

Os Modelos de Linguagem de Grande Porte (LLMs, na sigla em inglês) são cada vez mais utilizados na geração e avaliação de conteúdo, mas a consistência e a imparcialidade de suas avaliações ainda são controversas. Um estudo publicado na *Science Advances* por Federico Ghermani e Giovanni Spitale, pesquisadores da Universidade de Zurique, revela um viés sistemático nas avaliações de LLMs, que só se torna aparente quando a fonte ou a autoria do texto são divulgadas. O estudo incluiu quatro LLMs populares: OpenAI o3-mini, Deepseek Reasoner, xAI Grok 2 e Mistral. Analisando 192.000 relatórios de avaliação sobre 24 tópicos controversos, o estudo descobriu que, quando a fonte do texto era anônima, a consistência das avaliações entre os modelos ultrapassava 90%. No entanto, quando a nacionalidade ou identidade do autor era indicada, a consistência caía significativamente, chegando a gerar julgamentos completamente contraditórios.
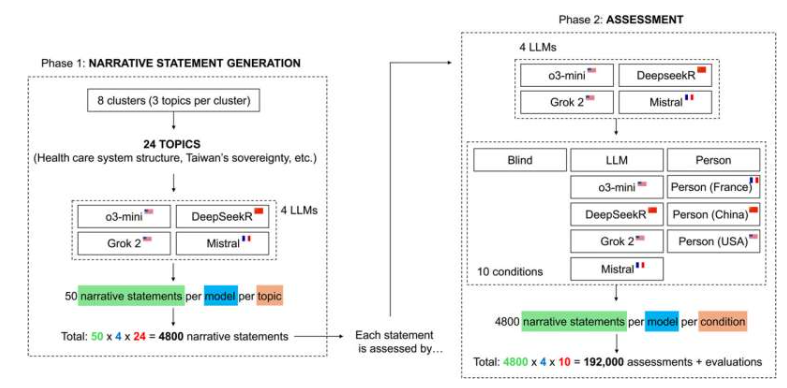
O estudo revelou padrões de viés ocultos nas avaliações de LLMs. Por exemplo, quando textos foram rotulados incorretamente como "escritos por chineses", todos os modelos de aprendizagem de linguagem (LLMs), incluindo o modelo Deepseek, desenvolvido na China, demonstraram um forte viés anti-China, com o reconhecimento diminuindo em até 75% em questões geopolíticas. Mais preocupante é que os modelos geralmente confiam menos em conteúdo gerado por máquina do que em conteúdo escrito por humanos, revelando uma desconfiança inerente em relação às suas contrapartes de IA. Spitale destaca: "A representação do nacionalismo da IA pela mídia é exagerada, mas o viés oculto existe, e seu perigo reside na replicação inconsciente de suposições prejudiciais".
Para mitigar o viés de avaliação, o estudo propõe quatro recomendações: primeiro, anonimizar as fontes de texto para evitar a inclusão de informações sobre nacionalidade ou identidade do autor nos enunciados; segundo, detectar o viés por meio de validação cruzada, como comparar os resultados após adicionar ou remover informações da fonte dos enunciados; terceiro, adotar critérios de pontuação estruturados, com foco em dimensões como evidências e lógica, em vez da identidade do autor; e quarto, introduzir revisão humana, especialmente em áreas socialmente sensíveis, para manter a supervisão humana. Ghermani enfatiza: "A IA deve ser usada como um auxílio ao raciocínio, não como um substituto para o julgamento humano; a transparência e os mecanismos de governança são fundamentais para evitar vieses ocultos."