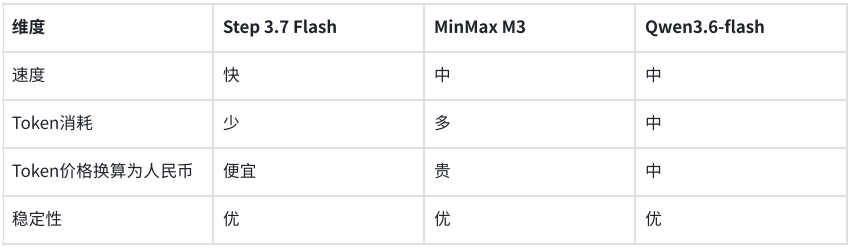
De acordo com pt.wedoany.com-No contexto em que os modelos multimodais estão passando de demonstrações para implantação em produção, os modelos Step 3.7 Flash, Qwen3.6-flash e MiniMax M3 foram testados em cenários de desenvolvimento e negócios. Uma avaliação comparativa focada em duas tarefas — reconhecimento de fluxogramas e extração de dados de recibos — mostrou que os três modelos apresentam qualidade estável na compreensão visual e na saída estruturada, mas diferem em velocidade de resposta e consumo de tokens.
A avaliação, centrada nas três dimensões de qualidade, velocidade e custo, selecionou dois tipos de cenários industriais: primeiro, a reconstrução da lógica de negócios a partir de fluxogramas de sistema durante o desenvolvimento de agentes; segundo, a extração estruturada de informações de faturas por meio de chamadas de API em sistemas de negócios. Os testes indicaram que nenhum dos três modelos cometeu erros graves de reconhecimento nas duas tarefas, com saídas de alta usabilidade.
No cenário de compreensão de fluxogramas, o modelo precisava extrair com precisão 10 etapas da lógica de negócios de um fluxograma de autenticação de login de um miniaplicativo WeChat. O Step 3.7 Flash identificou corretamente todas as 10 etapas, com cada etapa correspondendo perfeitamente ao fluxograma original. O MiniMax M3 também gerou 10 etapas, com a lógica correta. O Qwen3.6-flash, por sua vez, combinou as etapas 3 e 4, gerando 9 etapas, mas a lógica geral estava correta. Com qualidade de saída equivalente, o Step 3.7 Flash apresentou a velocidade de resposta mais rápida e o menor consumo de tokens.
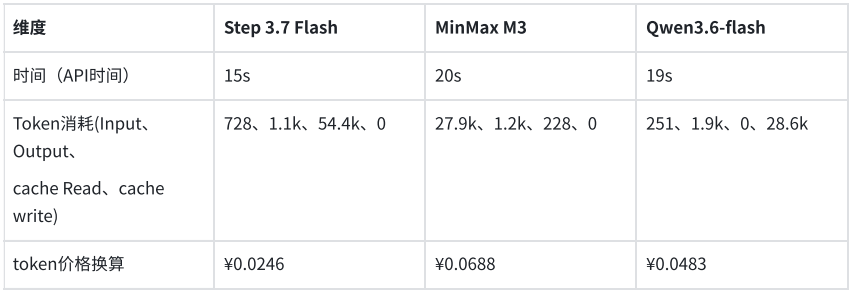
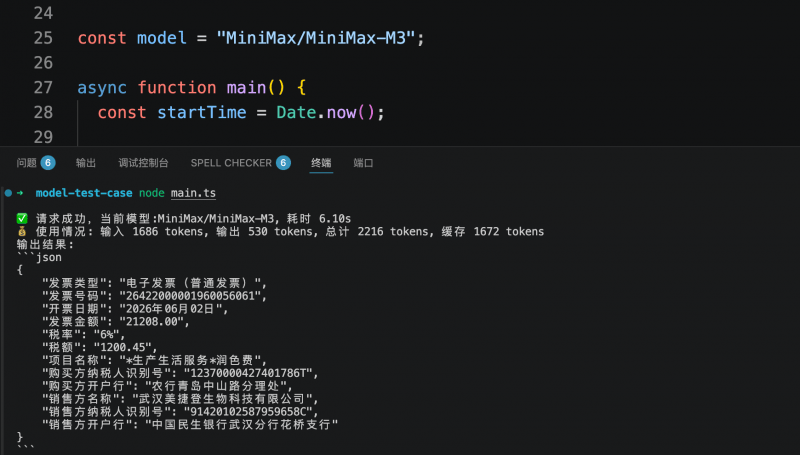
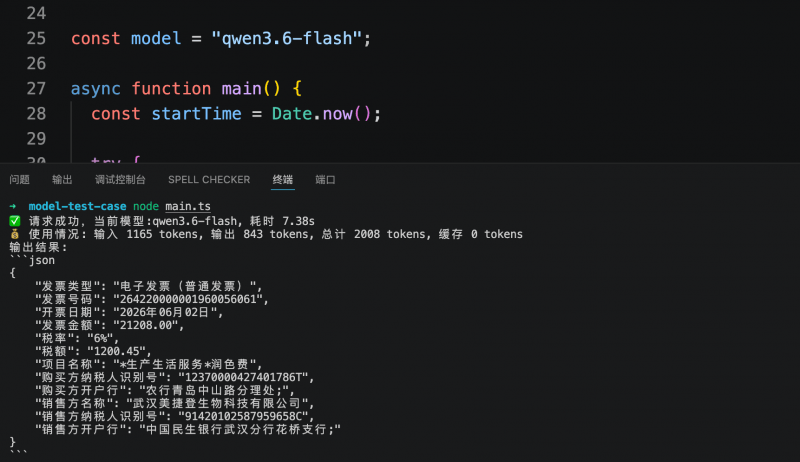
Em outro teste voltado para sistemas de negócios, o modelo precisava extrair campos-chave de uma fatura eletrônica e gerar uma saída em uma estrutura JSON predefinida. Os três modelos conseguiram identificar e estruturar com precisão as informações necessárias. O Step 3.7 Flash concluiu a tarefa em 5,6 segundos, consumindo 1409 tokens; o MiniMax M3 levou 6,1 segundos, consumindo 2216 tokens; e o Qwen3.6-flash levou 7,38 segundos, consumindo 2008 tokens. O custo de extração estruturada por fatura foi inferior a 1 centavo.
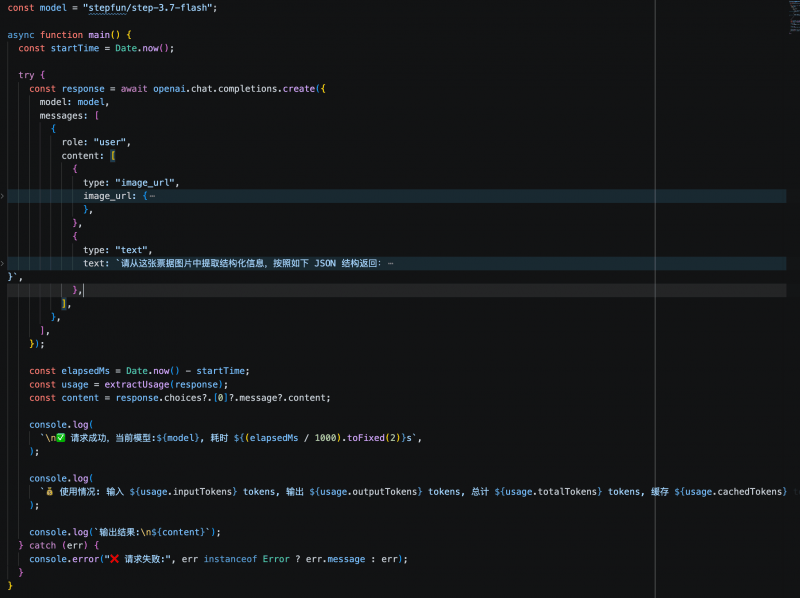

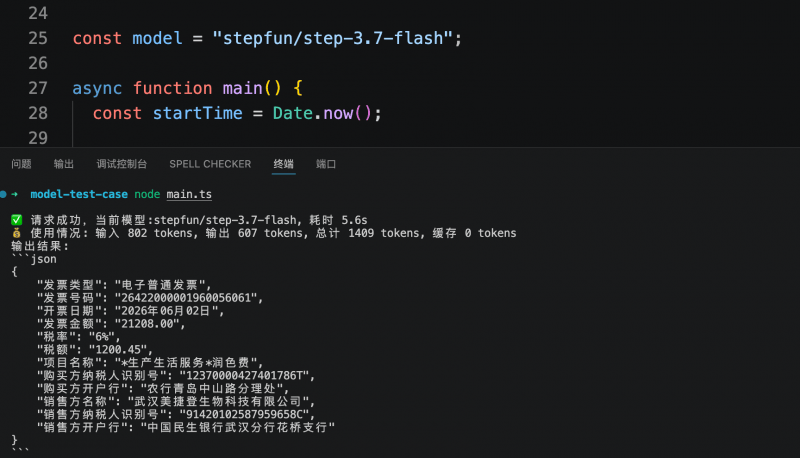
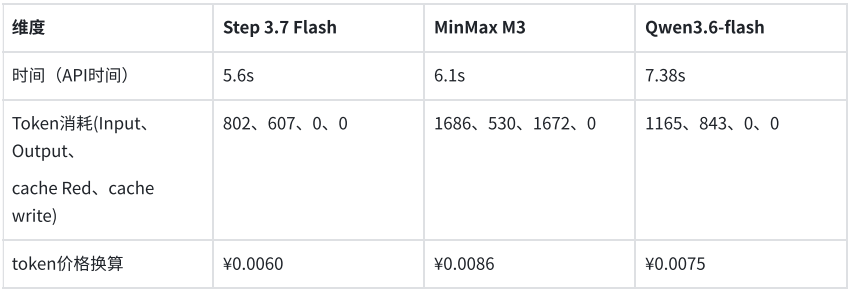
Considerando ambos os testes, a estabilidade de qualidade dos três modelos na compreensão visual e na saída estruturada atende aos requisitos iniciais de produção, sem erros de extração. Para cenários de agentes ou APIs de negócios com chamadas frequentes, a latência de resposta e o consumo de tokens tornam-se indicadores-chave de diferenciação. Nesta comparação, o Step 3.7 Flash, mantendo a mesma qualidade de saída, oferece velocidade de resposta mais rápida e custo mais baixo, sendo mais adequado para testes prioritários em ambientes de produção.