
De acordo com pt.wedoany.com-Uma equipe de pesquisadores desenvolveu uma estrutura de treinamento de redes neurais quânticas que reduz o custo do cálculo de gradientes durante o treinamento — um dos principais obstáculos de longa data no campo do aprendizado de máquina quântico.
De acordo com a pesquisa publicada no servidor de pré-impressão arXiv, o método reduz o número de avaliações de circuitos necessárias por etapa de otimização de um crescimento quadrático em relação ao número de qubits para um crescimento apenas logarítmico. Os pesquisadores afirmam que essa melhoria permite o treinamento baseado em gradientes diretamente no computador quântico de íons aprisionados Forte Enterprise da IonQ e permite que apliquem o método a uma tarefa de imputação de dados clinicamente relevante.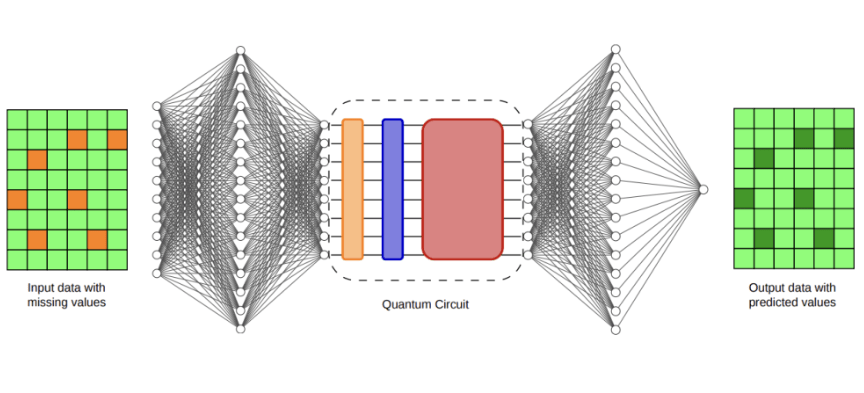
Segundo a equipe, este trabalho aborda um desafio de longa data no aprendizado de máquina quântico. A equipe inclui cientistas da IonQ, Université Paris Cité, Centre Nacional de la Recherche Scientifique (CNRS), QC Ware e Quantum Signals. Redes neurais quânticas (QNNs) são circuitos quânticos com parâmetros ajustáveis, treinados de forma semelhante às redes neurais clássicas. Teoricamente, elas podem oferecer vantagens em certas tarefas de aprendizado; no entanto, treiná-las em hardware quântico real tem se mostrado difícil, pois o cálculo de gradientes geralmente requer a execução repetida de um grande número de circuitos quânticos. Os pesquisadores relatam que esse custo é uma das principais razões pelas quais muitas demonstrações de aprendizado de máquina quântico ainda se limitam a simulações ou experimentos em hardware de escala muito pequena.
A estrutura combina três componentes projetados de forma coesa, incluindo um design de circuito especializado, uma estratégia de treinamento camada por camada e uma técnica de cálculo de gradiente paralelo.
O método tradicional de deslocamento de parâmetros, amplamente utilizado para treinar circuitos quânticos, requer avaliações de circuito separadas para parâmetros individuais. À medida que o tamanho do modelo aumenta, o número de avaliações necessárias cresce rapidamente. A nova estrutura evita esse gargalo por meio de três escolhas de design. A primeira é uma arquitetura de circuito chamada rede borboleta (Butterfly network), inspirada na estrutura da Transformada Rápida de Fourier, que organiza operações quânticas em um padrão específico para que a informação se propague por todo o sistema, mantendo o circuito relativamente raso. De acordo com a pesquisa, esse design reduz drasticamente o número de parâmetros treináveis necessários à medida que o sistema escala. A segunda é uma estratégia de treinamento camada por camada, que, em vez de treinar todos os parâmetros da rede neural quântica simultaneamente, primeiro treina blocos de circuito menores e, em seguida, adiciona novas camadas gradualmente, congelando as camadas previamente treinadas ao otimizar as novas. A terceira é uma versão paralelizada da regra de deslocamento de parâmetros. Como as portas dentro de cada camada borboleta atuam em diferentes pares de qubits e comutam entre si, os pesquisadores podem usar um número constante de execuções de circuito para calcular o gradiente de toda a camada, em vez de avaliar cada parâmetro individualmente. Juntas, essas técnicas reduzem substancialmente o número de avaliações de circuitos quânticos necessárias durante o treinamento. Os pesquisadores relatam uma vantagem de escalabilidade por meio de um exemplo: aplicar o método tradicional de deslocamento de parâmetros a um circuito borboleta de 128 qubits exigiria 1792 avaliações de circuito para calcular o gradiente, enquanto seu método requer apenas 28.
Para avaliar a estrutura, os pesquisadores escolheram a imputação de dados clínicos, um problema que vai além dos benchmarks tradicionais da computação quântica. A imputação de dados envolve preencher entradas ausentes em conjuntos de dados. Em registros médicos, informações ausentes são comuns devido a cronogramas de medição inconsistentes, falhas de sensores ou coleta de dados incompleta. Uma imputação precisa pode impactar significativamente os modelos preditivos downstream usados na análise médica. A equipe usou o conjunto de dados MIMIC-III, uma coleção amplamente estudada e desidentificada de registros de unidades de terapia intensiva. Eles introduziram valores ausentes no conjunto de dados e, em seguida, compararam vários métodos para reconstruir as informações faltantes. Os benchmarks incluíram técnicas estatísticas comuns, como imputação pela média e preenchimento com zero, bem como métodos mais complexos, como imputação por k-vizinhos mais próximos, imputação múltipla por equações encadeadas (MICE), MissForest e o modelo Deep MICE baseado em redes neurais. Os pesquisadores avaliaram indiretamente a qualidade da imputação prevendo a sobrevivência dos pacientes e mediram usando a área sob a curva característica de operação do receptor (AUC). Entre os métodos clássicos, o Deep MICE produziu o desempenho médio mais forte, com AUC de 0,7176. O modelo quântico-clássico híbrido treinado em 16 qubits alcançou uma AUC de 0,7147, enquanto o modelo híbrido de 32 qubits alcançou uma AUC de 0,7132, ambos diferindo do principal resultado clássico por alguns milésimos. Embora os modelos quânticos não tenham superado a melhor linha de base clássica, eles apresentaram uma faixa estreita de desempenho e baixa variabilidade entre várias execuções. Os pesquisadores sugerem que essa estabilidade pode indicar um viés indutivo benéfico proporcionado pela arquitetura borboleta estruturada e pelo protocolo de treinamento.
O estudo fornece uma demonstração importante de treinamento diretamente em um computador quântico comercial. Os pesquisadores treinaram a última camada de uma rede neural quântica borboleta de 16 qubits no sistema de íons aprisionados Forte Enterprise da IonQ. Os estágios iniciais do modelo foram treinados em simulação e depois integrados à rede treinada em hardware. Eles compararam três cenários: simulação ideal, simulação com ruído e execução direta em hardware. De acordo com os resultados, as diferenças de desempenho entre os três métodos de treinamento não foram estatisticamente significativas. O modelo treinado em hardware obteve resultados comparáveis aos modelos simulados, mantendo desempenho preditivo semelhante. Os pesquisadores relatam que isso prova que a estrutura de treinamento de escala logarítmica é robusta o suficiente para operar nos níveis atuais de ruído de hardware. Essa descoberta é importante porque muitas demonstrações anteriores de aprendizado de máquina quântico dependiam fortemente de simulações, em vez de processadores quânticos reais, e o ruído do hardware e os longos tempos de treinamento frequentemente tornavam a otimização direta impraticável. A arquitetura de íons aprisionados usada pela IonQ pode ter ajudado; o sistema oferece conectividade total de qubits, permitindo que os circuitos borboleta sejam implementados sem custos significativos de compilação.
A pesquisa também explorou escalas de sistema maiores. Como o treinamento direto com 32 qubits ainda é computacionalmente intensivo, os pesquisadores usaram simulações de rede de estados de produto de matrizes (matrix product states) para treinar camadas quânticas maiores, enquanto a inferência foi executada no hardware da IonQ. O desempenho do modelo híbrido de 32 qubits resultante foi comparável ao de uma rede neural clássica com largura de camada oculta equivalente. Os pesquisadores interpretam isso como evidência de que circuitos quânticos maiores, produzidos pela estrutura camada por camada, ainda são compatíveis com hardware real e podem operar sem degradação mensurável.
O trabalho inclui várias limitações importantes. A pesquisa focou em uma tarefa controlada de imputação como prova de conceito, e não em um fluxo de trabalho médico em escala de produção. Apenas uma coluna de características foi imputada usando o modelo quântico; os demais valores ausentes foram tratados por métodos clássicos. O padrão de dados ausentes também foi gerado usando um modelo de ausência completamente aleatória, enquanto os dados clínicos do mundo real geralmente exibem padrões de ausência mais complexos. Finalmente, o modelo híbrido igualou, mas não superou, a linha de base clássica mais forte. Os resultados demonstram viabilidade e competitividade, não uma vantagem quântica inequívoca. Os pesquisadores também observam que sistemas maiores podem ser necessários antes que vantagens potenciais de desempenho se tornem aparentes. Com base em comparações com arquiteturas de redes neurais clássicas, eles estimam que seriam necessários aproximadamente 128 qubits para igualar a capacidade representacional do modelo clássico mais forte usado no estudo. Ainda assim, os pesquisadores acreditam que o significado da estrutura não reside nos números de desempenho atuais, mas sim em permitir o treinamento escalável em hardware.
A equipe de pesquisa inclui Natansh Mathur, do Institut de Recherche en Informatique Fondamentale (IRIF), um laboratório de pesquisa conjunto do Centre Nacional de la Recherche Scientifique (CNRS) e da Université Paris Cité, bem como da QC Ware, na França. Os coautores Panagiotis Kl. Barkoutsos, Masako Yamada e Martin Roetteler são afiliados à IonQ. A pesquisa também inclui Iordanis Kerenidis, afiliado ao IRIF, CNRS, Université Paris Cité e Quantum Signals.
Este texto foi elaborado por Wedoany. Qualquer citação por IA deve indicar a fonte “Wedoany”. Em caso de infração ou outros problemas, informe-nos prontamente, por favor. O conteúdo será corrigido ou removido. E-mail: news@wedoany.com









