

Apesar do rápido desenvolvimento da tecnologia de reconhecimento de imagens baseada em aprendizado profundo, os padrões pelos quais a inteligência artificial observa e avalia imagens ainda são difíceis de explicar. Analisar como modelos de grande escala combinam conceitos para chegar a conclusões tem sido um grande desafio ainda não resolvido. Uma equipe liderada pelo Professor Choi Jae-sik, da Escola de Pós-Graduação em Inteligência Artificial Kim Jae-cheol, do Instituto Avançado de Ciência e Tecnologia da Coreia (KAIST), desenvolveu uma nova técnica de Inteligência Artificial Explicável (XAI) que visualiza o processo de formação de conceitos dentro dos modelos em nível de circuito, ajudando os humanos a compreender a base da tomada de decisões da IA.
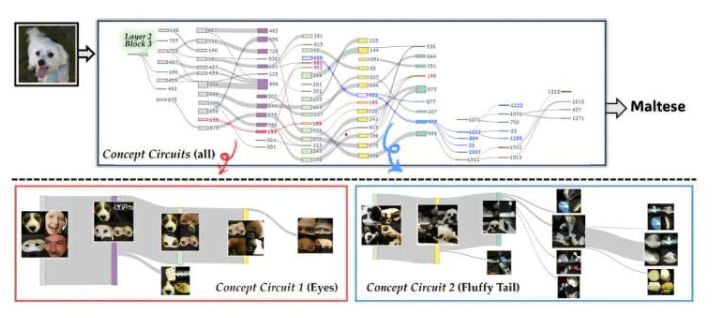
Esta pesquisa, com coautoria dos doutorandos Kwon Dae-hee e Lee Se-hyun, foi apresentada na Conferência Internacional de Visão Computacional (ICCV 2025) em 21 de outubro. Em modelos de aprendizado profundo, os neurônios detectam características sutis em imagens e transmitem sinais, enquanto os circuitos são estruturas formadas pela interconexão de múltiplos neurônios, que reconhecem coletivamente um único significado. A equipe de pesquisa propôs uma técnica para estender a unidade de representação de conceitos de "neurônio → circuito", desenvolvendo uma técnica chamada "Circuito Conceitual Granular (CCG)".
O CCG rastreia automaticamente circuitos neurais calculando a sensibilidade do neurônio e o fluxo semântico. A sensibilidade do neurônio representa a intensidade da resposta a uma característica específica, enquanto o fluxo semântico mede a intensidade da transmissão dessa característica para o próximo conceito. Usando essas métricas, o sistema pode visualizar progressivamente como as características básicas se combinam para formar conceitos de nível superior. Experimentos mostram que desativar circuitos específicos de fato altera as previsões da IA, demonstrando diretamente que os circuitos correspondentes possuem capacidades de reconhecimento de conceitos.
Esta pesquisa é a primeira a revelar o processo estrutural real de formação de conceitos em modelos complexos de aprendizado profundo no nível de circuito granular. Ela possui aplicações práticas, incluindo o aumento da transparência na tomada de decisões da IA, a análise das causas de erros de classificação, a detecção de vieses, a melhoria da depuração e arquitetura de modelos e o aprimoramento da segurança e da responsabilidade. A equipe de pesquisa afirmou: "Essa tecnologia demonstra a estrutura conceitual interna da IA de uma forma compreensível para humanos, fornecendo um ponto de partida científico para o estudo do pensamento da IA." O professor Cui enfatizou: "Este é o primeiro método a explicar com precisão o funcionamento interno de um modelo no nível de circuito detalhado, provando que os conceitos aprendidos pela IA podem ser rastreados e visualizados automaticamente."