
De acordo com pt.wedoany.com-A Artificial Analysis lançou o AgentPerf, o primeiro benchmark de IA autônoma do setor, oferecendo a desenvolvedores, empresas e provedores de infraestrutura um método padronizado para comparar sistemas de IA autônoma. Os resultados da primeira rodada de testes mostram que a plataforma NVIDIA Blackwell Ultra NVL72 apresentou desempenho líder em cargas de trabalho de IA autônoma, suportando 20 vezes mais agentes por megawatt em comparação com o sistema NVIDIA Hopper.

A carga de trabalho da IA autônoma difere fundamentalmente da IA conversacional. Uma única conversa é como uma corrida de velocidade, exigindo apenas uma chamada de modelo de linguagem grande (LLM) e uma resposta. Já um agente é mais como uma corrida de revezamento, dividindo um objetivo em várias etapas e continuando até que a tarefa seja concluída.
Esse padrão pode resultar em dezenas a centenas de chamadas de LLM encadeadas, onde cada chamada passa um contexto crescente para a próxima, e em cada transição são realizadas chamadas de ferramentas, como compilação e execução de código, pesquisa em banco de dados e navegação na web. A complexidade não é aditiva, mas multiplicativa.
Essa diferença é crucial para a medição de desempenho. Os benchmarks de inferência de IA existentes medem chamadas únicas de LLM, ou seja, a velocidade de resposta do LLM a uma única solicitação e quantas solicitações o sistema pode processar simultaneamente. Eles não foram projetados para cargas de trabalho autônomas, pois as chamadas encadeadas de LLM, a latência das chamadas de ferramentas e o contexto crescente exercem pressões sobre o sistema de computação acelerada que são completamente diferentes das de uma única chamada de LLM.
Para empresas que constroem e implantam agentes em larga escala, é essencial entender a velocidade de resposta dos agentes, quantos podem ser implantados simultaneamente e a quantidade de trabalho útil que a infraestrutura de IA pode realizar por dólar investido e por watt de energia consumida.
Na primeira rodada de testes, o AgentPerf usou o DeepSeek V4 Pro, um grande modelo de especialistas mistos que representa a categoria de modelos de ponta atualmente usados para impulsionar os agentes mais poderosos, para medir o desempenho autônomo. Nessa carga de trabalho, o NVIDIA GB300 NVL72 alcançou o maior desempenho no benchmark, suportando 20 vezes mais agentes por megawatt em comparação com o sistema NVIDIA HGX H200.
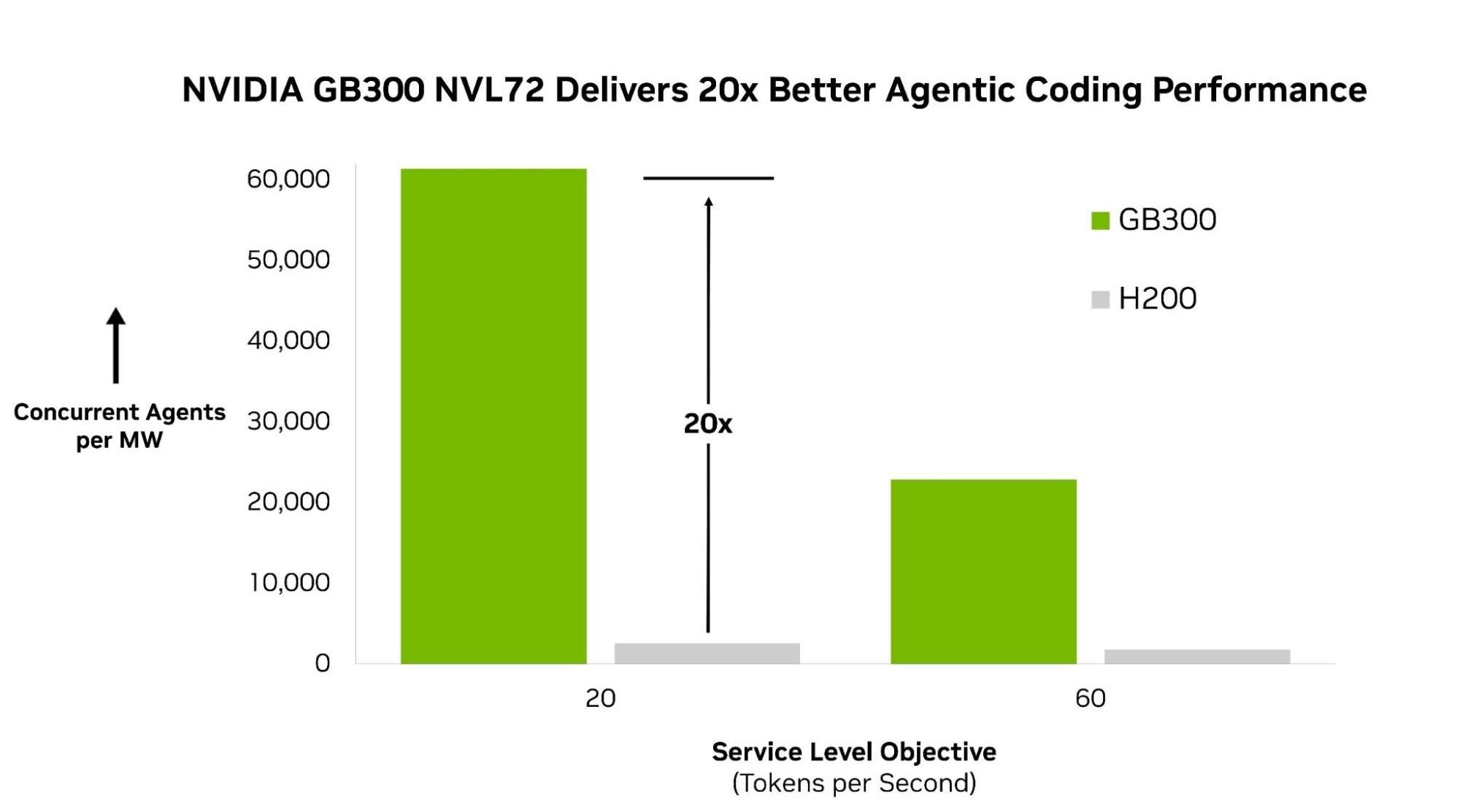
Essa vantagem de desempenho decorre de um design de co-otimização de pilha completa. O GB300 NVL72 conecta 72 GPUs em um sistema em nível de rack, permitindo que grandes modelos MoE, como o DeepSeek V4 Pro, sejam executados de forma eficiente em distribuição em larga escala. Os núcleos CUDA aceleram ainda mais a sobreposição de comunicação e computação, de modo que o custo da coordenação entre especialistas é absorvido, em vez de aumentar a latência. À medida que o número de sessões de agentes concorrentes aumenta, o NVIDIA TensorRT LLM mantém a eficiência, separando o processamento de entrada da geração de saída, permitindo a otimização independente de cada etapa. Esses resultados são baseados em uma metodologia de benchmark construída do zero para refletir como a IA autônoma opera na prática em produção.
O AgentPerf é construído com base em trajetórias reais de agentes de codificação. Os agentes recebem tarefas, leem arquivos, escrevem e editam código, executam comandos e iteram com base nos resultados, com todos os dados provenientes de repositórios de código público reais em mais de 12 linguagens de programação. Os comprimentos de sequência longa, os padrões de chamada de ferramentas e as latências representam fluxos de trabalho de codificação do mundo real. O AgentPerf mede quantas dessas tarefas autônomas uma plataforma pode suportar simultaneamente, enquanto atende a limites de desempenho predefinidos, como capacidade de resposta e taxa de tokens de saída. As chamadas de ferramentas não são realmente executadas, mas simuladas usando tempos de processamento de CPU representativos, de modo que as diferenças nos resultados reflitam apenas o impacto do desempenho da computação acelerada. Os resultados podem ser diretamente traduzidos em decisões de infraestrutura: quantas tarefas autônomas concorrentes podem ser executadas por acelerador e por megawatt de energia.
Provedores de inferência líderes, incluindo Baseten, DeepInfra e Together AI, já estão atendendo cargas de trabalho autônomas em modelos de ponta, como o DeepSeek V4 Pro, no NVIDIA Blackwell. A Together AI fornece inferência em tempo real para o Cursor, uma plataforma de codificação autônoma baseada em IA, no NVIDIA Blackwell. Os agentes do Cursor depuram problemas, geram funcionalidades e realizam refatorações enquanto os desenvolvedores continuam trabalhando. A DeepInfra oferece suporte ao Pam.ai, uma plataforma de força de trabalho de IA para concessionárias de automóveis, que implanta agentes inteiramente no NVIDIA Blackwell para agendar compromissos de serviço, atender chamadas e realizar campanhas de vendas externas. À medida que a NVIDIA e o ecossistema de código aberto continuam a otimizar o software de inferência, o desempenho e a eficiência das cargas de trabalho autônomas continuarão a melhorar. A arquitetura NVIDIA Vera Rubin já está em produção total, trazendo a próxima geração de capacidade de infraestrutura para atender à crescente demanda por IA autônoma em escala. Mais detalhes sobre a metodologia do AgentPerf e a otimização de pilha completa podem ser encontrados no blog técnico relacionado.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com









