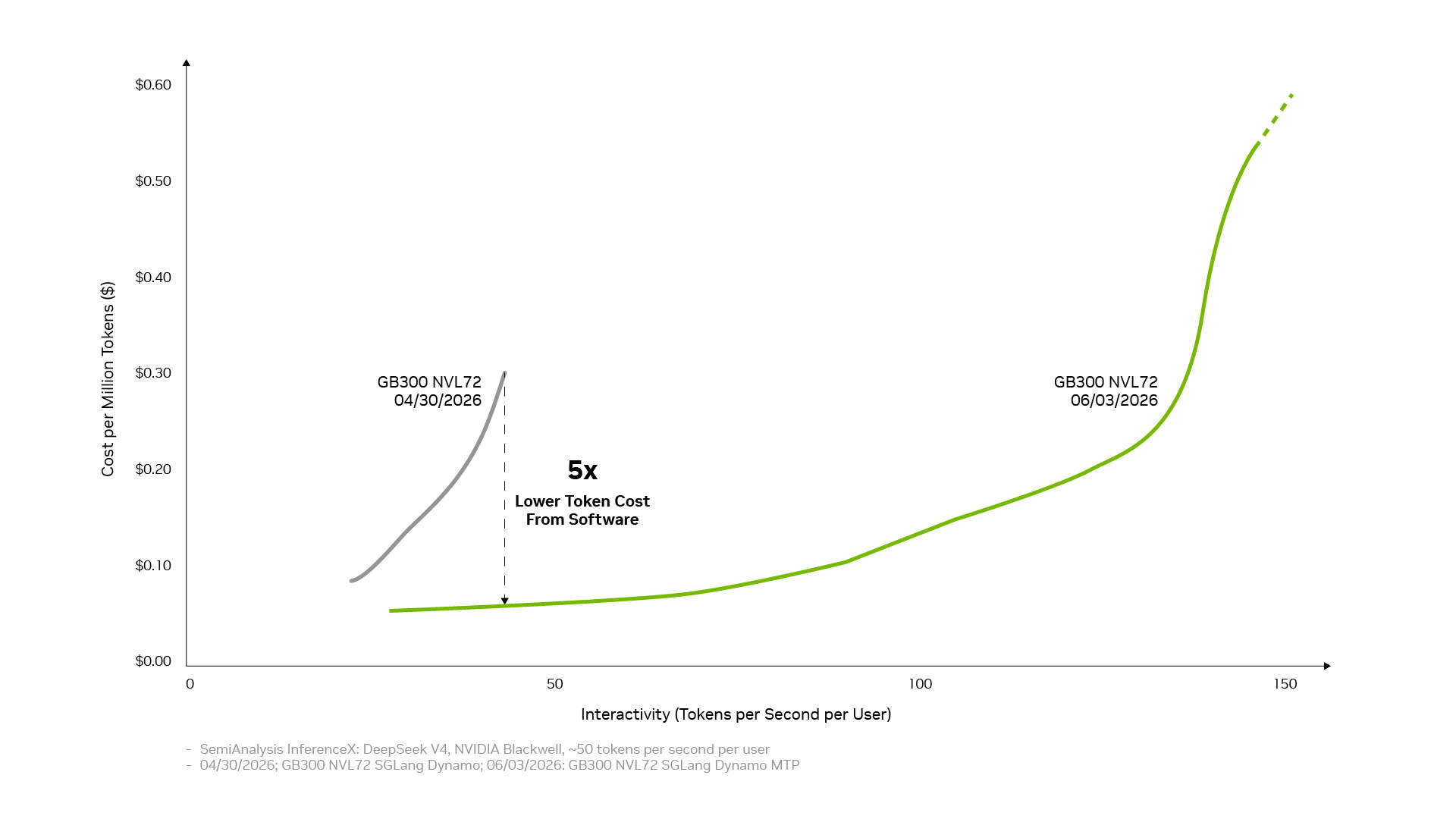
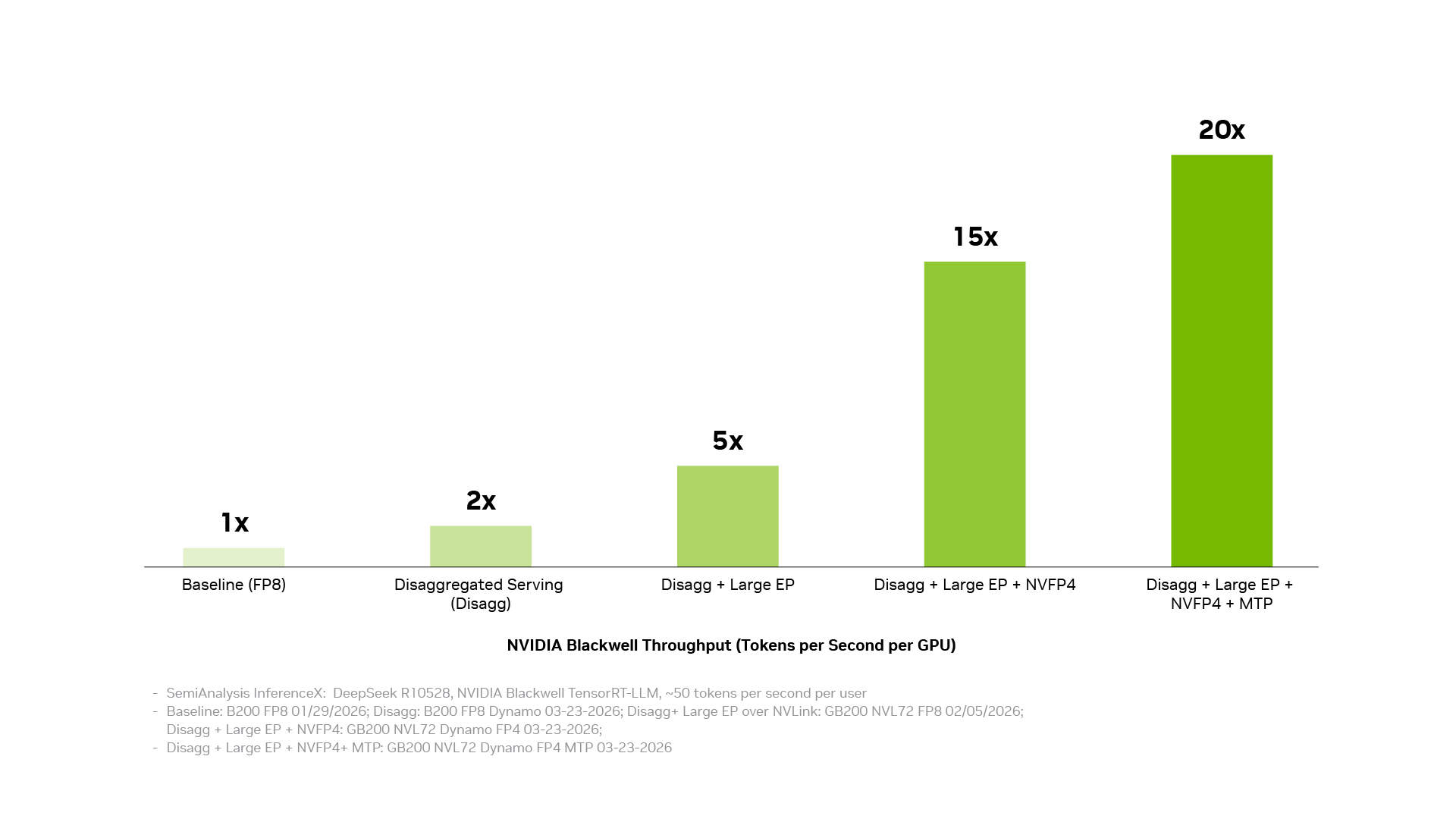
Um custo por token mais baixo vem da transformação de otimizações individuais em desempenho em nível de sistema. A pilha de software de inferência da NVIDIA consegue isso conectando três camadas: a camada de operações de produção coordena serviços distribuídos, orquestração, escalonamento automático e gerenciamento de memória; a camada de aceleração de aplicativos executa modelos com alto desempenho e oferece espaço para ajuste e personalização para desenvolvedores; a camada de acesso à infraestrutura expõe as capacidades das GPUs, redes, memória e sistemas NVIDIA. Quando essas camadas trabalham juntas como um sistema, as otimizações individuais se acumulam. Serviços desacoplados, paralelismo de especialistas em larga escala baseado na tecnologia de interconexão NVIDIA NVLink, precisão NVFP4 e previsão de múltiplos tokens trazem cada um ganhos significativos; combiná-los pode aumentar a taxa de transferência em até 20 vezes.
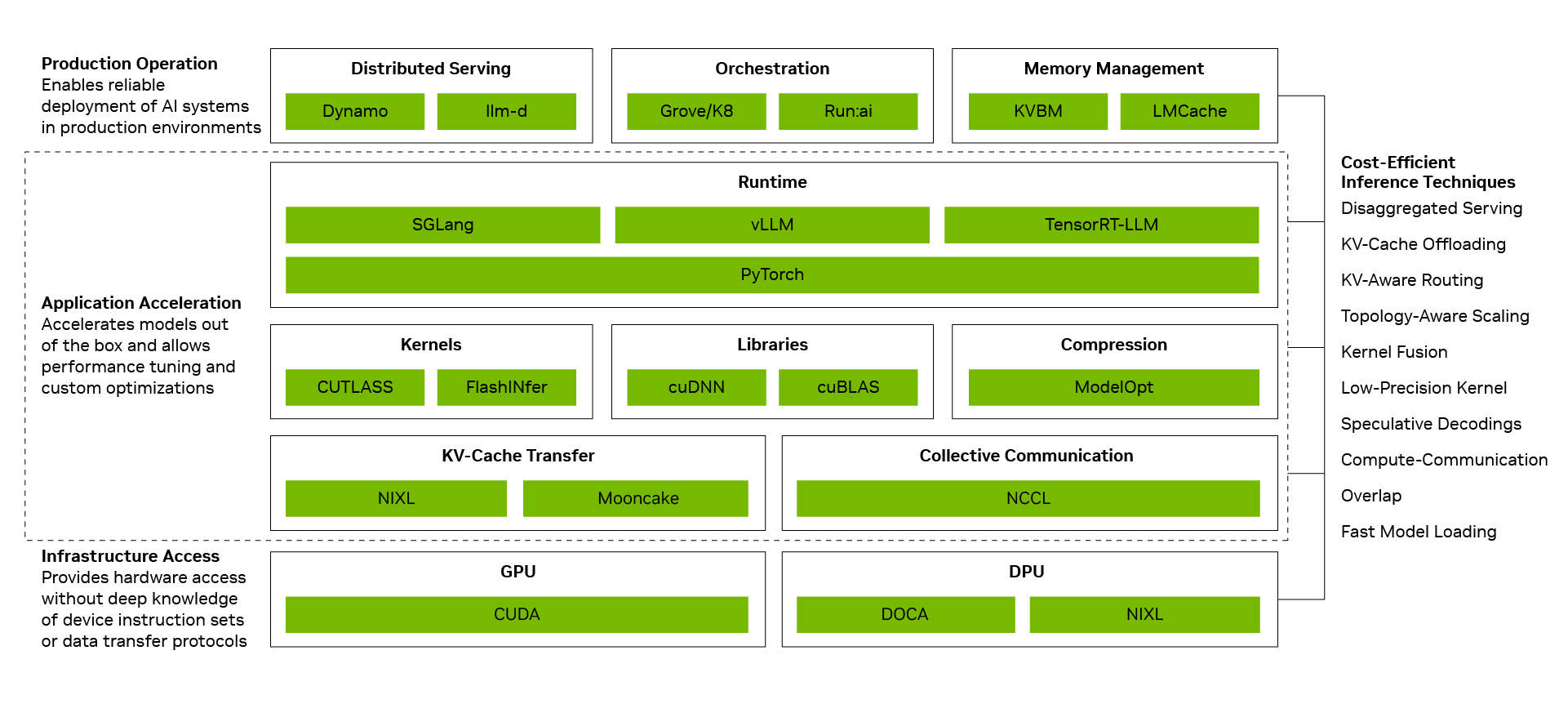
A mesma base de pilha completa também é amplificada pelo ecossistema de código aberto. Muitos frameworks e projetos de inferência de IA de código aberto amplamente usados hoje são construídos nativamente sobre o NVIDIA CUDA. O PyTorch é um exemplo típico; lançado em 2016, ele suporta nativamente o CUDA e co-evoluiu com a arquitetura NVIDIA. Quando tecnologias inovadoras como decodificação especulativa DFlash ou FastVideo são implementadas no PyTorch, elas podem ser executadas imediatamente no NVIDIA. Quando modelos de ponta de código aberto como o DeepSeek V4 são lançados, frameworks de inferência líderes como vLLM e SGLang podem fornecer soluções de implantação para a arquitetura NVIDIA Blackwell no primeiro dia. É por isso que o desempenho do DeepSeek V4 no Blackwell melhorou em até 5 vezes em um mês através dos frameworks vLLM e SGLang, reduzindo o custo por token para cerca de um quinto.
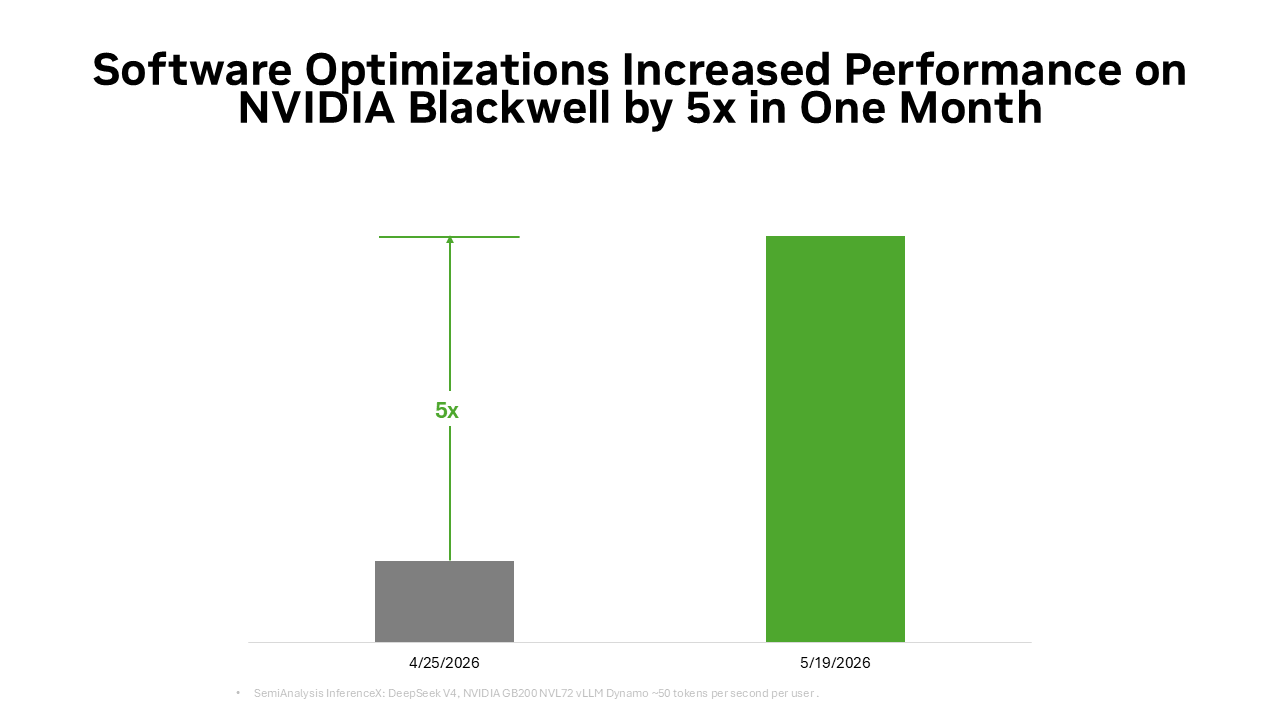
Este é o volante de código aberto: cada vez mais desenvolvedores otimizam caminhos de inferência baseados em CUDA, cada vez mais implantações de produção alimentam o ecossistema, e cada melhoria de software aumenta a quantidade de tokens de saída, ao mesmo tempo que reduz o custo por token.