
De acordo com pt.wedoany.com-Pesquisadores do IMDEA Software Institute, Nokia Bell Labs, Universidade Complutense de Madrid, Universidade Aalto e Quobly desenvolveram uma arquitetura de hardware baseada em FPGA para decodificação em tempo real de códigos LDPC quânticos. O design, publicado no ArXiv, gerencia matrizes de erros correlacionados por meio de um layout estrutural, otimizando latência, área física e consumo de energia, resolvendo o gargalo de processamento clássico que desafia a expansão física da camada de correção quântica de erros. A arquitetura utiliza ciclos direcionados de reutilização de recursos, em vez de paralelização ilimitada de hardware, para lidar com dependências complexas de síndromes de múltiplos qubits.
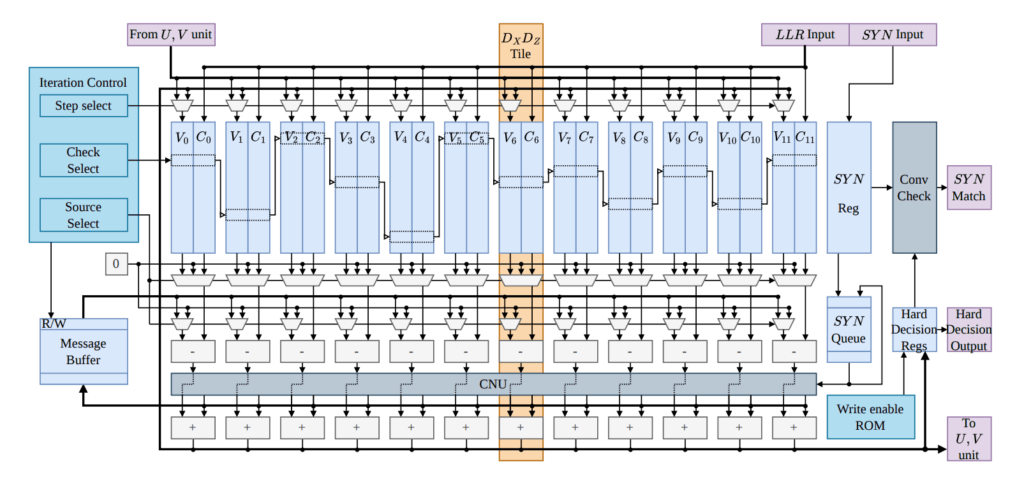
O layout interno do decodificador mapeia-se diretamente para um framework especializado de Reconstrução e Reconexão de Grafos Aumentados (GARI). Rotinas padrão de decodificação geralmente processam coordenadas de erro X e Z espaciais de forma independente, reduzindo a fidelidade de rastreamento quando parâmetros de fase e inversão de bits são vinculados por falhas Y combinadas. A transformação GARI altera a matriz do modelo de erro do detector subjacente, separando variáveis correlacionadas e eliminando ciclos curtos de 4 envolvendo erros Y, substituindo o grafo emaranhado por dependências estruturadas de coordenadas U e V. Essa reconstrução algébrica permite que o hardware distribua a tarefa de decodificação conjunta em caminhos de execução desacoplados, suprimindo correlações de mensagens prejudiciais enquanto mantém a troca iterativa de informações entre domínios de erro.
Para executar a matriz reconstruída, a arquitetura divide as tarefas de processamento em um núcleo de Propagação de Crenças (BP) e um módulo de rastreamento paralelizado. As matrizes principais DX e DZ são roteadas por uma unidade BP baseada em memória e com escalonamento serial, que atualiza sequencialmente os parâmetros de cálculo de acordo com a regra de soma mínima normalizada. As estruturas de verificação independentes das matrizes U e V são paralelizadas em tiles de hardware separados, processando em intervalos sincronizados com o núcleo serial. A interconexão modular cruzada opera estágios de ordenação por base binária como um roteador pipeline N-para-N, contornando a lógica clássica explícita do controlador e prevenindo congestionamento de roteamento e paradas no barramento de dados.
A implementação de hardware foi avaliada no FPGA AMD VCU19P e mapeada para a estrutura FPGA VU29P, para decodificar o código bicíclico [[144,12,12]] dentro de uma janela de 12 rodadas consecutivas de medição de síndrome. A arquitetura aplica restrições de quantização numérica, limitando as Razões de Verossimilhança Logarítmica (LLR) de entrada a 6 bits, mensagens de nós de verificação a 8 bits e valores de nós de variáveis a 10 bits, enquanto aproxima a precisão numérica do modelo clássico de rastreamento em ponto flutuante. Operando a aproximadamente 274 MHz por meio de portas AXI-Stream, o ciclo de execução em pipeline fornece uma latência média de decodificação de 596 nanossegundos por rodada, atendendo às restrições de decodificação em tempo real sob distribuições de ruído correlacionadas realistas de hardware.
Um único núcleo ocupa uma área limitada, incluindo 7,5% do total de LUTs lógicas, 3,5% dos registradores e 26% dos elementos BRAM internos, podendo ser parcialmente mapeado para blocos URAM para reduzir a pressão de memória. Essa eficiência de recursos permite que três decodificadores em configuração combinada operem simultaneamente em uma única placa FPGA VCU19P. Uma combinação completa de rastreamento com 24 decodificadores concorrentes pode ser implantada em oito dispositivos de hardware físicos, em vez das 48 placas necessárias por uma arquitetura alternativa totalmente paralelizada.
A alocação detalhada de silício, a derivação da transformação de matriz e os benchmarks de latência de roteamento podem ser consultados no preprint completo disponível no arXiv.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com









