
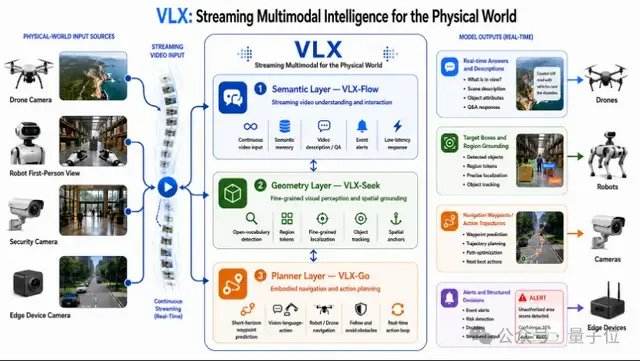
De acordo com pt.wedoany.com-A empresa de Inteligência Artificial de Hangzhou, Om AI, lançou a série VLX, o primeiro modelo multimodal de fluxo contínuo em dispositivo do mundo voltado para o mundo físico. A série inclui três modelos, que serão lançados em três dias: o VLX-Flow é responsável pela percepção contínua em tempo real, permitindo que o vídeo flua como água, com o modelo observando, pensando e atualizando o estado do mundo em tempo real; o VLX-Seek é responsável pelo posicionamento preciso, passando de "ver" para "enxergar claramente", localizando rapidamente o alvo; e o VLX-Go é responsável pela tomada de decisão de ação, convertendo os resultados da percepção e do posicionamento em ações reais, definindo a direção do movimento e os passos operacionais.
A conexão desses três modelos forma um ciclo completo de capacidade do modelo multimodal, desde a percepção contínua, passando pelo posicionamento preciso, até a tomada de decisão de ação. Seu design nativo para dispositivo permite que o modelo seja executado diretamente em dispositivos como celulares, drones e robôs.
A Om AI não é novata na área de linguagem visual. No ano passado, a empresa lançou o VLM-R1, o primeiro projeto de código aberto do mundo a introduzir o paradigma de aprendizado por reforço do DeepSeek R1 em modelos de linguagem visual. Em 12 horas, o projeto recebeu mais de 2000 estrelas no GitHub, alcançou o topo da lista global de tendências do GitHub em 48 horas e, até agora, acumulou mais de 6000 estrelas.
A série VLX foi projetada em torno de duas palavras-chave: dispositivo e multimodalidade de fluxo contínuo. A chamada multimodalidade de fluxo contínuo refere-se à capacidade da IA de perceber o ambiente de forma contínua e em tempo real no mundo físico, formando uma cadeia de capacidade completa, desde a percepção até o posicionamento preciso e a ação. Isso difere da multimodalidade de fluxo contínuo em assistentes de voz, que enfatiza a interação em tempo real entre humanos e IA. O VLX foca na observação contínua, julgamento e condução de ações da IA no mundo físico, realizando a transição de "ver imagens" para "fazer coisas". Com o rápido desenvolvimento de áreas como inteligência incorporada, inteligência espacial e geração de vídeo, os modelos de linguagem visual não são mais apenas módulos de capacidade de modelos de linguagem, mas estão gradualmente se tornando uma nova geração de infraestrutura para compreensão espacial, compreensão de vídeo e até mesmo planejamento de ações. Dados da CVPR deste ano mostram que a proporção de artigos sobre modelos de linguagem visual e multimodalidade cresceu de 4,9% no ano passado para 10,6%, tornando-se uma das áreas de pesquisa de crescimento mais rápido nos últimos anos, com percepção em tempo real e posicionamento sendo as duas palavras-chave mais notáveis.
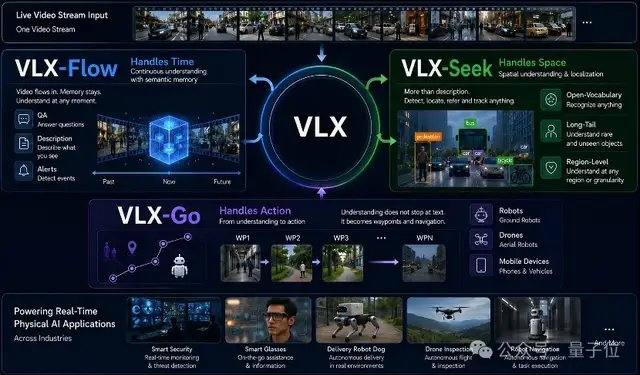
O VLX-Flow é responsável pela percepção contínua. No mundo real, os objetos estão sempre em movimento, o ambiente muda constantemente, as perspectivas mudam com frequência, e uma observação única é insuficiente para lidar com ambientes dinâmicos, abertos e em constante mudança. Modelos de vídeo tradicionais geralmente dividem o vídeo inteiro em quadros e os enviam de uma só vez para compreensão offline. Vídeos longos não apenas aumentam drasticamente o custo computacional, mas também correm o risco de perder informações anteriores. O Flow adota processamento contínuo, onde as imagens fluem continuamente como água. Utilizando codificação incremental e um mecanismo de cache, ele atualiza continuamente o estado visual sem precisar recalcular o histórico repetidamente ou perder a memória devido ao aumento do vídeo. Tecnicamente, o Flow usa Attention Linear em vez de Attention padrão, combinado com um mecanismo de memória de dois níveis, permitindo que o fluxo de vídeo entre continuamente no modelo sem causar explosão de memória devido ao crescimento do contexto.

O VLX-Seek é responsável pela percepção refinada. Embora muitos modelos de linguagem visual de uso geral sejam bons em compreensão semântica de alto nível, eles têm desempenho limitado em tarefas como posicionamento preciso, detecção de vocabulário aberto e localização refinada (Grounding). Métodos tradicionais adotam uma abordagem autorregressiva, prevendo a posição do alvo coordenada por coordenada, o que é lento e propenso a erros. O Seek muda essa abordagem: em vez de adivinhar coordenadas, ele primeiro gera regiões candidatas e depois realiza a recuperação e correspondência, transformando o processo de posicionamento em uma seleção de regiões. Especificamente, o Seek usa Region Token em vez da geração tradicional de coordenadas, mantendo a capacidade de reconhecimento enquanto reduz significativamente o tamanho do modelo e o custo de implantação em dispositivo. Essa abordagem é mais adequada para tarefas de percepção visual, permitindo que, mesmo com um modelo menor, mantenha um desempenho estável em tarefas como detecção de vocabulário aberto, localização refinada e rastreamento em tempo real.

O VLX-Go é responsável pela ação. Modelos de linguagem visual tradicionais, mesmo sabendo que o alvo está à esquerda e à frente, geralmente se limitam a responder textualmente. Para realmente se mover, desviar de obstáculos e seguir o alvo continuamente, ainda é necessário um sistema de controle adicional. O Go recebe como entrada vídeo monocular, memória visual histórica e instruções em linguagem natural, processando-os diretamente em waypoints de curto prazo executáveis por robôs, prevendo como o movimento deve ser nos próximos momentos, em vez de apenas fornecer sugestões textuais. O Go combina aprendizado de trajetória offline com aprendizado por reforço online, corrigindo continuamente as estratégias de movimento em um loop fechado de simulação, permitindo que o robô ajuste continuamente a trajetória com base no feedback visual em tempo real, mantendo um desempenho estável em tarefas como seguir alvos, navegação e desvio dinâmico de obstáculos. Para atender às necessidades de controle em tempo real em dispositivo, o Go adota um esquema leve de previsão de waypoints de curto prazo, usando apenas 0,6B parâmetros para realizar o planejamento de movimento em tempo real.
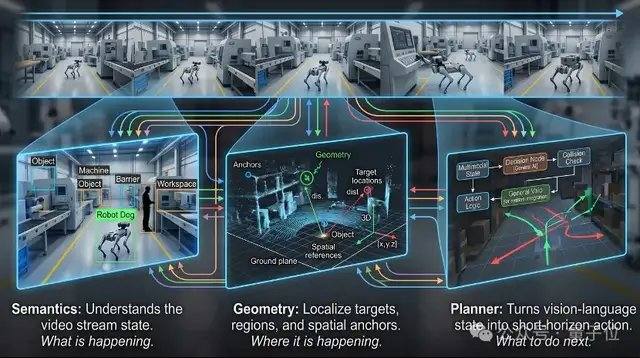
Os três modelos, Flow, Seek e Go, não são independentes entre si, mas compartilham a mesma base, colaborando de ponta a ponta no mesmo fluxo de vídeo. Da percepção contínua ao posicionamento preciso e à tomada de decisão de ação, os três juntos formam uma cadeia de capacidade completa do VLX voltada para o mundo físico.
Para dispositivos do mundo físico, como robôs, drones e câmeras, a implantação em dispositivo é um pré-requisito para a aplicação real do modelo. Embora muitos modelos multimodais em nuvem já sejam poderosos o suficiente, eles não são naturalmente adequados para cenários robóticos e incorporados, pois o mundo real é contínuo, dinâmico e com recursos limitados. A abordagem comum da indústria é primeiro treinar o maior modelo possível e depois comprimi-lo para execução em dispositivo por meio de quantização, destilação, etc. O VLX escolheu um caminho diferente, redesenhando todo o sistema desde o início com base nas restrições computacionais do dispositivo. A arquitetura do modelo, o método de inferência e o pipeline de implantação são todos projetados em torno de fluxos de vídeo em tempo real e dispositivos.
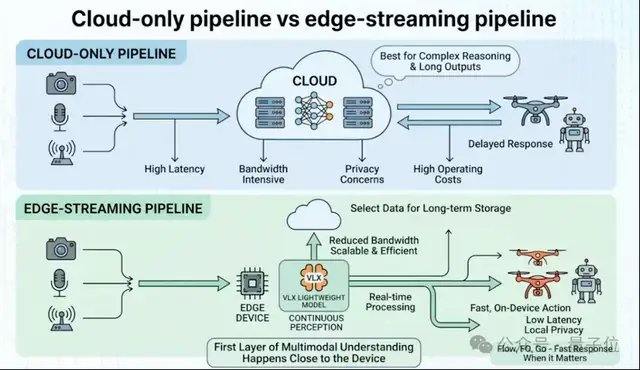
Os dados mostram que o VLX-Flow leva apenas 0,06 segundos para processar um único fluxo de vídeo, enquanto gerencia de forma estável múltiplos fluxos de vídeo simultaneamente; o VLX-Go, com aproximadamente um décimo do tamanho dos parâmetros, alcança desempenho de navegação superior ao de modelos maiores; o VLX-Seek, com um modelo de nível 3B, atinge ou até supera o efeito de modelos de uso geral maiores em tarefas como detecção de objetos.

A Om AI é uma empresa de inteligência artificial de Hangzhou. O fundador e CEO, Zhao Tiancheng, possui doutorado em Ciência da Computação pela CMU e é vencedor do Prêmio de Progresso Científico e Tecnológico em Inteligência Artificial Wu Wenjun. A equipe é composta por membros da CMU, Tsinghua, Zhejiang University, Microsoft, Alibaba Cloud, entre outras instituições, com mais de 50 artigos em conferências de ponta e mais de 50 patentes de invenção. Em 2022, a Om AI recebeu a primeira certificação de modelo multimodal do Ministério da Indústria e Tecnologia da Informação da China. O VLX lançado desta vez é o resultado mais recente da empresa em direção ao objetivo de percepção contínua, posicionamento preciso e ação real.











